






1 School of Software, East China Jiaotong University, 330013 Nanchang, Jiangxi, China
Academic Editor: Leyi Wei
Abstract
Introduction: Alzheimer’s disease (AD) is the most common progressive neurodegenerative disorder in the elderly, which will eventually lead to dementia without an effective precaution and treatment. As a typical complex disease, the mechanism of AD’s occurrence and development still lacks sufficient understanding. Research design and methods: In this study, we aim to directly analyze the relationship between DNA variants and phenotypes based on the whole genome sequencing data. Firstly, to enhance the biological meanings of our study, we annotate the deleterious variants and mapped them to nearest protein coding genes. Then, to eliminate the redundant features and reduce the burden of downstream analysis, a multi-objective evaluation strategy based on entropy theory is applied for ranking all candidate genes. Finally, we use multi-classifier XGBoost for classifying unbalanced data composed with 46 AD samples, 483 mild cognitive impairment (MCI) samples and 279 cognitive normal (CN) samples. Results: The experimental results on real whole genome sequencing data from Alzheimer’s Disease Neuroimaging Initiative (ADNI) show that our method not only has satisfactory classification performance but also finds significance correlation between AD and RIN3, a known susceptibility gene of AD. In addition, pathway enrichment analysis was carried out using the top 20 feature genes, and three pathways were confirmed to be significantly related to the formation of AD. Conclusions: From the experimental results, we demonstrated that the efficacy of our proposed method has practical significance.
Keywords
- Unbalanced data
- Multi-class classification
- Multi-objective optimization
AD is a neurodegenerative disease with a high incidence and possesses enormous threaten to elderly people, leading cause of memory loss and even dementia [1]. Early accurate diagnosis and effective preventive measures can delay the development of the disease. The diagnostic techniques of AD, such as cognitive testing [2], neuroimaging [3, 4], biomarker detection [5, 6, 7] and genetic variants detection [8, 9] and so on, have different advantages and disadvantages and all of them are constantly developing. Researchers believe that identify the causal genetic variations and understanding their underlying molecular mechanisms not only play important role in early diagnosis, but also may help for designing innovative medicine for the AD.
Genome-wide association studies (GWAS) as a data-driven strategy have been
applied to locate genetic variants contributed to the risk of complex diseases.
So far, thousands of risk sites have been reported to be associated with complex
diseases and traits. The GWAS Catalog collects the findings of all high-quality
published GWAS literatures, which provides prior knowledge for investigators
[10, 11, 12, 13]. However, GWAS faces two enormous challenges, namely reproducibility and
heritability. For example, factors, such as sample scale, study cohorts,
sequencing technology, statistic techniques and so on, can significantly
influence the results of GWAS. Therefore, different studies may come to different
conclusions, or even completely conflicting conclusions about genetic variants
involvement in the complex disease onset and progression, which result in lack of
reproducibility. Another challenge is that the uncovered susceptible variants
only account for a limited proportion of the heritability for each complex
disease [14, 15, 16, 17, 18, 19]. For example, multiple common and rare variants have been
reported to be associated with AD [20]. Although the APOE
To accurately identify the risk loci of AD, imaging genetics studies use neuroimaging endophenotypes to fill the gap between DNA variants and AD [23]. With using this potential strategy, FRMD6 was firstly considering to be associated with AD by leading to hippocampal atrophy [24]. Although this kind of strategy has achieved some success, it has two main limitations. One is that although the identified risk site is related to regions of interest (ROI), it does not mean that it is related to AD. The other is that the association analysis between multiple loci and multiple ROIs across the whole genome will greatly increase the computational burden.
In this study, we conduct a whole genome analysis for ADNI based on
multi-classifier XGBoost [25, 26, 27, 28], aiming to design an effective diagnostic
method only with genome information and identify potential risk loci. The merits
of our work is reflected in three points: firstly, in order to improve the
interpretability of the study and reduce false positives, VEP [29] mutation
annotation software is used to screen risk SNPs from the whole genome, and
secondly, our method directly predicts the outcomes only with genome variants
information, which avoids the defect that the variation identified by imaging
genetics method is not strongly associated with individual phenotype; Finally,
with using XGBoost, our method can accurately recognize the MCI samples and our
method further validates that the RIN3 has the strongest correlation to
AD and pathway enrichment analysis results with the top 20 genes show that three
pathways (Pyruvate metabolism, Glycine, serine and threonine metabolism and ABC
transporters) are significant (p-value
Whole genome sequencing always derives millions of SNPs which can be partitioned into categories such as missense variants, synonymous variants, driver variants, passenger variants and so on. It means that not all of them are deleterious to gene function, let alone pathogenicity. The VEP tool can determine which genetic variants are deleterious with using SIFT scores [33]. Based on the sequence homology and physical properties of amino acids, SIFT evaluates the effect of each amino acid substitution on protein function.
