





 , János Szolomájer 2, Nándor Papp 1,3, Gábor K. Tóth 2, Andrea Bodor 1,*
, János Szolomájer 2, Nándor Papp 1,3, Gábor K. Tóth 2, Andrea Bodor 1,*
1 Analytical and BioNMR Laboratory, Institute of Chemistry, Eötvös Loránd University, 1117 Budapest, Hungary
2 Department of Medical Chemistry, University of Szeged, 6720 Szeged, Hungary
3 Hevesy György PhD School of Chemistry, Eötvös Loránd University, 1117 Budapest, Hungary
Abstract
Background: Intrinsically disordered proteins and protein regions
(IDPs/IDRs) are important in diverse biological processes. Lacking a stable
secondary structure, they display an ensemble of conformations. One factor
contributing to this conformational heterogeneity is the proline
cis/trans isomerization. The knowledge and value of a given
cis/trans proline ratio are paramount, as the different conformational
states can be responsible for different biological functions. Nuclear Magnetic
Resonance (NMR) spectroscopy is the only method to characterize the two
co-existing isomers on an atomic level, and only a few works report on these
data. Methods: After collecting the available experimental literature
findings, we conducted a statistical analysis regarding the influence of the
neighboring amino acid types (i
Keywords
- intrinsically disordered proteins
- NMR spectroscopy
- proline
- cis/trans isomerization
- statistical analysis
Despite the lack of a stable secondary structure, intrinsically disordered
proteins/protein regions (IDPs/IDRs) play fundamental roles in many biological
processes. One factor contributing to the hindrance of secondary structure
formation is the high content of proline residues. Proline is the only naturally
occurring amino acid that can exist in two conformations (Fig. 1), as in this
case, the free energy difference between the trans and cis
conformers is lower than in all other non-prolyl bonds (with typical values of 20
kcal/mol) [1]. In proteins, the peptide bonds are predominantly in the
trans-state (
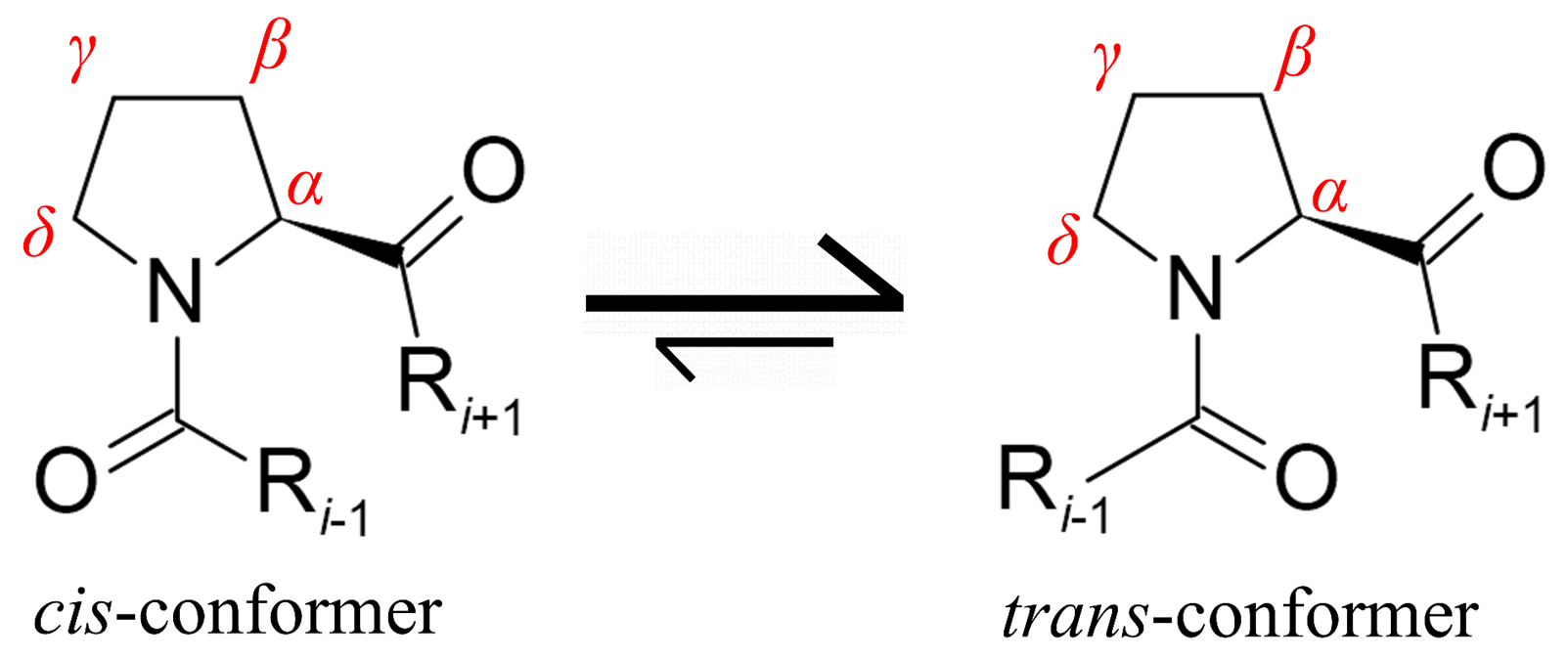 Fig. 1.
Fig. 1.Schematic representation of proline cis-trans isomerization. In proteins, the trans isomer is the predominant form. However, 4–30% of cis-isomers in IDPs can occur depending on the Pro-neighboring sequence. Proline atom numbering is shown in red.
The cis and trans-Pro isomers play key roles in protein–protein interactions as several proteins contain specific polyproline binding domains, such as SRC Homology 3 Domain (SH3), tryptophan-tryptophan domain (WW), ENA-VASP Homology Domain 1 (EVH1), glycine-tyrosine-phenylalanine domain (GYF), and ubiquitin enzyme 2 variant (UEV) [5]. Furthermore, the biological function is associated with the existence of either cis or trans proline conformation and is linked to cancer [6, 7, 8], neurodegenerative diseases [9, 10] as well as physiological processes such as the circadian rhythm regulation [11, 12].
