



 , Kai A. Bauch 2
, Kai A. Bauch 21 Department of Business Administration and Economics, Heinrich Heine University Düsseldorf, 40225 Düsseldorf, Germany
2 Faculty of Business Studies and Economics, University of Kaiserslautern-Landau, 67653 Kaiserslautern, Germany
Abstract
Actors establish decision routines to simplify and speed up decision-making in repeated tasks. The notion of stable decision routines is implicit in many strands of behavioral research on managerial decision-making, notably tasks involving the aggregation of information. It is presumed that actors adhere to their decision routines, particularly in the short run. However, the validity of this assumption has not been tested. Using performance evaluation as an example and statistical models to reconstruct actors’ decision routines, this paper investigates how such routines are established, what they look like, and how persistent they are. We also inquire into the relevance of personal features of the evaluator in this process. Our findings offer insight into a contradiction underlying research on managerial decision routines. Prima facie, evidence indicates that decisions can seemingly be successfully reconstructed using simple routines—often oriented toward the linear-additive evaluation model underlying school grades. This is indicative of stable routines, which form the basis of meaningful research, for example on biases in decision-making, as well as of managerial practices such as indicator-based performance evaluations. However, contrary to the implicit assumption of stable routines, we find that despite the high explanatory power of decision models, decision routines are not stable, even when performing a task such as performance evaluation repeatedly. Implications for managerial decision-making and research on biases in recurrent decisions are discussed.
Keywords
- information aggregation
- performance evaluation
- decision-making
- management control
- decision-routines
Many managerial activities involve making highly similar decisions repeatedly. Some of these decisions concern choices among fixed and pre-defined options, others involve aggregation of information. Many of these decisions are of operational nature and happen periodically (Perkins and Rao, 1990). Examples are assessing the feasibility of investment proposals (Azadegan et al., 2018; Fehrenbacher et al., 2020), deciding about budgets for business units (Bennouna et al., 2010) or adapting prices (Gahler and Hruschka, 2022). Many recurrent business decisions have in common the fact that managers have some quantitative information on which to base their decision while retaining substantial managerial discretion in the decision-making process (e.g., Perkins and Rao, 1990; Blattberg and Hoch, 1990; Verstraete et al., 2020; Raisch and Krakowski, 2021). In the following, we focus on a typical recurrent routine management task: evaluating the performance of subordinates (Ittner and Larcker, 1998; Williams and Beck, 2018; Alves and Lourenço, 2023). The task is recurrent in two ways: It has to be done periodically and many subordinates have to be evaluated. Typically, a manager has information on financial and non-financial measures that reflect upon a subordinate’s performance, often presented in a structured way using a balanced score card, henceforth BSC (Balanced Score Card). Still, managers can discretionarily weight and aggregate these measures as they see fit when forming an overall evaluation (Cardinaels and van Veen-Dirks, 2010). Implicit to the very idea of performance evaluation as a means of management control is the assumption that superiors evaluate their subordinates in a predictable way. The evaluation should be neither random nor irrational (Carmona et al., 2014), as employees will perceive arbitrary usage of managerial discretion in performance evaluation as unfair and reciprocate by lowering work effort (Hannan et al., 2008; Hannan et al., 2013; Lechermeier and Fassnacht, 2018). As in other instances involving managerial discretion, this process may well contain subjective elements (Gillenkirch and Kreienbaum, 2017), strategic considerations of the evaluator (Hecht et al., 2019), or even be biased (Bol, 2011; Kramer and Maas, 2020). But even in being subjective and/or biased, the underlying assumption is that there is a structured routine by which a manager evaluates subordinates. More generally formulated, it is presumed that managers reach similar decisions for similar cases. Instruments of management control, like BSC or budgeting tools (Burger-Helmchen, 2008) shall foster this and preclude arbitrariness, which is seen as a major problem in performance evaluation (Nishiura Mackenzie et al., 2019). As such tools do and shall not determine managerial evaluative behavior, this implies that managers establish a personal—as opposed to an organizational—routine to process available information in order to reach a decision about a performance evaluation (Verplanken et al., 2005).
However, it is empirically unclear whether managers actually establish a routine. Further, it is unclear, how such routines look like and in particular how stable they are. Given these open questions, we investigate how managers aggregate information in recurrent decisions, using performance evaluation as an example. We focus on the form and stability of routines, but also aim to increase our understanding of factors that facilitate or hamper the establishment and relevance of information aggregation routines in recurrent managerial decisions.
Drawing on the existing literature on routine formation in repeated settings (Hull, 1943; Betsch et al., 2002; Verplanken et al., 2005), we argue that decision routines are established over the course of the task. We derive empirical implications and test hypotheses. Our first hypothesis states that behavioral routines are established. By “routine”, we refer to actors establishing a procedure to process information into a decision. Establishment of a routine also implies that the routine’s functional form, understood as how information is weighted and combined, remains stable. Secondly, we argue that a routine should account better for decisions made in later stages of a series of repeated tasks, as the routine gets established over time. Specifically, explanatory power of a statistical model used to reconstruct the decision routine should be higher in the later decisions than in earlier decisions in a series. Thirdly, we also argue that persons with certain cognitive styles establish routines stronger than persons with other cognitive styles. Notably, persons tending to decide intuitively should establish weaker, less relevant routines, if at all.
We use performance evaluation of subordinates as example in an experimental study on the establishment of routines. Participants’ task consists of evaluating the overall performance of subordinates. Participants are presented twenty fictive subordinates, each of which has a given, specific combination of four measures indicating the subordinate’s performance in four different domains. Both, the order of the subordinates as well as the order of presenting the performance measures of each subordinate were randomized. We then capture the participants’ performance evaluations. The functional relationship linking the four measures and the performance evaluation given constitutes the decision routine of a specific participant. We compare the fit of various functional forms for reconstructing this linkage for the twenty subordinates.
Overall, we find that a linear additive functional form, similar to the school grade model, fits best. The four measures are weighted and additively combined to an overall performance rating. We find that the standard methods to capture decision routines established in psychology allow to reconstruct the routines used, but a sample-level view over-estimates stability of these routines. While the functional form basically remains in place, some participants follow their routine to a higher degree, becoming more structured in their decision-making. Other participants become more random in their evaluations over the course of the twenty rounds of the experiment. Further, the weights attached by participants to specific measures change over the course of the experiment.
We contribute to research on repeated managerial decision-making but also to the usage of organizational measures which aim at supporting structured managerial decision-making.
Organizational measures, such as the BSC in the case of performance evaluation, aim at making managerial decision-making less idiosyncratic and more “rational”, in that it is oriented at existing information in a reliable way. In doing so, organizational measures imply the establishment of decision routines at the level of the individual manager. However, the existence of personal routines is presumed rather than ascertained. Our paper indicates that firms should also pay attention to the fact that managers may vary in how structured their decision-making is, and may do so more than presumed in research on this theme.