In this study, we download the whole genome sequencing VCF files from the ADNI
database (adni.loni.usc.edu) [34], which contains 809 samples and each sample
holds over 388 million SNPs by the Ilumina Omni 2.5 M BeadChip. To enhance the
biological meanings and reduce the computational burden for downstream analysis,
we use VEP to filter variants (IMPACT is HIGH or IMPACT is MODERATE and SIFT
16163 genes derive a huge combinatorial space, resulting in enormous challenge for optimization. Therefore, a reasonable way is to filter 16163 genes at the beginning. Since our purpose is to identify which genes are pathogenic for AD, intuitively we can evaluate each gene according its correlation to phenotypes. In this study, the CN samples are labeled as 0, the MCI samples are labeled as 1, and the AD samples are labeled as 2. Multi-objective optimization technique has been wildly used in various area [35, 36]. To enhance the robustness of our method, a multi-objective technique is proposed to filter out redundant and irrelevant genes. Here, we separately design two complementary objectives, which results in removing the genes that are highly correlated to other genes and have low correlations to phenotypes.
The uncertainty of the phenotype Y can be quantified by Shannon entropy H(Y) as Eqn. 1.
where p(y
Joint entropy of a single gene and phenotype Y can be defined as Eqn. 2. Let X be a gene with three kinds of values (0, 1 and 2) as mentioned above.
Then, we use mutual entropy I(Y
We believe that a pathogenic gene shows significant difference across groups and should relatively consistent in MCI and AD samples. For objective 2, two components are designed for evaluating each gene. The first component uses entropy H(X) to select genes with consistent pattern (CP) in MCI and AD samples as Eqn. 4.
where H
In addition, the significant difference (SD) across groups of the pathogenic gene can be defined by their normalized frequencies as defined in Eqn. 5. Note that the gene value ‘0’ means its function is normal, ‘1’ means its function moderate damaged and ‘2’ denotes highly damaged.
where X
In this study, we download 809 VCF files from ADNI. Out of 809 samples, 808 samples include 279 CN samples, 483 MCI samples and 46 AD samples and the remaining one’s disease state cannot be addressed, so that it was discarded.
XGBoost implements parallel tree boosting technique in a portable and efficient way [25] and it provides various packages such as R, Python, Ruby and so on. XGBoost help researchers to solve classification problem in an easy-use, friendly way. In this study, we use the R package of XGBoost. Before running XGBoost, several parameters should be addressed according to specific task. In Table 1, the important parameters are listed.
| Parameter | Value |
| booster | gbtree |
| eta | 0.03 |
| max_depth | 6 |
| gamma | 3 |
| objective | multi:softprob |
| subsample | 1 |
| num_class | 3 |
Data used in our study were downloaded from the ADNI database. The ADNI was initiated in 2003 and was built in three phases: ADNI-1, ADNI-2 and ADNI-GO. ADNI collects several types of data (e.g., clinical, genetic, MRI image, PET image and biospecimen) from volunteers (over 1500 adults recruited from the U.S. and Canada, ages 55 to 90), using strict protocols and procedures to ensure consistencies. The primary goals of ADNI are to find out an effective early diagnosis technique, understand the molecular mechanism of the onset and progression of MCI and AD and eventually design new medical and treatments. The ADNI More up-to-date information can be found on www.adni-info.org. In this study, we collected 809 VCF files recalled by CASAVA pipelines. Except only one sample has no information about disease state, other 808 samples can be partitioned into 483 MCI samples, 279 CN samples and 46 AD samples.
At the beginning, each sample carry about 388 million SNPs. After VEP filtration, each sample only holds variants which are deleterious. Then, the protein coding genes corresponding to deleterious SNPs are encoded as ‘1’ when IMPACT is MODERATE and as ‘2’ when IMPACT is HIGH and the rest are ‘0’. In total there are 16163 genes, so that it would cost an enormous computational burden for downstream analysis. After the filtration step based on multi-objective criterion, a matrix derived contains 808 samples and 866 genes, which n equals to 808 and p is 866 as shown in Fig. 1.