Therefore, it is important to determine the conformation of the proline
residues. However, it is not straightforward to detect and characterize the
isomeric ratio. As IDPs are highly mobile systems, atomic resolution studies
using X-ray crystallography or cryo-EM cannot be used [13]. Therefore, Nuclear Magnetic Resonance (NMR)
spectroscopy is the only method of investigation capable of discerning between
the two conformations. In addition, it is possible to detect several
conformations co-existing in the solution. NMR spectra peak multiplications
indicate this phenomenon. In the trans and cis-Pro isomers, the
chemical environment is different, and the exchange is slow (10
Using 2D
Possible cis-Pro peak assignment methods for proteins are Pro-Ala
mutations [19] or site-specific labeling [20]. Furthermore, the application of
proline analogs has gained popularity [12]. The fluorinated amino acids are
widely utilized analogs for assessment of cis/trans-Pro presence since
As a consequence of these experimental difficulties, there are relatively few
publications regarding the characterization of the cis-Pro isomers in
IDPs. Previous studies showed that the cis-trans proline isomer
ratio depends on the sequence of the Pro neighboring regions in IDPs [22, 23]. In
our earlier study, we performed a statistical analysis using the available
experimental data to determine the effect of the amino acid type of Pro
neighboring residues on forming a cis-Pro conformer [17]. This analysis
was based on 10 IDPs containing 101 Pro neighboring regions (i
It was shown at p = 0.1 significance level that high (
As a continuation of this study, here we propose a more extensive investigation
of the Pro occurrence in IDPs from DisProt database (Database of Protein
Disorder, https://disprot.org/) and further
characterize the amino acid composition of the Pro and Pro-Pro neighborhood [24, 25]. As DisProt does not contain information on the amount of cis-Pro
isomers, we updated and expanded our previous dataset [17] to the i
Amino acid composition of intrinsically disordered proteins was collected from DisProt database (release version 2022_12) and was analyzed using in-house built Python scripts and Microsoft Excel. The DisProt database amino acid composition was determined for the whole dataset (10,544 records) and a filtered dataset (4158 records), from which duplicates based on the sequence and region ID were removed (Supplementary Table 1).