In terms of behavioral research on repeated decision-making, specifically our example, performance evaluation and BSC usage, the implicit view of performance evaluation is that there is some routine, by which managers evaluate subordinates. Most of the research has the focus on how this routine is biased, for instance by mood or affect (e.g., Robbins and DeNisi, 1994). Much research is also about eliminating these biases (e.g., Kaplan et al., 2018). The notion of “bias” implies that an evaluation is not, as it should be from the normative perspective of rational decision-making. For instance, the way information is presented should not affect the evaluation, but does so (Maas and Verdoorn, 2017). We find that performance evaluations also differ, because the way performance information is combined changes spontaneously. This implies that the relevance of biases, which also refers to differences in evaluations, could be over-estimated too. The evaluative behavior of the actors is inherently much more random and unstable than presumed, making it difficult to separate biases from random variation in behavior, in particular if few or only one instance of a decision are used in a study. This supports the argument made by Kravitz and Balzer (1992) on the need to have a reference to be able to determine biases. As it is, differences in two subsequent evaluations may be due to bias, or be due to changes in the decision routine, as, for instance, performance measures which were important up to now can suddenly lose their importance, and vice versa.
As a practical contribution, concerning the more general implications for managerial decision-making, the study raises awareness that while managers establish routines for recurrent tasks, their routines change, and may do so already over the course of a prolonged task. This is the case even in organizational settings with structured provision of information, which explicitly aims at reducing arbitrariness and randomness. Presenting the same information in the same way does not guarantee that the information is used the same way throughout a repetitive task. Changes in how the information is used are not only due to biases, but are an integral part of repeated decision-making.
Routines in our definition differ from organizational routines in the sense of Pentland and Rueter (1994) as they concern intra-personal processes for which the manager is intentionally given discretion by the organization. Our review concerns routines in general, but also the state of the art on performance evaluation as a routinized process.
Decision routines for aggregating information concern the way a decision is made by a specific actor. In this they contrast from organizational routines (Pentland and Rueter, 1994), but also from routine choices among fixed options, see e.g., Bargeman and van der Poel (2006) or Bröder et al. (2013). Specifically, we consider how actors aggregate performance information to an overall performance evaluation. The application we use is in many ways typical for the management context: it is a periodically recurrent task, there are many cases to evaluate, there are several criteria on which to base the decision, but actors are explicitly given discretion. This application can be seen as a proxy for many types of evaluations inside the business context and beyond, from investment projects, to budgeting, to academic paper reviews.
For such situations, it is implicitly assumed that the actors formulate a personal decision routine to alleviate recurrent decision-making (Verplanken et al., 2005; Betsch and Haberstroh, 2005). In the case of an information aggregation task like performance evaluation, the routine is defined by how information is weighted. True, decisions may be influenced by random factors or systematic biases, but conceptually, this is a divergence from a routine by which an actor combines information into a decision. The existence, relevance and persistence of such routines are central assumptions implicit to the research on repetitive decision-making and multi-criteria evaluations in general (Banker and Datar, 1989).
Such routines are similar to decision heuristics, as both, decision routines in our conceptualization and heuristics, describe the phenomenon that in a task, in particular a repeated one, actors establish a routine to solve the task in an easier, cognitive less demanding and in particular faster way (Betsch and Haberstroh, 2005; Artinger et al., 2015). While both, heuristics and routines, describe a stable procedure by which a decision is made, we see heuristics as pre-existing, even hard-wired and refer to routine as the procedure actors develop over the course of a new, but potentially recurring task, like the task used in this study. Heuristics—and habits, as their even more automatic counterpart—received substantial attention (Lally et al., 2010; Gardner et al., 2012; Verplanken, 2018). However, most research on heuristics is about inventorying existing heuristics, e.g., the availability heuristic or affect heuristic, analyzing the situations and factors triggering their usage, but also their implications for the quality of the decision, typically with an explicit reference what is objectively or normatively right or wrong. For instance, the availability heuristic may deliver a quick and easy solution to a question, but this solution may be wrong. Depending on the research tradition, the usage of heuristics is seen critical (Tversky and Kahneman, 1974; Kahneman et al., 1982) or positive, as quick and often appropriate decision-making which outperforms more elaborate modes of decision-making (Gigerenzer and Gaissmaier, 2011; del Campo et al., 2016; Szanto, 2022; Gahler and Hruschka, 2022).
For decision routines for aggregating information to a performance evaluation, there is no right or wrong decision in the objective sense like in the many examples used in research on heuristics. Nor is there personal utility involved, which would allow to compare the factual choice with the choice which would be optimal, given the preferences of the actor. Evaluative decisions can be biased, meaning influenced by information and criteria which should not have any influence: For instance the evaluation can be driven by affect (a likable person receives a better evaluation; Cardy and Dobbins, 1986), or mood (if the evaluator is in a bad mood, all evaluations are less favorable; Carmona et al., 2014). Various features of the evaluator’s personality (Bernardin et al., 2016), among them the pre-existing attitude of the evaluator to the evaluated matter in performance evaluation. Notably, if the evaluator feels committed to the evaluated due to past actions, like hiring this person (Bazerman et al., 1982; Kramer and Maas, 2020). An evaluation may be disproportionally outstanding, if the case up for evaluation contrasts with the majority of the cases (Ivancevich, 1983) but usually, evaluations vary less than the actual performance data would warrant (Golman and Bhatia, 2012). Further, performance evaluations were found to be affected by the very way in which the information is presented (Maas and Verdoorn, 2017).
The state of the art on decision routines in performance evaluations covers (a) methods to capture the routine, (b) their form, and (c) their persistence.
(a) In terms of how a decision routine is captured, the standard method is to present actors with a larger number of decision situations, record their evaluations, and to reproduce their evaluative behavior by some form of statistical model (Naylor and Wherry, 1965; Keeley and Doherty, 1972; Taylor and Wilsted, 1974). If, for instance, the decision routine is some form of a linear-additive rule, as suggested e.g., by Dawes (1979), regressing the evaluations on the performance data will reproduce this rule, giving the weights of the performance aspects and in particular the functional form—if the rule is multiplicative, a logged model will feature a better fit (Brannick and Brannick, 1989), rules counting the achievements of targets can also be modeled.