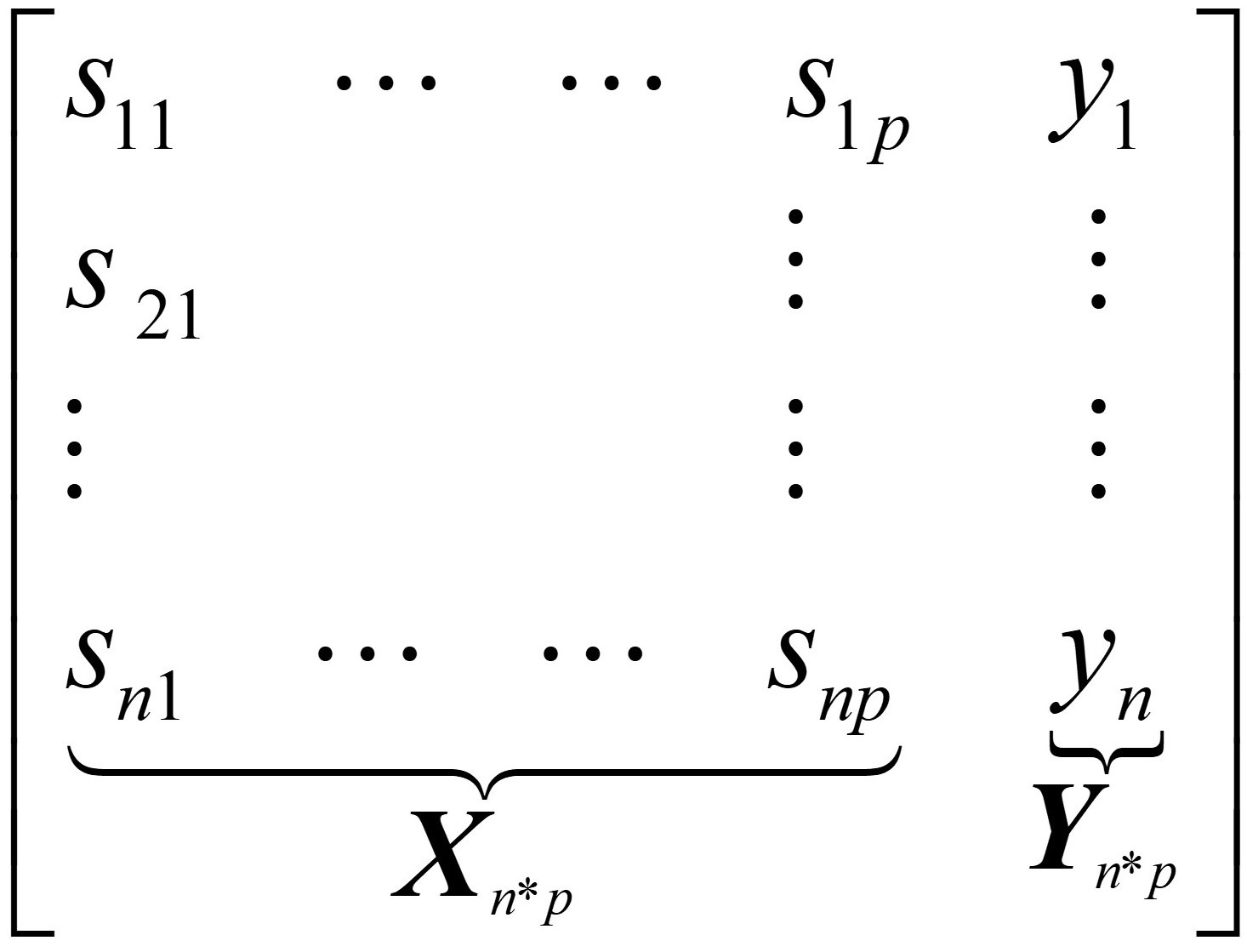 Fig. 1.
Fig. 1.Data formulation.
In this study, we directly predict the sample state (AD, MCI and CN) only with gene function state (0, 1 and 2). Thus, it can be considered as a 3-class classification problem. However, the number of AD samples is significantly smaller than AD and CN samples, so that it is a typical unbalanced data.
Our primary goal is to design an early diagnosis method of MCI and AD. Of note, the accurate identification of MCI and AD is more meaningful than identifying CN samples. Consequently, we use both accuracy (Acc) and sensitivity (Sen) measures to fairly evaluate our method as defined in Eqns. 7 and 8.
In addition, the cross-validation strategy, sometimes called out-of-sample testing, is to test the generalization ability of a classifier. Here, we apply 10-folds cross validation which divides all the 808 samples into 10 parts. Each iteration 9 equal parts are used as the training set, and the remaining part is used as the test set, repeating 10 times in total. The 10-folds cross validation give an insight on how the classifier will generalize to an unknown samples and flag overfitting and model bias issues. Note that, the proportion of different labels in each part is the same as that of the original data, that is, it is still unbalanced in each iterations.