The cis-Pro neighboring sequence preference with proof by NMR
measurements was studied for several IDPs [12, 17, 19, 20, 22, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36]
(Supplementary Table 2). As the dataset has increased since our previous
work, we have updated the results [17]. The current dataset contains 15 IDPs with
167 central i proline environments, and the proline i
The designed peptides (Table 1) were synthesized using solid-phase peptide
synthesis, applying the Fmoc/tBu strategy using a CEM microwave-assisted fully
automated peptide synthesizer. The syntheses were carried out at a 0.25 mmol
synthesis scale using a TentaGel S Ram resin (Rapp Polymere GmbH, Tübingen,
Germany) with a loading of 0.23 mmol/g amino function. The crude peptides were
detached from the solid support using TFA (90%) in the presence of water (5%),
1, 4-dithiothreitol (DTT, 2.5%), and TIS (2.5%). The crude peptides were
purified using a C18 RP-HPLC on a PerfectSil 100 ODS3 5 µm column (250
| Peptide | Sequence | Length | Number of Pro | M |
M |
| I.A | DRGLFPFLGKKK | 12 | 1 | 1404.82 | 1404.57 |
| I.B | DRGLRPFLGKKK | 12 | 1 | 1413.86 | 1414.01 |
| II.A | FFEGFPDKQPRKK | 13 | 2 | 1622.86 | 1623.45 |
| II.B | FFEGFADKQPRKK | 13 | 1 | 1596.84 | 1597.09 |