(b) In terms of how decision routines look like, the dominating functional form are versions of the linear-additive model, by which the different pieces of information are weighted and added up to the performance score (Slovic and Lichtenstein, 1971; Hammond and Summers, 1965). This functional form allows for high performance in one aspect to compensate for lower performance in another one, while for instance a multiplicative function requires some minimum level of achievements in all aspects to result in a non-zero evaluation. The dominance of the linear-additive functional form might be explainable by the fact that it is structurally similar to the grades received by pupils in schools and the method by which school marks received in different subjects or within a subject, like oral engagement, presentations, or written exams, are combined to an overall mark. Part of the prominence of such linear models is also due to their strong performance when making decisions, e.g., medical diagnostics, in this way (Meehl, 1954; Dawes, 1979). At times, other functional forms are considered and indeed, their usage as a model of actual behavior is strongly suggested (e.g., Brannick and Brannick, 1989). A persistent issue is whether the routines are, like many heuristics, which may well be inborn, pre-existing as meta-models and just applied to a specific setting, or whether they are induced by the settings used. Given the fact that via schooling everyone in the western world is familiar with the linear-additive form, the predominance of this functional form indicates that the meta-routine of using some linear-additive form to combine information is pre-existing.
(c) In terms of persistence, research indicates that time pressure results in persistence of routines, as persons are less prone to consider the appropriateness of their general routine for a specific case if they are under pressure. Inversely, the more a specific task differs from the prototypical task for which a routine was established, the more persons tend to deviate from their routine (Betsch et al., 1998). Still, given that research on performance evaluation rarely uses many cases, but often just one or very few, little can be said about the persistence of a personal rule in the behavior. Also, the routine in the case of a performance evaluation is not a routine in the sense of Betsch et al. (1998), e.g., to choose route A to location B, but a decision about how to arrive at a decision, which is made the same way but where the specific outcome differs in each instance.
Evaluating the performance of subordinates is a routine management task (Merchant and van der Stede, 2011). Oftentimes, the line manager has to evaluate the performance of team members or managers who are in charge of regional subsidiaries of a firm in different locations. Management tools like the BSC (Kaplan and Norton, 1992; Kaplan and Norton, 1996; Den Hartog et al., 2004), shall enable managers to put their evaluation of a firmer, more data-based ground, while still allowing for some degree of managerial discretion and the inclusion of non-verifiable private information which in the first place justifies an evaluation made by a person rather than by a deterministic algorithm (Dai et al., 2018; Fisher, 2019) albeit there is a trend towards what Vahrenkamp (2023) calls “mathematical management”. The manager’s task is to combine this information in a single performance score. What is to be avoided, is that employees feel treated unfairly, e.g., because managers reach different decisions in situations, where the informational basis is similar but used differently (Ittner et al., 2003), be it for strategic (Hecht et al., 2019) or irrational reasons (Carmona et al., 2014). Little astonishing, random or arbitrary evaluations reduce the subordinates’ effort (Hannan et al., 2008; Hannan et al., 2013; Lechermeier and Fassnacht, 2018) and counteract the rationale for using BSCs. A substantial body of research thus investigates various factors that may lead to bias in managers’ recurrent decisions (for many: Bol, 2011). For example, interpersonal affect may cause evaluators to favor some actors over others (Fehrenbacher et al., 2020; Bouwens et al., 2022), some managers tend to be too lenient or to be too uniform in evaluating persons with large differences in performance (Golman and Bhatia, 2012; Grund and Przemeck, 2012). So, while performance evaluation and BSC usage has been subject of research for a long time, an altogether different issue is, how the information provided in the BSC is actually combined to an evaluation and whether this is done in a persistent and routinized way. The BSC offers information to go into the performance evaluation, but does not prescribe how to aggregate the information. The BSC approach neither guarantees that all information presented is used for the evaluation (see e.g., Lipe and Salterio, 2000), nor does it preclude information, which is not in the BSC, e.g., similarity to self or sympathy, to enter the evaluation (e.g., Bauch et al., 2021). Given that the task is complex but also repetitive, one can assume that managers establish a personal routine for combining the input data into an evaluation (see Betsch et al., 1998 for the notion of routine used here). This routine may, in principle, take any form. For instance, the manager may check, whether all targets set are met or may use a personal scoring where each target is weighted and added to an overall performance score. The manager may also focus on one isolated aspect she sees as most important, and check, whether the target is met, discounting all other indicators as irrelevant.
Open questions concern routines in performance evaluation and routines for information aggregation in general. Research on performance evaluation, despite being based on the broader evaluation research in psychology, often uses one shot experiments (Taylor and Wilsted, 1974; Lipe and Salterio, 2000; Kaplan et al., 2008; Kaplan et al., 2012; Dai et al., 2018), where individuals basically give a single evaluation or are to evaluate two subordinates differing in some feature of interest, such as likability. Comparing this scenario to real-life performance evaluations reveals this scenario to be to some degree unrealistic. Further, there is little or no information on the existence and relevance of decision routines in repeated performance evaluation. Existing research on performance evaluation focused on biases, but still, the idea underlying performance evaluation research is, that there is some kind of routine in existence, from which the evaluators diverge. As Kravitz and Balzer (1992) argue, even if the sole aim of the research is to capture the bias, the standard design in which just the effect of a bias-inducing stimulus is considered, is inappropriate, as there is no reference to compare the decision with in order to capture the bias and to estimate its magnitude. Considering performance evaluation as a specific instance of a process subject to routinization raises further questions about the establishment of routines: How do information aggregation routines look like and how persistent are these routines? Our questions are complementary to existing research on performance evaluation, in that existing research assumes stable routines and studies, in how far these feature biases, whereas we are interested the very existence and form of routines.
While most of the existing theoretical and empirical work on managerial routines concerns behavior involving self-interest (e.g., the choice of an option from a set of options) and concrete decision options (e.g., a route towards a location, Betsch et al., 2002), the arguments made in these research strains can be expanded to the decision about how a decision is made. In our case, this concerns a personal routine how different pieces of information are combined into an evaluation of a subordinate. Based on very early findings from behavioral research, beginning with Hull (1943) who found that behavior tends to become more homogeneous over time, i.e., people tend to behave in the same way if the re-encounter the same situation, establishing a match between the situation and their behavioral choice (Davis et al., 1993; Betsch et al., 1998), we formulate the following hypothesis:
Hypothesis 1: Actors establish a routine of some form which then guides their evaluative behavior.