To demonstrate the classification performance and biological meanings of our method, we analyze the experimental results in prediction accuracy, feature importance and pathway enrichment.
To demonstrate the advantages of XGBoost on unbalanced data, we compare the results of XGBoost with Logistic Regression (LR). LR has been widely used in various research fields, such as bioinformatics, social science applications and so on. LR can be divided into two categories: binary LR and multinomial LR. The former is specific for the categorical response has only two possible outcomes, while the latter is suitable for three or more categories without ordering.
In Fig. 2, the horizontal axis represents 10 independent test sets of 10-folds cross validation. We can find that in almost all test sets, the XGBoost method is better than the LR method. The lowest accuracy of XGBoost is 0.68 and the highest accuracy of XGBoost is 0.79. On average, the accuracy of XGBoost is 0.73.
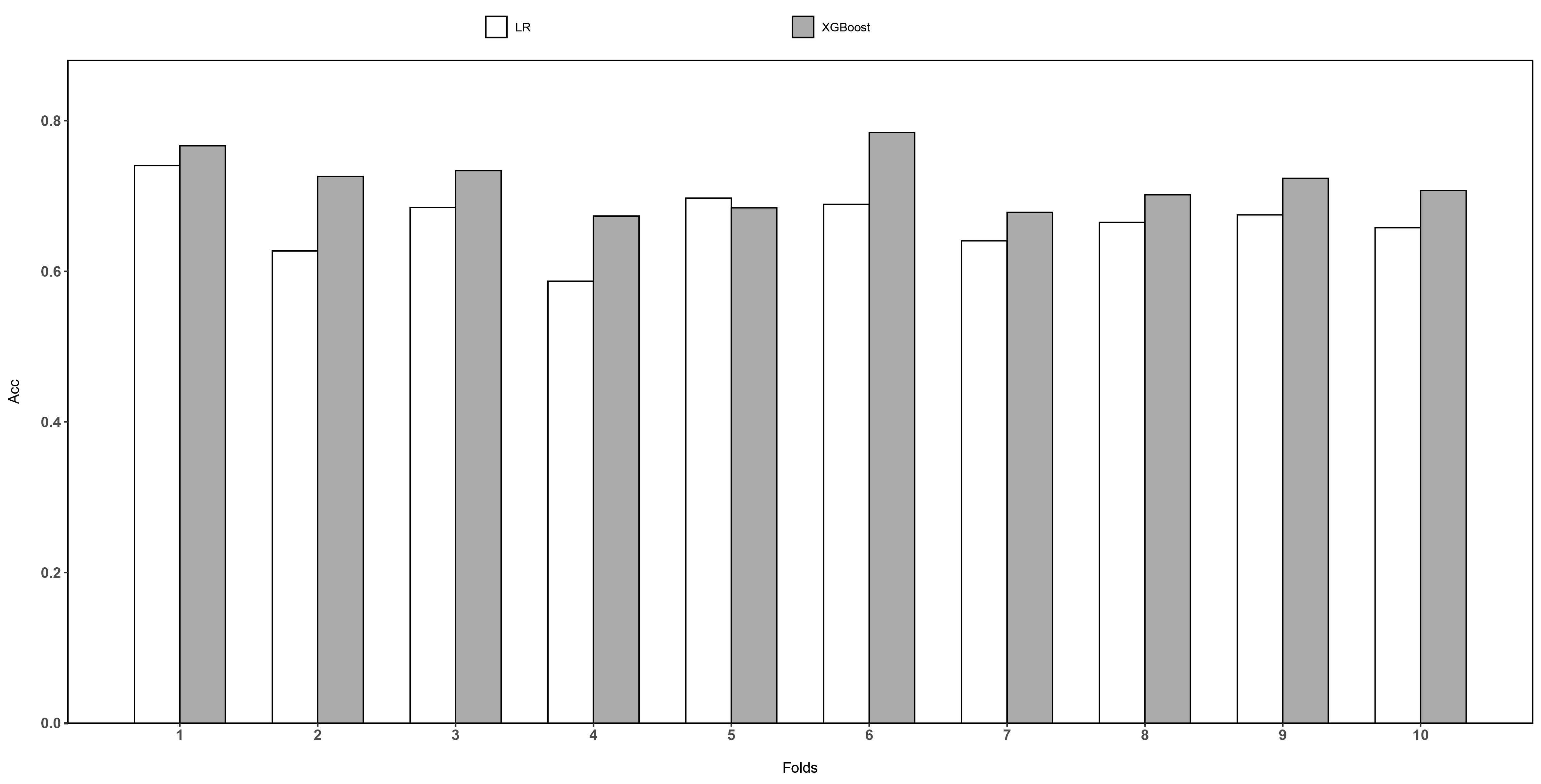 Fig. 2.