| II.C | FFEGFPDKQARKK | 13 | 1 | 1596.84 | 1596.96 |
| II.D | FFEGFADKQARKK | 13 | 0 | 1570.83 | 1570.78 |
| III. | EKKGFPEKLKEKLPG | 15 | 2 | 1727.00 | 1727.04 |
Prolines are shown in bold, and mutations for Peptide I.A are highlighted with red and for Peptide II.A with blue.
Typical NMR samples contained 1 mM peptide in 10% D
Resonance assignment and sequential connectivities were determined from
classical 2D homonuclear
Proline, with 7.41% occurrence, is the 5th most frequent amino acid in IDPs
according to DisProt (release version 2022_12) (Fig. 2, Supplementary
Table 1). In order to confirm the amino acid preference, the proline preceding
and succeeding neighboring residue type was collected for the Pro residues and
Pro-Pro motifs (Fig. 2, Supplementary Tables 3,4). Statistical analysis
of these data shows that the distribution of amino acid type in the Pro
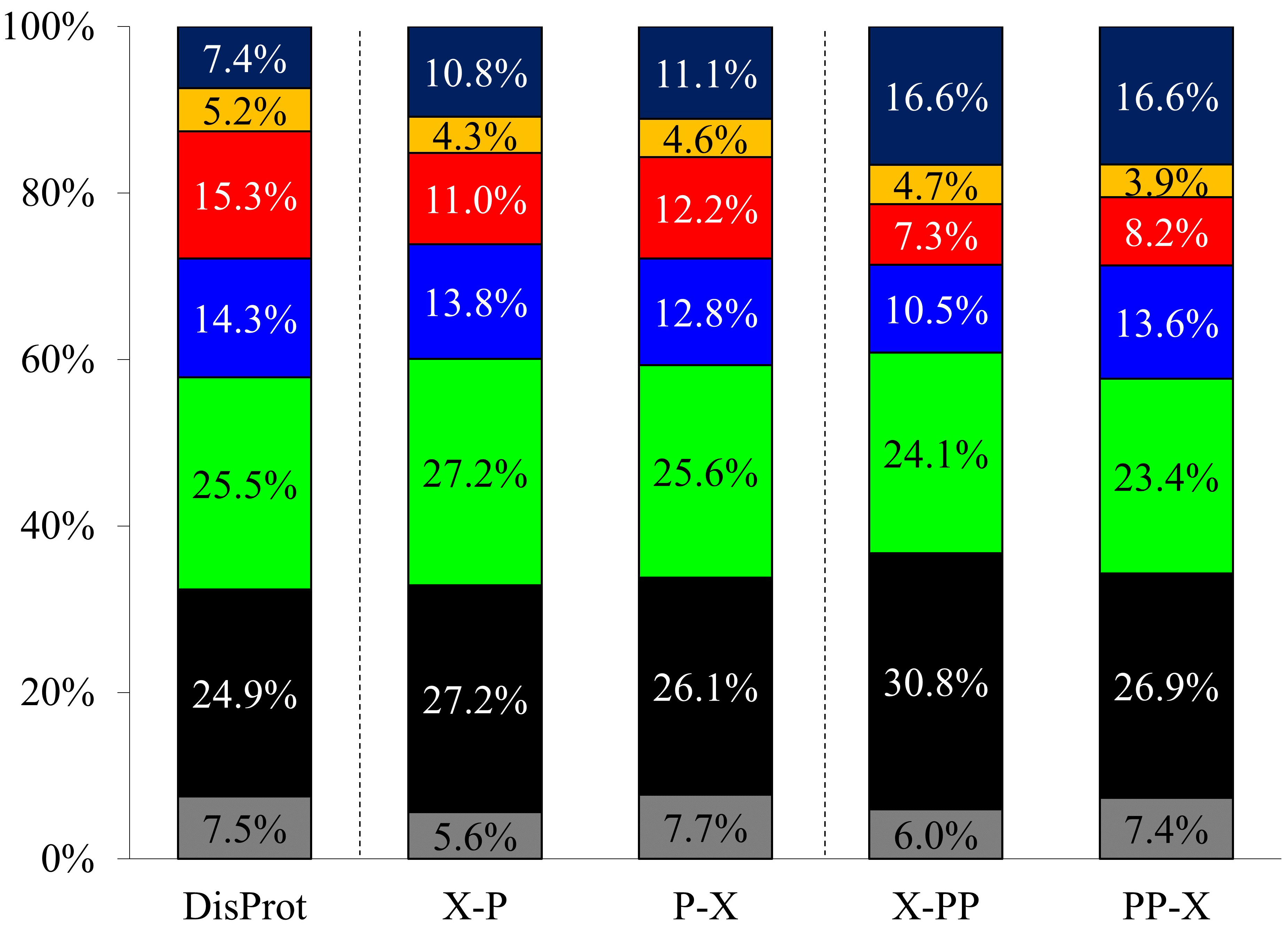 Fig. 2.
Fig. 2.Amino acid type occurrences in DisProt database and the Pro and Pro-Pro neighboring residues (denoted as X-P, P-X, X-PP, and PP-X, respectively). Gly (gray), aliphatic (black), polar (green), positively charged (blue), negatively charged (red), aromatic (yellow), and Pro (dark blue).