This very basic hypothesis is implicit to all research on evaluations, in economics as well as other domains. Despite the focus on the role of biases, the effects of the information presented and the way it is presented, the assumption is always that evaluative behavior is structured and not random. As Kravitz and Balzer (1992) noted, a crucial problem of experimental research on biases in performance evaluation is that structured behavior, what we denote as routine, is assumed, but not empirically measured, putting the findings in question. The crucial issue is whether the bias can be identified, given that participants in experiments decide following different and randomly chosen routines. For instance, a likability bias can be seen as part of a routine: Some actors use likability as an element in their routine and tend to evaluate a likable subordinate better because they use their affect as information (Ding and Beaulieu, 2011). Here, changes in the evaluations are attributable to the different degrees of likability, which is still a structured decision-making, albeit one based on the wrong type of information. If the actors chose different sets of criteria for different persons, e.g., give one subordinate a good evaluation, because he is likable, regardless of the performance information, but give another subordinate a good evaluation, because she performs well and do not pay attention to the (dis)likability of the subordinate, different routines apply. Speaking of a bias makes little sense in this situation. In terms of empirical expectations, hypothesis 1 implies that a routine can be extracted and that the routine is stable over time. In terms of a statistical analysis, the implication is that (1) a statistical model can reconstruct the linkage between the performance information and the evaluations given and that (2), the same statistical model applies to all evaluations given by a specific actor.
Hypothesis 2: The evaluations of actors become more structured and less random over time.
While there is, to the best of our knowledge, no empirical research on speed and patterns in the establishment of routines in performance evaluations, Hull’s (1943) argument underlying the routinization process can easily be applied to our setting: In the first rounds of evaluations, actors may be at loss how to evaluate the person in question, also because they have no benchmark regarding what is good or bad performance, in what aspects of performance of the persons up for evaluation differ much or little, and so on. How they use the information may initially differ from case to case. As the evaluation progresses, actors will make up their mind in terms of what performance indicators are in their view important—which is to say, a routine will be established. This implies that their behavior will be more structured, less random in the latter stages of a repeated performance evaluation task. Specifically, the fit of a statistical model capturing the routine should be higher in the latter stages of the repeated performance evaluations.
Hypothesis 3: Actors featuring an “intuitive” cognitive style establish routines less strong than actors with a “need for cognition” cognitive style.
The argument underlying the third hypothesis can be derived from the argument that persons with higher cognitive abilities are able to solve problems faster and also typically show higher performance in their job (Hunter, 1986) and the distinction in cognitive styles suggested by in Epstein et al. (1996). Epstein et al. (1996) differentiate between persons with a tendency to decide intuitively, characterized by a more ad hoc usage of information, and persons with a higher need for cognition, characterized by a systematic usage of information and intense consideration of the problem at hand. We transfer this general argument to the specific task used in our study, arguing that actors with a tendency to think about a task more thoroughly and also explicitly should consider the task in a more structured way right away and settle upon a routine if the task occurs repeatedly. The contrary is true for actors who adhere to intuitive decision-making, where the decision-making is more spontaneous and less structured.
The research design chosen shall capture the routines actors establish to perform a repetitive BSC-based performance evaluation and allow insights on how persistent they are.
This study is part of a larger research project on biases in BSC-based performance evaluation. The study commences by introducing the participants to their role, which is that of a regional manager of an apparel chain in charge evaluating store managers in a region. Throughout the study, four different performance measures are given: Two financial ones, sales growth and proportion of achieved pricing targets, and two non-financial ones, average customer satisfaction and vocational training measured in hours of employee training. Next came an illustration of the task, presenting three exemplary cases, where store managers were given scores from excellent (200), to average (100), to poor (0). After the training, participants were informed that, as regional manager, they are in charge of a region containing twenty stores of their firm and had to evaluate each store manager according to the four performance measures. Participants were informed that all four performance measures are relevant, but that they had discretion in terms of the importance they assigned to each measure. For each store manager, the four performance measures have different values, some are indicating a very high, some a very low performance, some the various stages between. While the performance of the twenty store managers varied, the target values for the four performance measures were identical throughout the study. For each store manager, the information presented was the name and the four performance measures, which were fixed for this particular store manager. The twenty store managers were presented in a random sequence and the four performance indicators were presented in a randomly assigned position in a 2 by 2 table in order to avoid effects of attention being focused on the item in the “first” position (typically the upper left box).
After the twenty evaluations, a small data set was available for each participant, in which the four performance measures presented translate into the evaluation given, a 0 to 200 score. The feature of interest is how the performance measures translate in an evaluation, i.e., if there is a function linking performance measures and evaluations. If this is the case, the next questions is, which form it has and whether it is stable throughout the task, once established. Specifically, we regress the performance evaluation (as the dependent variable) on the four performance measures (as independent variables), using different functional forms, which constitutes potential routines by which participants translate the information in an evaluation. Next, we compare the different functional forms/routines in terms of their fit, how they look like and whether they are stable.
On the whole, 160 students participated. 72% of them studied economics or business administration, on average they were in the 7th semester (Master). 52% of them were female with an average age of 25 years and 25 months of job experience, typically due to obligatory full-time internships or jobs beside their studies.
We start out by investigating, what information on the evaluated regional managers is relevant for the evaluations given, when all participants are considered, and in particular, whether evaluations are structured or random, when the overall sample is considered. The degree of structuredness is a first indicator of routinization of performance evaluations. Clearly, the very idea of a BSC implies that the performance-related information matters, but the existing research reported above indicated that factually, information unrelated to performance matters, too. While we have only limited information, the data still allows for an estimation of the relevance of information relating to performance, but also information which is not performance-related and also the relevance of features of the participant doing the evaluations. Table 1 gives this information using an OLS (Ordinary Least Squares) regression, assuming a linear-additive model, basically a version of the school-marks model suggested by early psychological research on routines (Naylor and Wherry, 1965; Taylor and Wilsted, 1974; Dawes, 1979). A multiplicative model was also explored, but yielded a much lower fit.
| Model 1 | Model 2 | Model 3 | |||
| beta | t | beta | t | ||
| Sales_Growth | 0.38 | 25.01 | 0.38 | 30.75 | |
| Customer_Satisfaction | 0.31 | 17.06 | 0.31 | 20.98 | |
| Price_Targets | 0.31 | 17.17 | 0.31 | 21.14 | |
| Vocational_Training | 0.17 | 12.06 | 0.17 | 14.80 | |
| Male_Subordinate | 0.09 | 5.19 | 0.09 | 6.36 | |
| Decision_Number | 0.05 | 3.84 | 0.05 | 4.72 | |
| Participant Dummies | included | included | |||
| N of Decisions | 3197 | ||||
| N of Individuals | 160 | ||||
| R2 | 0.365 | 0.234 | 0.600 | ||
| R2_adj | 0.364 | 0.194 | 0.578 | ||
Notes: Dependent variable is the evaluation given, which was regressed on the performance indicators, gender of the subordinate and the decision number (#1 to #20) and dummy variables for each participant (not tabulated). Entries are standardized regression coefficients. “N of Decisions” is the number of individual decisions made, note that some of the 160 participants did not make all twenty decisions. Model 1: Only features of the subordinate used as explanatory variables. Model 2: Only participant dummies used as explanatory variables. Model 3: Features of the subordinate and participant dummies used as explanatory variables.