Fig. 2.The results of XGBoost and LR on accuracy.
In Fig. 3, XGBoost and LR have the completely same sensitivity on all test sets. For the 7th test set, all AD samples are not correctly identified by XGBoost or LR, while for the 1th test set, the sensitivity of both XGBoost and LR reach 0.8. It can be seen that too few AD samples cause the classifier to lack information to correctly distinguish AD samples from other samples.
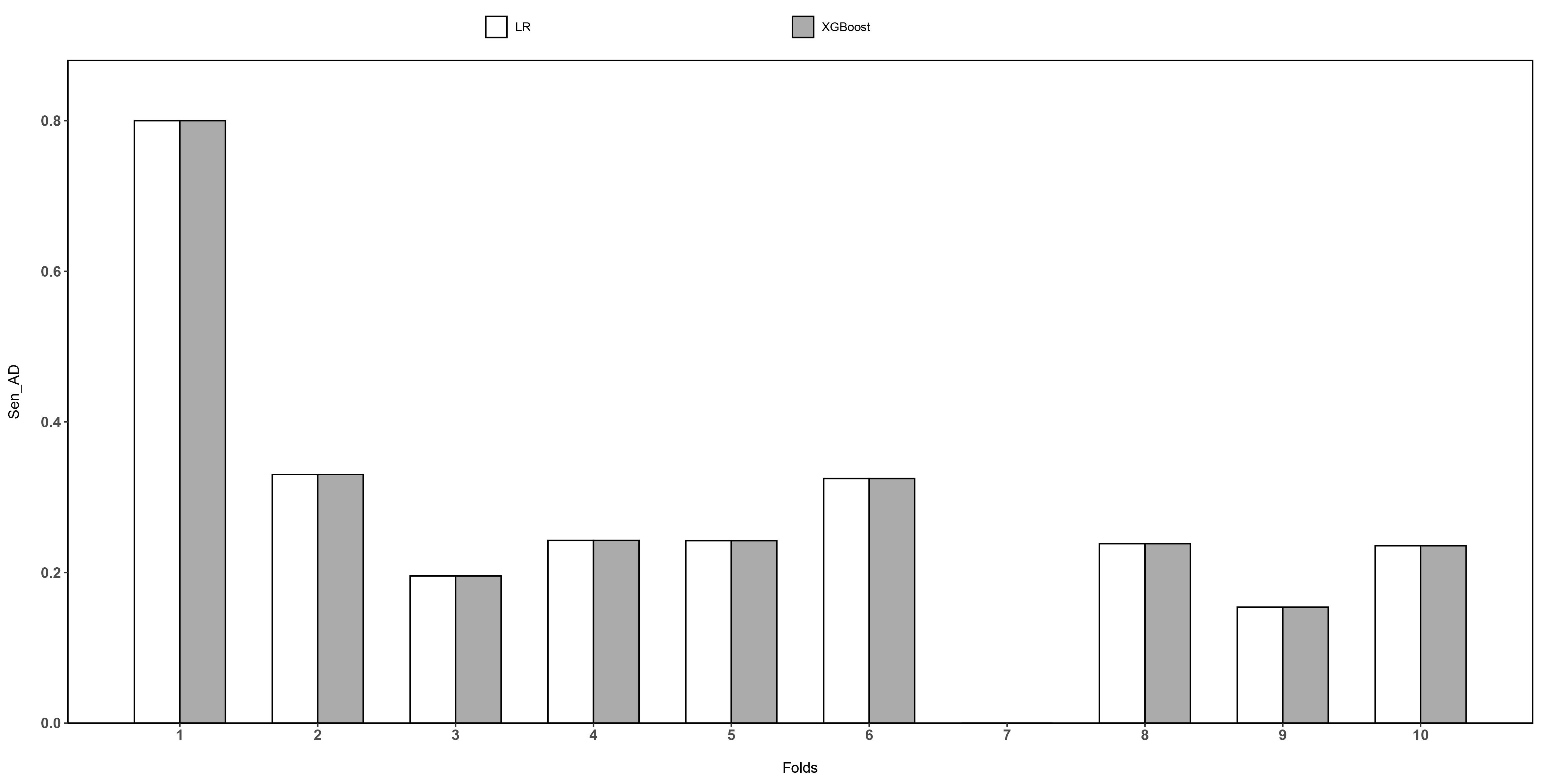 Fig. 3.
Fig. 3.The results of XGBoost and LR on sensitivity of AD.