| X–P | |||||
| Residue type | Occurrence in DisProt | Expected value range | Number of occurrences | Comparison to DisProt | |
| Min | Max | ||||
| Gly | 7.51% | 1172 | 1258 | 913 | Significantly less |
| Aliphatic | 24.85% | 3950 | 4091 | 4407 | Significantly more |
| Polar | 25.50% | 4056 | 4198 | 4401 | Significantly more |
| Positive | 14.29% | 2256 | 2370 | 2231 | Significantly less |
| Negative | 15.26% | 2411 | 2528 | 1772 | Significantly less |
| Aromatic | 5.17% | 800 | 873 | 702 | Significantly less |
| Pro | 7.41% | 1157 | 1242 | 1754 | Significantly more |
| Total number of residues: | 16,180 | ||||
| P–X | |||||
| Residue type | Occurrence in DisProt | Expected value range | Number of occurrences | Comparison to DisProt | |
| Min | Max | ||||
| Gly | 7.51% | 1175 | 1261 | 1252 | No difference |
| Aliphatic | 24.85% | 3960 | 4101 | 4229 | Significantly more |
| Polar | 25.50% | 4065 | 4208 | 4144 | No difference |
| Positive | 14.29% | 2261 | 2375 | 2073 | Significantly less |
| Negative | 15.26% | 2417 | 2534 | 1974 | Significantly less |
| Aromatic | 5.17% | 802 | 875 | 749 | Significantly less |
| Pro | 7.41% | 1160 | 1245 | 1798 | Significantly more |
| Total number of residues: | 16,219 | ||||
Based on a two-sided binomial test with a 0.1 significance level.
It is important to note that prolines are often situated in proline-rich regions with repetitive Pro containing motifs that often form polyproline II-type helices. While the number of polyproline (containing consecutive proline residues) sequences longer than 20 residues in the UniProt database (https://www.uniprot.org/) is more than 6000, these motifs are underrepresented in the DisProt database, as here the longest polyproline sequence is only 13 residues long (DisProt ID: DP02591r001).
In order to determine the sequence dependence of the cis-Pro amount
(calculated as [cis]/([cis] + [trans])), we updated
our previously published dataset of IDPs and expanded our previous dataset to the
Pro neighboring i
The i
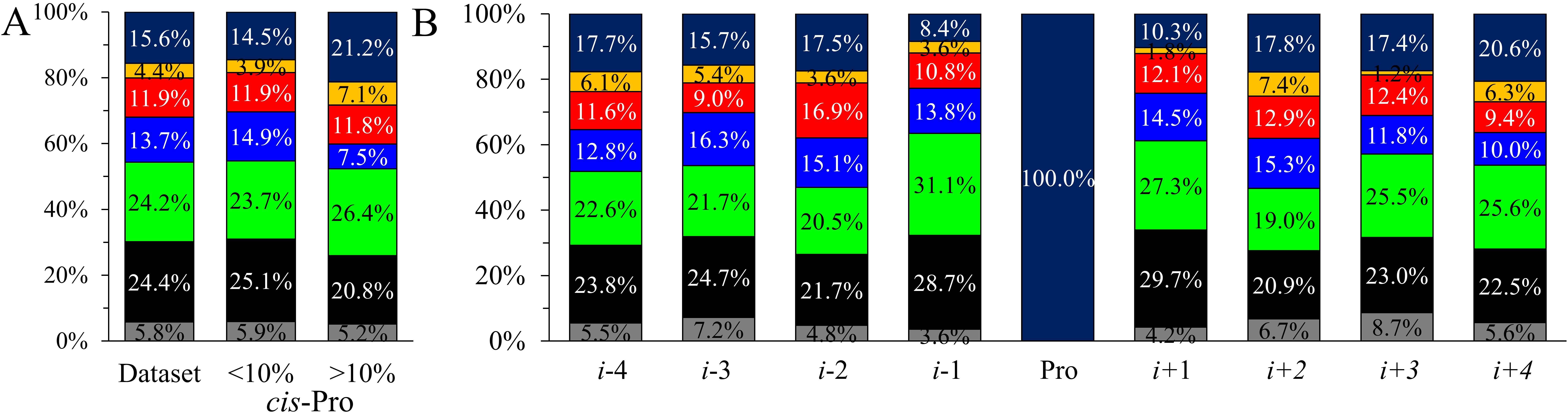 Fig. 3.