OLS regression is a very robust approach for exploring the relevance of
performance indicators. Looking only at the information about the evaluated
subordinate (column Model 1), we see that performance-related information affects
the decision—but information, which should be irrelevant, also matters to a
non-negligible degree. First, there is a trend among participants to become more
lenient over time (Decision_Number), which implies that, on average, the 20th
evaluated regional manager receives a bonus of 8 (= 20
Next, we analyze which routines factually occur at the individual level by inquiring into which statistical model allows best to reproduce participants’ decision behavior.
In terms of information going into the routine, the regression analysis presented in Table 1 above indicates relevant factors but a technical problem arises when analyzing subsets of evaluations. We are interested in the stability of the decision routines. Thus, we need to compare the fit of the statistical model representing the routine for subsets of decisions. In particular, we need a working model for analyzing the last ten evaluations of each participant. As the presentation of the regional managers’ profiles was random, some participants received only men and only women in consecutive cases, in particular, if the subset considered is small. Thus, we chose to define the subsets by the first and last ten evaluations given. This allows to include all variables found to be relevant, viz., the performance measures, the decision number variable and the gender of the manager up for evaluation.
In terms of the functional form, we compare several routines.
First, a simple decision rule which just checks how many of the targets were met—the variable used is the number of targets met, ranging from 0 to 4.
Second, we used the information which of the four targets were met (included as four dummy variables, indicating a specific target was met or not).
Third, we used the school-mark model, i.e., a linear-additive model using the actual values of the four performance measures.
For all versions, the performance information was combined with the decision number and the gender of the evaluated subordinate. Personal tendencies of the participants are captured by the person-specific intercept. For instance, if the intercept for a participant is high, this is indicative of a tendency to hand out more positive evaluations.
Each of the three routines was applied to all twenty cases and also to the last ten cases in the series of evaluations. Hypothesis 1 stated that routines are established. Hypothesis 2 stated that this establishment should be progressive. If indeed a routine was established over the course of the study, the fit of the model representing this specific routine should be higher in later stages. Technically, the evaluations given for all twenty or the last ten cases were regressed on the information on the case, using the three models outlined above. The regression returns two pieces of information.
First, the weights assigned to a performance measure. For instance, if a participant chooses to ignore a performance measure, say vocational training, the measure’s weight will be zero. Those measures, which are relevant for the decision of the participants, will have non-zero values, presumably positive, albeit, given that there are only twenty decisions on which to base the analysis, one cannot realistically expect statistical significance.
Second, the analysis will yield an information on how well the model fits the behavior of a specific participant. Generally, the higher the R2 of the regression, the more the participant’s behavior can be reproduced by the model indicating stronger routines. Indicating in our conception stronger routinization. Some participants may feature lower R2, e.g., because their evaluations are more random or because they establish another routine. One can compare how well a specific routine fits to the evaluations given, but moreover, one can compare the model fit for different stages in the study. If the model fit increases over time, this change can be interpreted as a learning curve. Table 2 gives the statistics of the three types of decision routines for all twenty and the last ten cases, respectively.
| Type of decision routine | Explanatory power | ||
| Mean | Min | Max | |
| Number of targets met routine: all 20 cases | 0.390 | 0.053 | 0.815 |
| Number of targets met routine: last 10 cases | 0.510 | 0.025 | 0.942 |
| Targets met routine: all 20 cases | 0.613 | 0.243 | 0.934 |
| Targets met routine: last 10 cases | 0.778 | 0.289 | 1.000 |
| Linear-additive routine: all 20 cases | 0.736 | 0.177 | 0.932 |
| Linear-additive routine: last 10 cases | 0.870 | 0.187 | 0.996 |
Note: R2 as obtained for regressing the evaluations given on the four performance indicators, gender of the subordinate and decision number for each of the 160 cases, when using the all twenty or the last ten evaluations.
With regard to hypothesis 1, which stated that actors establish a decision routine, the results presented in Table 2 indicate that the linear-additive decision routine allows to reconstruct the evaluations of the participants to a substantial degree. On average, this routine accounts for 74% of the variation in all the evaluations given, and 87% of the variation in the evaluations given for the last ten cases. Taking into account that participants needed to engage in a computation similar to a linear-additive regression this is a substantial fit. Thus, there is evidence that a routine is established, which supports hypothesis 1.
With regard to hypothesis 2, on the learning process resulting in more structured decisions towards the end of the study, the results in Table 2 are also supportive: In general, the overall fit for the last ten evaluations is higher than the fit for all twenty evaluations, which implies that indeed decision routines are more established in the last ten rounds. This is supportive of hypothesis 2.
In terms of the form of the routine, the lowest fit occurs for the model, which assumes that the number of targets met, 0 to 4, is used to evaluate subordinates (39% explained variation among all 20 evaluations, 51% among the last ten evaluations). Using the information that a specific target was met, regardless of whether the subordinate overachieved a target has a better fit (61% and 78%, respectively). However, the linear-additive model fits even better (74% and 87%, respectively).
Comparing the explanatory power of the two best fitting models in more detail, Fig. 1 gives the distribution of the explanatory power, measured as R2, x-axis, of the linear-additive (Fig. 1A) and the “specific-target-met” routine (Fig. 1B) for the last ten cases evaluated by the participants.