In Fig. 4, the results show that XGBoost has better sensitivity of MCI than LR in all test sets. The lowest and highest results of XGBoost are 0.94 and 1.0, respectively. On average, the XGBoost’s sensitivity of MCI is 0.97. These results demonstrate that XGBoost can accurately capture the characteristics of MCI samples, which would significantly for early diagnosis.
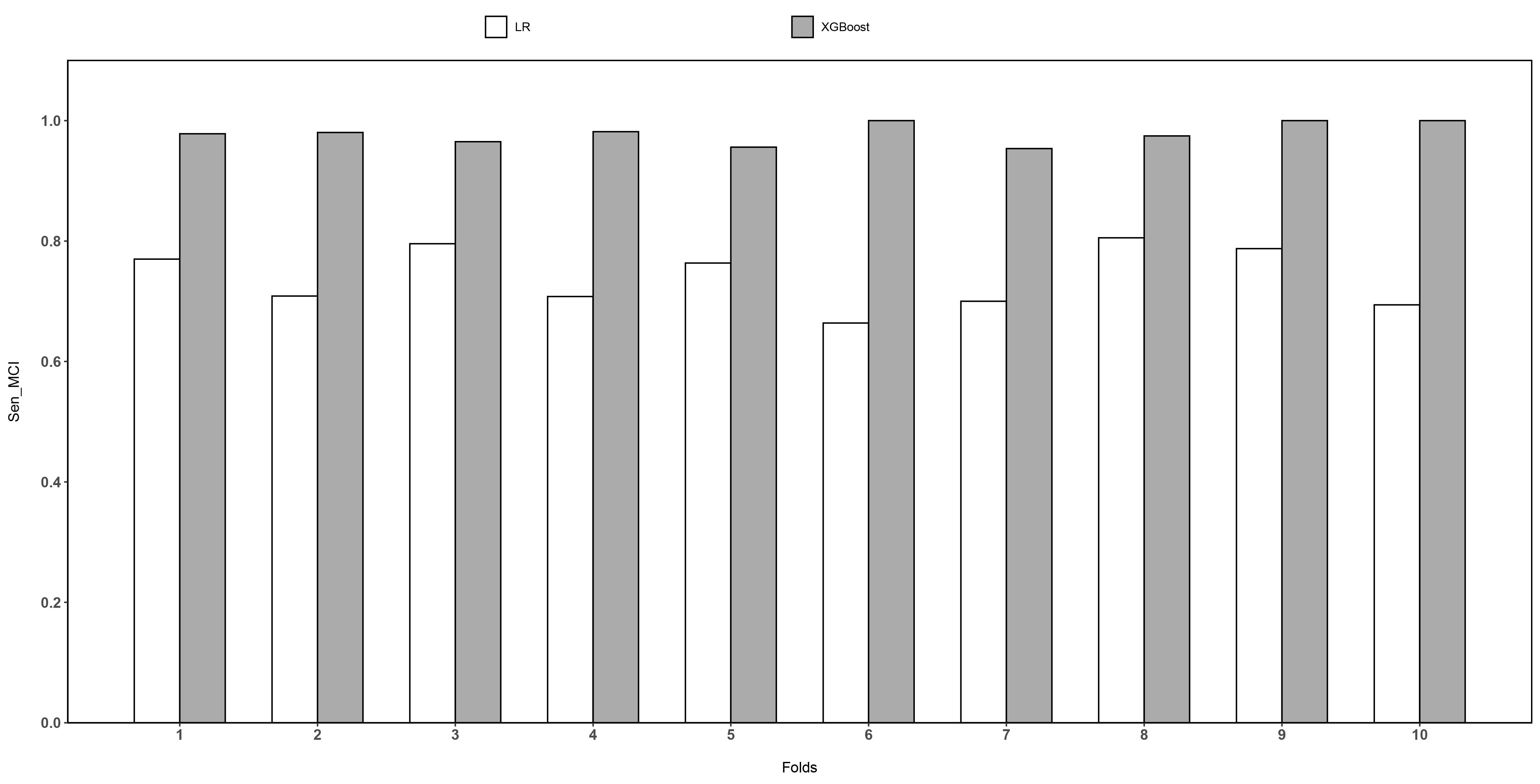 Fig. 4.
Fig. 4.The results of XGBoost and LR on sensitivity of MCI.
XGBoost classifiers samples in a decision tree ensembles manner. During the model training, each feature (gene) is evaluated by information gain which results in a rank of feature importance as shown in Fig. 5.