Fig. 3.Comparison of amino acid type occurrences. (A) In the current
database and the corresponding two subgroups according to the cis-Pro
ratio. (B) Amino acid type occurrences in each position in the i
The Pro neighboring sequences were divided into two groups according to the
cis-Pro isomer content (Fig. 3A). For cis-Pro content
In the individual positions for the complete dataset (Fig. 3B), some residue
types deviate significantly in the occurrence. The largest differences can be
found for Pro and polar residues, where more than a 12% deviation between the
highest and the least populated positions can be observed. In addition, two-sided
binomial tests at a significance level of 0.05 were conducted to investigate
which amino acid types (Fig. 3B) alter in the individual positions. We found that
the distant positions (i-3, i-4) do not deviate significantly
from the reference. Negatively charged residues are significantly more frequent
in the i-2 position. There are significantly more polar residues in
i-1 and aliphatic amino acids in i + 1 position. Prolines occur
significantly more in i + 4 position and less in i
In sequences with more than 10% cis-Pro content-considering a 0.05
significance level—the positively charged residues are significantly less
frequent in i-3 and i-1 positions (Fig. 4). In the i-1
position, aromatic and polar amino acids occur significantly more often, whereas
the number of Pro is reduced. Aromatic residues are common as well in the
i + 1 position. Note, Pro occurrence is significantly higher in
i + 1, i + 2, and even in i + 4 positions, and the
number of Gly is also increased at i
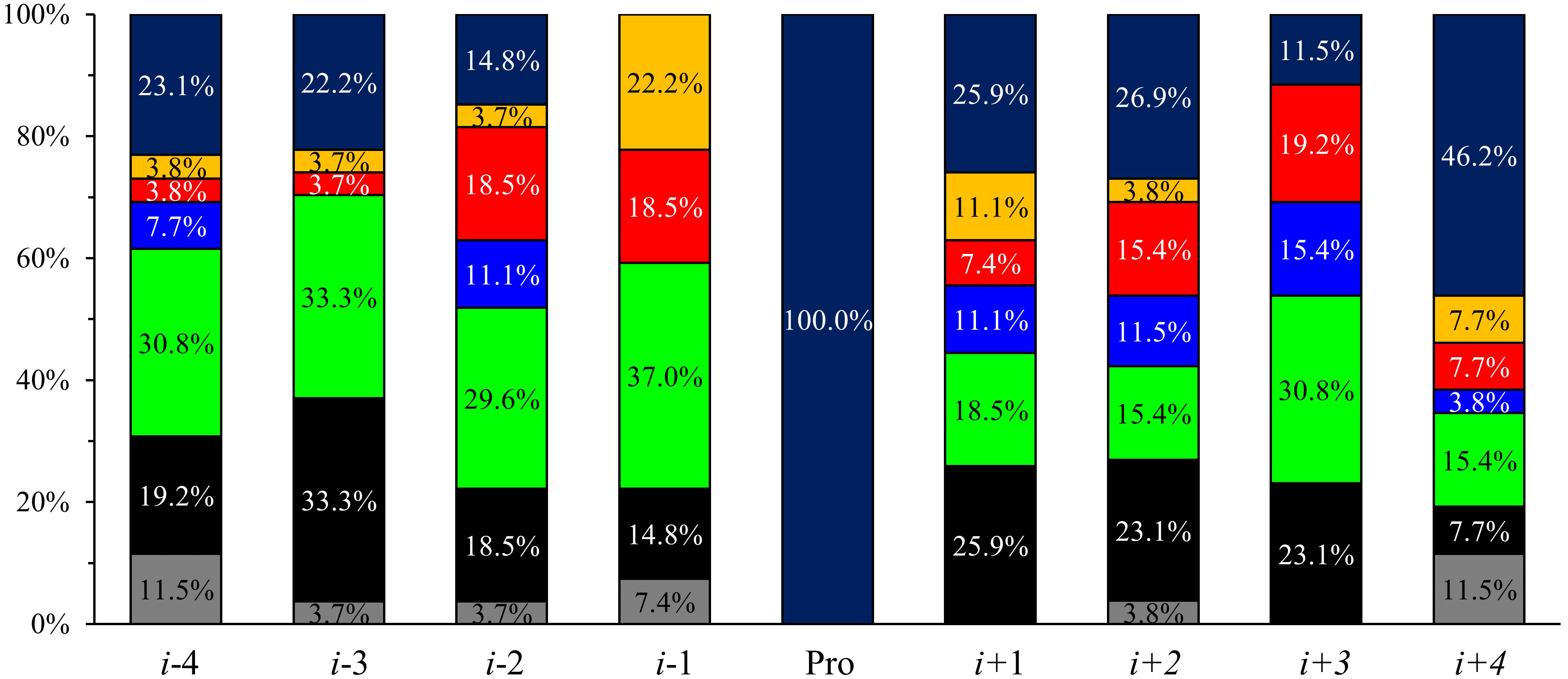 Fig. 4.