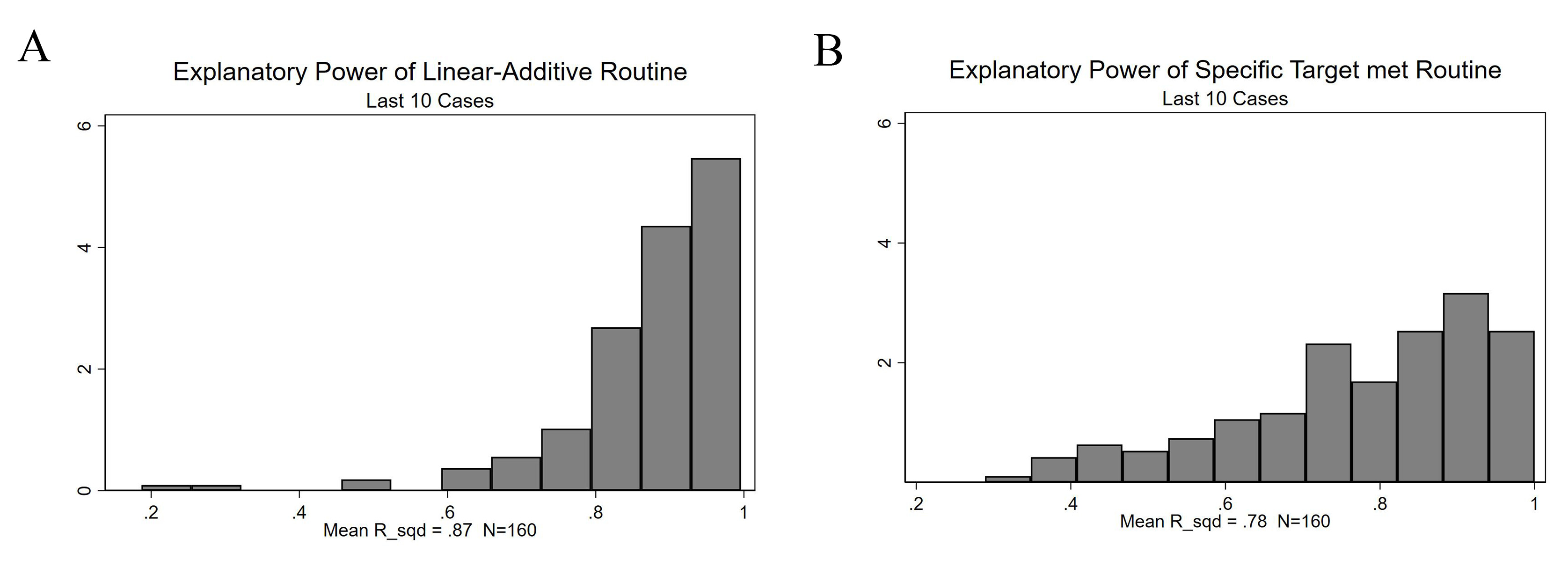 Fig. 1.
Fig. 1.
Explanatory power of decision routines.
As both histograms indicate, the linear-additive model allows to reconstruct the factual decision routines used by participants much more uniformly and much better than the model in which the fact that a specific target was achieved, was used as a routine. This indicates that participants use information on the degree of achievement, rather than ticking of whether a specific target was met or not, to produce their evaluations.
We argued in hypothesis 3 that actors with certain cognitive styles, such as the tendency to rely on intuition and spontaneity, establish their routines less strongly than actors, who tend to rely on explicit consideration and cognitive effort. In order to test the hypothesis, we regressed the degree to which the routine was established in the first ten rounds, the last ten rounds, and all twenty rounds on indicators of the participants’ cognitive styles. As indicators of the cognitive style of the participant, we used items from need for cognition/faith in intuition battery (Epstein et al., 1996), combined with demographic information and information on the job experience and experiences with the usage of key performance indicators, see Appendix A. Findings (not reported) on coefficients and explanatory power indicate that there is no significant effect of the cognitive style or demographic information on the establishment of decision routines. Thus, there is no support for hypothesis 3.
So far, the findings indicate routinized information aggregation, as the behavior can be reconstructed very well using a simple linear-additive model, which is oriented at the school marks model of evaluations. Furthermore, the degree to which the routine is established seemingly increases over time. Estimating the mean R2 of the linear-additive heuristic using bootstrapping estimation with 1000 repetitions yields an estimate R2 for all 20 cases of 0.736, with a 95% Confidence Interval (CI) from 0.715 to 0.758. For the last ten cases, the fit is significantly higher, with an estimated mean for R2 of 0.870 and a 95% CI from 0.850 to 0.890. The evaluative decisions are highly structured and decisions occurring latter in the series are even more structured.
However, a more detailed look gives interesting insights. In order to further inquire into the stability of decision routines, we compare the routines as established for the first ten and the last ten cases, focusing on the linear-additive model, which fit best to the data. If hypothesis 2 on the increasing establishment of a decision routine is correct, the routine should become more established over time and it should also feature a stable functional form. This implies, that the explanatory power of the routine increases over time and in particular, that the form of the routine, i.e., the regression equation, remains stable and converges to a more fixed form.
Using the linear-additive routine based on sales targets, customer satisfaction, price targets, vocational training, decision number and gender of subordinate, for all twenty evaluations yields an average R2 of 0.74. However, looking only at the first ten evaluations, the model already yields an R2 of 0.86, while the last ten evaluations also yield an R2 of 0.87. Thus, considering the level of the sample, the linear-additive routine seems to fit basically right from the start. However, if this is the case, why is the fit of the model for all twenty cases below the value for the sub-samples of evaluations?
If the establishment of routines really follows a pattern of increasing establishment, the explanatory power of the routine should increase at the group and at the individual level. To test for this, we computed the change in the explanatory power (R2) for the first ten evaluations and the last ten evaluations for each participant in the study (R2 change = R2 last 10 cases – R2 first 10 cases, with positive values indicating that the routines becomes more established). If there is an increasing establishment of the routine, all changes should be positive, i.e., the R2 should be for all or at least most actors be higher in the last ten cases than for the first ten cases. Overall, there seems to be little change: The mean in the change of the explanatory power is 0.006, which is to say, at the group-level the routine appears to be stable. However, this is misleading. Fig. 2 gives the distribution of the changes in the R2 for the 160 participants.