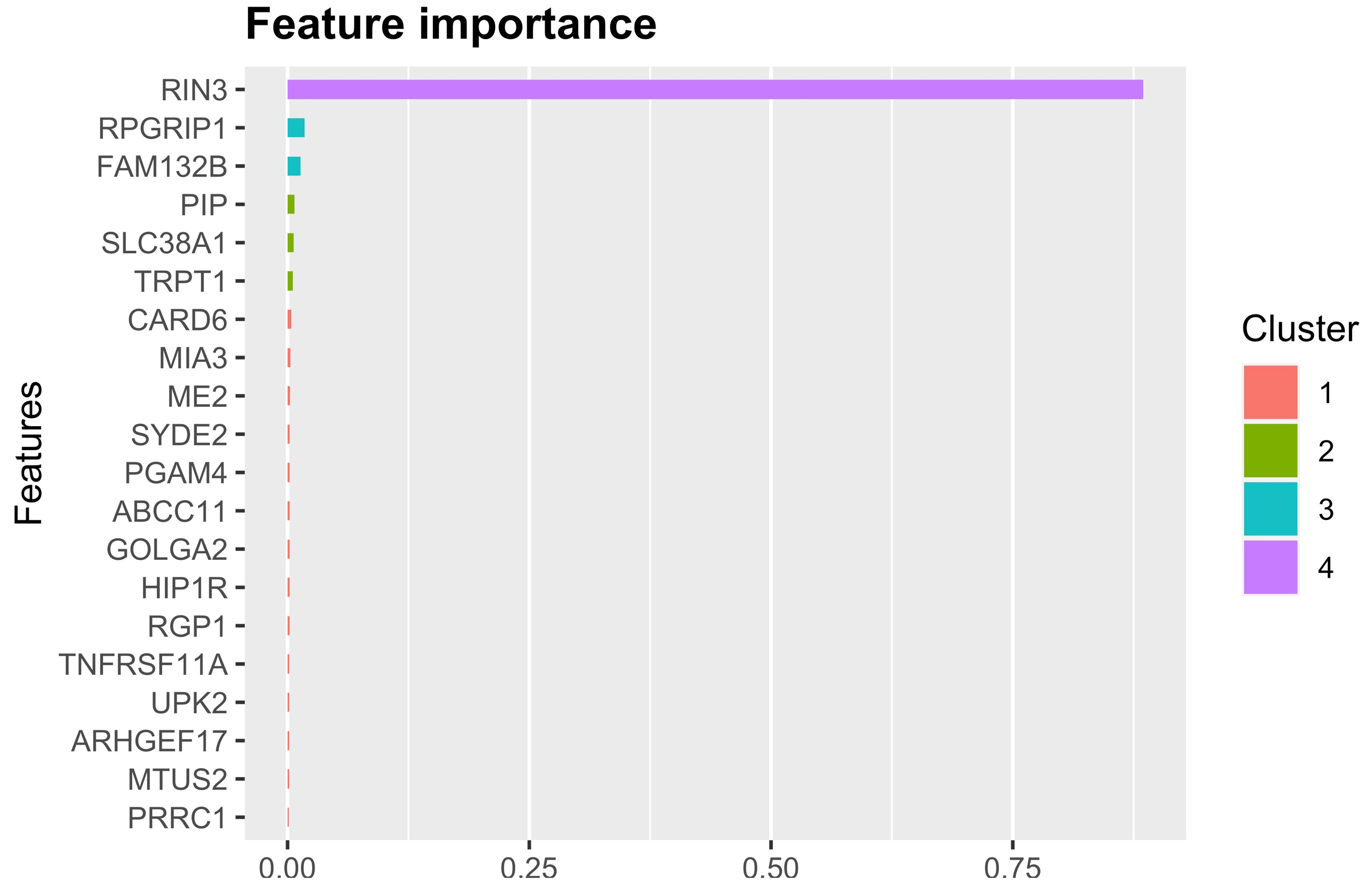 Fig. 5.
Fig. 5.The importance of top 20 features.
In Fig. 5, top 20 features, namely genes, are ranked according to their contributions in classification. Rab Interactor 3 (RIN3) is the most important feature than others. RIN3, a guanine nucleotide exchange factor (GEF) for the Rab5 small GTPase family, has been reported to be associated with both late onset AD (LOAD) and sporadic early onset AD (sEOAD) [37]. Shen et al. [38] validated that the upregulation of RIN3 induces endosomal dysfunction in Alzheimer’s disease, which provides a deeper understanding of how RIN3 affects AD pathogenesis. In addition, the GWAS Catalog 2019 also shows that RIN3 is a risk factor to the LOAD (p-value = 0.06682 and Odds Ratio = 15.63).