Fig. 4.Acid-type occurrences in more than 10% cis-Pro
containing sequences in i
Compared to our previous work, the general rules hold [17]: The number of
aromatic amino acids adjacent to Pro (i
The increased number of Asp and Glu in i-2, i-1, and i + 3 positions does not hold at 0.05 significance level, only at p = 0.1.
To validate our findings, model peptides with designed mutations were
synthesized (Table 1). All peptides were 12–15 residues long and were enriched
in Lys and Arg residues to test the effect of the positive charge. Since aromatic
residues in the i
NMR measurements were performed to test these assumptions. Peak assignment was
performed using 2D homo- and heteronuclear measurements on peptide samples with
natural isotope abundance. Since the concentration of the minor form is low,
approximately 50–200 µM for 1 mM protein, and
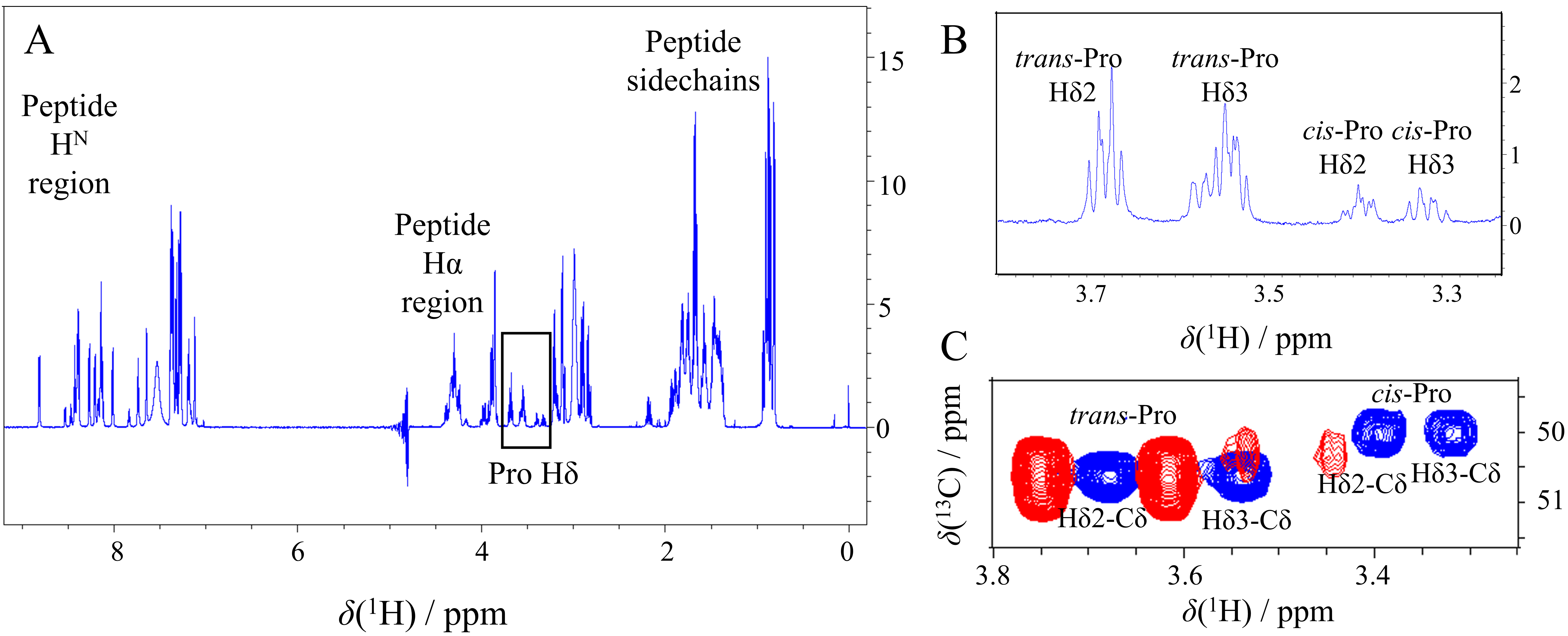 Fig. 5.