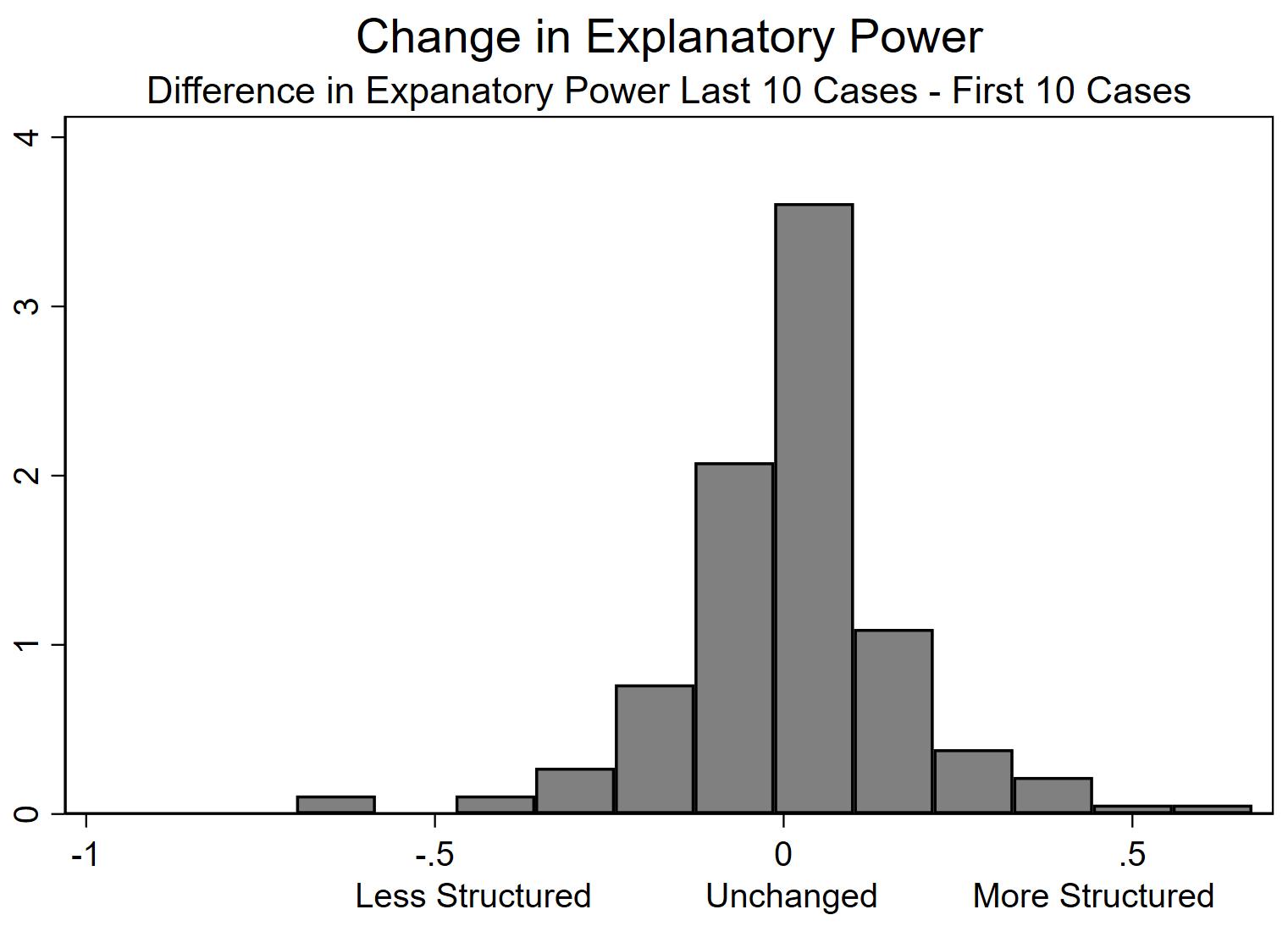 Fig. 2.
Fig. 2.
Learning or unlearning decision routines?
Fig. 2 indicates that there are changes from –0.699, implying that an initially structured participant became basically random, to +0.672, implying that a participant started out evaluating randomly but became highly structured over the course of the task. Furthermore, changes in the degree to which behavior is structured is by no means a rare event: 71 participants feature a less structured behavior in the last ten rounds than in the first ten rounds. Thus, for a substantial number of participants, there does not occur learning, but the opposite. Their behavior became less, not more, structured. This makes the notion of continuous establishment of a decision routine highly questionable.
In terms of how the changes can be explained, none of the demographic or cognitive control variables used in the study can account for this phenomenon. Neither if we consider the change as such, nor if we consider the absolute amount of change.
The substantial changes occurring at the level of the routine’s relevance also occur at the level of the weights extracted for a specific performance indicator from the evaluative behavior of the participants, see Table 3.
| Variable | Mean | Standard Deviation (Std. Dev.) | Min | Max | 95% Confidence Interval (CI) | |
| Lower | Higher | |||||
| Change Sales | 0.069 | 0.502 | –1.639 | 2.251 | –0.010 | 0.147 |
| Change Customer | 0.003 | 0.590 | –2.219 | 1.994 | –0.089 | 0.095 |
| Change Price Targets | –0.001 | 0.486 | –1.758 | 1.207 | –0.077 | 0.075 |
| Change Training | 0.044 | 0.539 | –1.710 | 3.450 | –0.040 | 0.129 |
| Change Decision Number | –0.017 | 0.857 | –2.526 | 3.163 | –0.151 | 0.117 |
| Change Male Subordinate | –0.014 | 0.459 | –1.943 | 1.332 | –0.086 | 0.058 |
Note: Change in the coefficients defining routines as obtained from the first and last ten evaluations.
At the level of the coefficients, the picture is the same as when considering changes in explanatory power: Overall, the coefficients appear to be stable, the measures of change feature means close to zero. The fact that the confidence intervals all contain zero is indicative that no coefficient systematically gains relevance over time. However, participants assign very different weights to the four indicators over the course of the task, with the importance of a specific performance indicator changing substantially from the first to the second set of evaluations.
While the overall picture obtained shows evidence of routinization, the more detailed picture shows that it is not the case but an effect of the aggregated view. It is not the case that all participants develop a routine, to which some participants abide more, other participants less, which would account for differences in explanatory power among participants. Instead, participants establish, but then change their routines, assigning over the course of the experiment more weight to some information and less to other. Seemingly, no changes occur but analyzing the situation only at the level of the sample underestimates the individual-level change occurring in all aspects of the routine. At the level of the whole sample, there is seemingly stability. But this is an artifact, as there is no stability at the level of the individual participant. Thus, while one might still argue that routines come into existence (as argued in hypothesis 1), hypothesis 2 cannot be supported in the light of the more detailed results.
The usage of performance evaluation as a means of management control, in particular the usage of the BSC approach, rests on the idea that the behavior of managers when rating subordinates is to some degree structured. Managerial discretion is accepted, but if the performance evaluations are changeful or random, subordinates do not know, what to do in order to achieve a high performance evaluation, the feedback is uninformative (Lechermeier and Fassnacht, 2018) and trust between manager and subordinate is reduced (Hartmann and Slapničar, 2009). Thus, the role of performance evaluation as an instrument of management control hinges on the existence of a decision-making routine, in which similar performance leads to similar evaluations. Existing research on performance evaluation is focused on biases (Bol, 2011; Bouwens et al., 2022), with the aim of providing advice to firms to structure their performance evaluation in a way which actually useful for the purposes of management control. While not actually stating or testing it, the central assumption is that the evaluative behavior of managers follows some routine, which may be biased, e.g., by affect. The lack of consideration paid to the existence of the presumed routines was criticized early on (Kravitz and Balzer, 1992), but not yet addressed. The issue is of high practical relevance, as the assumption of structured decision-making and routines also applies to all other fields of managerial decision-making.