In further, we use the top 20 genes (RIN3, RPGRIP1, FAM132B, PIP, SLC38A1, TRPT1, CARD6, MIA3, ME2, SYDE2, PGAM4, ABCC11, GOLGA2, HIP1R, RGP1, TNFRSF11A, UPK2, ARHGEF17, MTUS2 and PRRC1) to conduct a pathway enrichment analysis by KEGG 2019 Human in Enrichr [39].
In Table 2, the enrichment analysis results of three pathways with
p-value
| Name | p-value | Odds ratio | Combined score |
| Pyruvate metabolism | 0.03830 | 25.64 | 83.65 |
| Glycine, serine and threonine metabolism | 0.03927 | 25.00 | 80.93 |
| ABC transporters | 0.04407 | 22.22 | 69.38 |
In this study, we introduced a framework for annotating whole genome variants
and predicting Alzheimer’s disease based on multi-classification: firstly, we use
VEP to annotate the impact consequence of all single nucleotide polymorphism
(SNP) and identify deleterious SNPs. After that, we map all these deleterious
SNPs to nearest genes and design a multi-objective criterion to evaluate each
protein coding gene. Finally, we apply a XGBoost for multiclass classification.
From the experimental results on real whole genome sequencing data, we can find
that our method achieves satisfactory classification performance. In addition,
our method further validates that the RIN3 has the strongest correlation
to AD. Moreover, we use the top 20 genes to carry out pathway enrichment analysis
and three pathways (Pyruvate metabolism, Glycine, serine and threonine metabolism
and ABC transporters) are significant (p-value
Our method has several advantages: Firstly, unlike previous studies, our method predicts the sample outcomes according to the degree of damage to gene function. The function loss of gene annotated by VEP can be MODERATE or HIGH caused by SNPs, which enriches the biological meanings of our study; Secondly, our method directly predicts the outcomes only with genome variants information, which avoids the defect that the variation identified by imaging genetics method is not strongly associated with individual phenotype; Finally, our method filter the redundant and irrelevant SNPs by multi-objective evaluation, which significantly reduces the computational burden of classification model training. In addition, our method can accurately recognize the MCI samples, so that it would play important role in early diagnosis.
With using the feature importance evaluated by XGBoost, we find that the damage
of RIN3 gene function is significantly associated with the development
of AD. This finding also has been proved by previous studies. Moreover, we
examine the top 20 genes for pathway enrichment analysis. These genes enrich in
Pyruvate pathway, Glycine, serine and threonine metabolism pathway and ABC
transporters pathway with p-value
The computational framework of our work has made some progress, but there are still deficiencies to be improved in future work. The limitations are as follows:
(1) Concerning the filter parameters (IMPACT is HIGH or IMPACT is MODERATE and
SIFT
(2) The occurrence and development of AD may not only be caused by SNPs, but also may be related to other mutations such as copy number variation. However, due to the data set analyzed and the computational framework designed in this work, the identified mutations or genes can only explain a part of AD/MCI samples. A more likely solution to this problem is that we will adopt the perspective of systems biology to supplement information from other levels of data (such as copy number variation, transcriptome, methylation, proteome and so on), and then integrate multi-level omics data to improve accuracy and sensitivity.
(3) XGBoost has certain advantages in classification on unbalanced data sets, but when the imbalance is very serious, its performance is still insufficient. In this work, the AD sensitivity of our method is low, because the sample size of AD is too small (only 46 AD samples). Further analysis revealed that this misclassification was mainly due to AD being wrongly identified as MCI, which indicates that the sample size is too small to accurately detect the pattern of AD. Therefore, in future research, we will study more effective sampling techniques or carry out larger-scale research to increase the sensitivity of the computational method.
JZ and XL carried out the design of the study and performed the statistical analysis.YPQ and XYL implemented the experiments and analyzed the results. YYP, SGL and ZRX participated in software coding and helped to draft the manuscript. All authors read and approved the final manuscript.
Not applicable.
Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: Alzheimer’s Association; Alzheimers Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen Idec Inc.; Bristol-Myers Squibb Company; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated com-pany Gen- entech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alz-heimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Medpace, Inc.; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technolo-gies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Synarc Inc.; and Takeda Pharmaceutical Company. The Canadian Institutes of Rev December 5, 2013 Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Disease Cooperative Study at the University of California, San Diego. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
This work has been supported by the Jiangxi Provincial natural science fund (Nos. 20192ACB21004, 20204BCJL23035, 20212ABC03A32, 20202BAB212004 and 20212BAB202007), MOE (Ministry of Education in China) Project of Humanities and Social Sciences (No. 20YJAZH142) and Technological Research Project of Education Department in Jiangxi Province (GJJ190356 and GJJ210624).
The authors declare no conflict of interest.