Fig. 5.Cis-Pro detection on 1D
| Peptide | Proline | i-4 | i-3 | i-2 | i-1 | i | i + 1 | i + 2 | i + 3 | i + 4 | cis-Pro% |
| I.A | P6 | R | G | L | F | P | F | L | G | K | |
| II.A | P6 | F | E | G | F | P | D | K | Q | P | |
| II.C | P6 | F | E | G | F | P | D | K | Q | A | |
| III. | P6 | K | K | G | F | P | E | K | L | K | |
| III. | P14 | K | E | K | L | P | G | ||||
| II.A | P10 | P | D | K | Q | P | R | K | K | ||
| II.B | P10 | A | D | K | Q | P | R | K | K | ||
| I.B | P6 | R | G | L | R | P | F | L | G | K |
Prolines are shown in bold; phenylalanines are shown in italics.
In Peptide I.A Pro6 has phenylalanine in i
Peptide II.A contains two prolines where two sets of minor peaks of different
signal intensities are detected. Here, the major Pro6 and Pro10
H
Peptide III. contains two proline residues. Pro6 succeeds an aromatic phenylalanine which is advantageous for a high cis/trans ratio (Supplementary Fig. 3B). However, the several positively charged lysines (i-4, i-3, i + 2, i + 4) reduce this effect, resulting in a 16% cis-Pro amount. The Pro14 neighboring sequence lacks aromatic residues, and the unfavorable positive charge sidechain is located in the neutral i-2 position producing a 10% minor isomer.
Considering the DisProt database, this study investigated the residue types and
their distribution in the Pro neighborhood (i-4 to i + 4
region). Pro
In order to bring experimental proof to our observations based on the
statistical analysis, synthetic peptides were designed. The cis-Pro
content was determined by NMR spectroscopy. We found that the sidechain of the
amino acids placed in the i
In conclusion, we prove that rationally designed mutations give rise to a desired increase or decrease of cis-Pro content. Our results can greatly benefit biotechnological purposes in the design of preferred proline conformations for functional tests.
ERD14, Early Response to Dehydration 14; EVH1, ENA-VASP Homology Domain 1; GYF, glycine-tyrosine-phenylalanine domain; IDP, intrinsically disordered protein; IDR, intrinsically disordered protein region; SH3, SRC Homology 3 Domain; UEV, ubiquitin enzyme 2 variant; WW, tryptophan-tryptophan domain.
The data presented in this study are available on request from the corresponding author.
AB designed the research study. FS, JS, NP, GT and AB performed the research. FS and AB analyzed the data. FS, GT and AB wrote the manuscript. All authors contributed to editorial changes in the manuscript. All authors read and approved the final manuscript. All authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
Not applicable.
The authors thank Dániel Kovács for fruitful discussions regarding statistical analysis and Tünde Horváth for the help with the python scripts.
This research was funded by National Research, Development and Innovation Office, Hungary, grant numbers NKFI K124900; K137940, and the ELTE Thematic Excellence Programme 2020, National Challenges Subprogramme - TKP2020-NKA-06.
The authors declare no conflict of interest.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.