We put the implicit assumptions on routines in the focus of our paper, stating as basic hypotheses that routines exist and are established over time. Using the standard procedure to extract the routines developed in psychology (e.g., Taylor and Wilsted, 1974), we find prima facie at the aggregate level strong support for the existence and increasing establishment of routines. Given that routines are seemingly established even after only ten evaluations, one might furthermore conclude that routines are established quickly. All of this is in line with arguments made earlier on that linear-additive models describe decision behavior quite well (most prominently, Dawes, 1979). However, while arguing that these routines appropriately describe repeated behavior, these studies usually analyzed single decisions from multiple persons, not multiple decisions from the same persons. A closer investigation addressing this gap gives evidence that routines are not stable. Stable routines seem to emerge when the level of the overall sample is considered. At this level, a decision routine, which is structurally similar to the grading of school marks, fits the evaluative behavior of participants very well and the fit is higher in the latter stages of the study, indicating a progressive establishment of the routine. One may indeed conclude that the school-marks routine is how evaluations are produced, in particular if one makes some allowance for problems in mentally computing the exact evaluation. However, this is observation an artifact. Considering the individual level, we find no evidence of stable routines, as some individuals become structured over time while others become random over time. Nor do we find evidence of routine stability in terms of the specific elements of the routine: A performance measure may be relevant for the first ten evaluations, but become irrelevant for the next ten evaluations.
Our findings are subject to some limitations. It may well be the case that due to the student sample the behavior of participants is less structured than the behavior of real managers doing periodic evaluations. However, there is long standing evidence that in general, behavior of managers and students is comparable (Remus, 1986; Jones and Davidson, 2007; Graf-Vlachy, 2019) and that latter are a valid proxy for the former (Kees et al., 2017). In particular, as the task we employ in the study does not require specific knowledge like accounting rules or experience with procedures occurring in business practice. Given that performance evaluations occur periodically, but with large temporal gaps, one may also argue that the change in the routine is even larger if there are lager gaps between rounds of evaluations: A manager may establish different routines for evaluations done in different periods. A study including an interim period between two series of evaluations could address this issue. In terms of the functional form of the routine—the linear-additive model was found to fit best—it may well be the case that this routine dominates among students, as they themselves are evaluated that way and were so during their school days. However, the linear-additive aggregation of information is widely spread, thus it is widely known and it may well be the case that it serves as a general template for evaluations.
The study has implications for managerial practice and research. In terms of managerial practice, the implementation of BSC-based performance evaluation pursues the aim that subordinates receive valid feedback and can adapt their behavior accordingly, for the good of the firm. Basically, this is crucial to the function of performance evaluations in the management control setting (Ittner and Larcker, 1998; Libby et al., 2004; Dai et al., 2018). Fulfillment of this function hinges on the degree that the evaluative behavior of managers is to some degree predictable and stable, allowing the evaluated subordinates to infer which aspects of their activities matter most for their line manager and therefore the firm. If this is true, a routine can be extracted from the evaluations and this routine should be stable. As it is, the findings indicate that how performance evaluations are made, is much less stable than presumed. Managers may use different procedures over the course of an evaluation task, where many subordinates are to be evaluated. In our study, some participants had a procedure for the first ten cases, but another one for the next ten. This implies, that if evaluations are done periodically, say, quarterly, the procedure by which an evaluation is produced may change between periods. From the perspective of the subordinate, what was important for getting a positive performance evaluation at one point in time may be irrelevant in the next round of evaluations. In this situation, the subordinate is at loss as to what to do.
In terms of research, specifically on performance evaluation, the functional form of the linear-additive school mark model together with the absence of an effect of the participants’ cognitive styles on the development or stability of routines is in our view indicative of activating a pre-existing routine, rather than of creating a routine from the scratch.
The sharp contrast to the results of research on routines in other domains—like the choice of a means of transportation, a route to a location, but also in situations, where actors pursue personal preferences (Betsch et al., 1998; Bargeman and van der Poel, 2006)—may be due to the fact that in the situation of performance evaluation, actors have to choose a rule to produce an output, rather than an output. This situation is more complicated and abstract than the settings constituting typical applications of research on routines, heuristics or habits.
In terms of performance evaluation research and its focus on biases, these findings put the results on the relevance of biases in perspective. It may well be the case that if information is presented in a certain format, effects on the evaluations result. But it may also be that the observed changes in the evaluations are due to changes in the decision routine, which occur spontaneously. By its very notion, a bias is a deviation from some reference. The reference may be the normatively correct, “rational” solution or the standard reaction of the actors involved. Our findings indicate that there may be no such thing as a stable reference to determine existence and magnitude of a bias in repeated decision-making.
While performance evaluation of employees is a standard setting for the analysis of biases and routines, our findings apply also to other settings, like the assessing the motivation of potential employees (see Grund et al., 2019), and to the inverse situation, where employees evaluate employers (see Cloos, 2021). The former case differs only insofar as the content of the evaluation differs, the latter differs in the assigned roles. Still, routines are assumed on the side of the employees doing the evaluation, in the sense that they have a stable mental routine by which to evaluate a job or an employer.
The findings also draw attention to the problem of replication, as the randomness of the evaluations and the constant change in the routine by which participants tackle the task increase the (random) variation in evaluative behavior, making it harder to identify replicable effects: In particular in repeated evaluative decisions, participants may give a different evaluation, not because of a bias, but because they changed their routine during the study. In terms of experimental methodology, these findings imply strongly that one-shot settings should be avoided.
The data is not in a repository, but available on request.
PK and KAB designed the research study. PK and KAB performed the research. PK and KAB analyzed the data. Both authors contributed to editorial changes in the manuscript. Both authors read and approved the final manuscript. Both authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
Not applicable.
Peter Kotzian gratefully acknowledges financial support from the Jürgen Manchot Foundation Düsseldorf.
The authors declare no conflict of interest.
Decision Certainty Index
I am often unsure of my judgment.
I always know exactly what I’m going to decide something in a certain way.
I study the various pieces of information carefully before making a decision.
Need for Cognition Index
I don’t like to be responsible for a situation that requires a lot of thinking.
I try to anticipate and avoid situations in which there is a high probability that I will have to think intensively about something.
I would rather do something that is sure to challenge my thinking skills than something that requires little thinking.
I prefer complex problems to simple problems.
I find little satisfaction in thinking hard for hours.
Faith in Intuition Index
I trust my immediate reactions to others.
I think I can trust my feelings.
My first impressions of others are almost always correct.
When the question is whether to trust others, I usually make gut decisions.
Most of the time, I can tell whether a person is right or wrong, even if I can’t explain why.
All variables are 7-point Likert scales, ranging from 1 “not appropriate at all” to 7: “fully appropriate”, and were combined to additive indices.
Demographics and Job Experience
semester In which semester of your studies are you currently in? (Semesters)
job How much work experience (also as a Trainee, intern or working student, etc.) do you have? (Months)
gender Gender of Participant (1 Man 2 Woman)
age How old are you (Years)
kpi-ability I feel secure when dealing with KPIs (7-point-Likert-Scale; 1 “not appropriate at all”; 7: “fully appropriate”)
kpi-job How much practical experience do you have in dealing with KPIs (e.g., in an internship)? (Months)
mothertongue Is German your mother tongue? (1 yes 2 no)
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.