
 , Cong Chen 1,†, Junhang Jia 1, Jubing Zheng 1, Yue Song 1, Taoshuai Liu 1, Kui Zhang 1, Yang Li 1,*
, Cong Chen 1,†, Junhang Jia 1, Jubing Zheng 1, Yue Song 1, Taoshuai Liu 1, Kui Zhang 1, Yang Li 1,* , Ran Dong 1,*
, Ran Dong 1,*1 Center of Cardiac Surgery, Beijing Anzhen Hospital, Capital Medical University, 100000 Beijing, China
†These authors contributed equally.
Abstract
The narrow therapeutic range of warfarin, alongside the response of numerous influencing factors and significant inter-individual variability, presents major challenges for personalized medication. This study aimed to combine clinical and genetic characteristics with machine learning (ML) algorithms to develop and validate a model for predicting stable warfarin doses in patients from Northern China after mechanical heart valve replacement surgery.
This study included patients who underwent mechanical heart valve replacement surgery at the Beijing Anzhen Hospital between January 2021 and January 2024 and achieved a stable warfarin maintenance dose. Comprehensive clinical and genetic data were collected, and patients were divided into training and validation cohorts at an 8:2 ratio through random division. The variables were selected using analysis of covariance (ANCOVA). Algorithms for predicting the stable warfarin dose were constructed using a traditional linear model, general linear model (GLM), and 10 ML algorithms. The performance of these algorithms was evaluated and compared using R-squared (R2), mean absolute error (MAE), and ideal prediction percentage to identify the optimal algorithm for predicting the stable warfarin dose and verify its clinical significance.
A total of 413 patients were included in this study for model training and validation, and 13 important features were selected for model development. The support vector machine radial basis function (SVM Radial) algorithm showed the best performance of all models, with the highest R2 value of 0.98 and the lowest MAE of 0.14 mg/day (95% confidence interval (CI): 0.11–0.17). This model successfully predicted the ideal warfarin dose in 93.83% of patients, with the highest ideal prediction percentage found in the medium-dose group (95.92%). In addition, the model demonstrated high predictive accuracy in both the low-dose and high-dose groups, with ideal prediction percentages of 85.71% and 92.00%, respectively.
Compared to previous methods, SVM Radial demonstrates significantly higher accuracy for predicting the warfarin maintenance dose following heart valve replacement surgery, suggesting it has potential for widespread application. However, this study was based on a relatively small sample size and conducted at a single center. Future research should involve larger sample sizes and multicenter data to validate the predictive accuracy of the SVM Radial model further.
Keywords
- warfarin
- machine learning
- heart valve prosthesis implantation
- prediction model
Warfarin, the most commonly used vitamin K antagonist (VKA), is the preferred anticoagulant for patients undergoing mechanical heart valve replacement surgery. The 2020 updated American College of Cardiology (ACC)/American Heart Association (AHA) guidelines explicitly recommend VKA for the antithrombotic therapy in patients with mechanical prosthetic valves [1]. However, warfarin has several limitations, including a narrow therapeutic window, considerable dose variability between individuals, and the existence of numerous factors that can influence the anticoagulant effect. Incorrect dosing can increase the risk of bleeding and thromboembolic events, such as gastrointestinal bleeding, cerebral hemorrhage, deep vein thrombosis, pulmonary embolism, and stroke [2, 3, 4]. Therefore, accurate dosing of warfarin is crucial for the efficacy and safety of anticoagulant therapy, with individualized dosing needed to achieve optimal clinical outcomes [5].
Currently, anticoagulation therapy with warfarin usually follows an initial regimen of a fixed standard dose, followed by empirical dose adjustments by the clinician based on international normalized ratio (INR) values. However, before a stable maintenance dose is found, the incidence of anticoagulation-related adverse events such as bleeding and thromboembolism remains high, posing a threat to patient safety [6]. Additionally, patients require regular blood tests to monitor INR levels, which can be inconvenient and require high patient compliance [7].
Several researchers have used pharmacogenomics-based warfarin dosing models to develop new individualized dosing approaches. Most of these use multiple linear regression (MLR) equations with the warfarin therapeutic dose as the dependent variable, and genetic and non-genetic factors as independent variables. Notable examples include the International Warfarin Pharmacogenetics Consortium (IWPC) and Gage models [8, 9]. Although MLR models have been widely used for warfarin dose prediction, their predictive performance varies widely [8, 9, 10]. Validation results across different populations are often unsatisfactory, and their accuracy tends to be lower in specific subgroups. MLR does not take into account the inter-individual variability of warfarin and is unable to effectively utilize patient INR monitoring values for dose adjustments. Advances in research have established that a complex nonlinear relationship exists between the factors influencing warfarin and its dosage [11]. This renders MLR models unsuitable for accurately predicting the stable maintenance dose of warfarin, and more suitable models are required to optimize individual therapies. With the rapid progress in artificial intelligence, machine learning (ML) has sparked widespread research interest in clinical pharmacotherapy and is playing an increasingly important role in personalized medicine, particularly in the selection of drug dosage [12]. ML enables systems to analyze vast amounts of data collected from electronic medical records (EMR) and use advanced statistical and probabilistic techniques to automatically learn from this data. The construction of intelligent and effective predictive models should result in more accurate predictions [13]. Currently, several groups have developed new warfarin dosing models based on ML algorithms. However, most of these studies did not incorporate genetic characteristics, and the predictive accuracy of such models still has to be improved and validated [14, 15, 16, 17, 18]. In 2007 and 2010, the U.S. Food and Drug Administration (FDA) revised the instructions for warfarin and recommended validation of the cytochrome P450 family 2 subfamily C member 9 (CYP2C9) and vitamin K epoxide reductase complex subunit 1 (VKORC1) genotypes to more accurately guide the individualization of treatment [19, 20]. These changes highlight the importance of genetic information for individualized anticoagulant therapy with warfarin.
In order to overcome the limitations of traditional methods and further improve the prediction accuracy of the model, we developed and validated a prediction model for individualized warfarin maintenance dosage in patients after cardiac mechanical valve replacement based on a large number of clinical and genetic features and combined with 10 ML algorithms.
This retrospective study included patients who underwent mechanical heart valve replacement surgery at Beijing Anzhen Hospital, Capital Medical University, and subsequently achieved a stable warfarin dose. Comprehensive clinical data and genetic information was collected from patients who underwent surgery between January 2021 and January 2024.
The inclusion criteria were: (1) northern Chinese population; (2) patients aged
The exclusion criteria were: (1) the patient had severe liver and kidney
dysfunction; (2) abnormal preoperative INR values (
The study protocol received ethical approval from the Institutional Review Board of Beijing Anzhen Hospital (Ethics Approval Number: 2020067X), and was conducted in accordance with the Declaration of Helsinki. All participants voluntarily provided written informed consent prior to enrollment.
To ensure the reliability of the study results, the effect size was set to
medium (Cohen’s d = 0.5), the significance level to 0.05 (
Patient clinical data was collected through face-to-face interviews, regular phone calls, and review of the medical records from our hospital information system. These data included demographic characteristics, comorbidities, concomitant medications, preoperative echocardiographic parameters, cardiac function classification (New York Heart Association (NYHA) classification), surgical approaches, stable maintenance dose of warfarin therapy, and steady-state INR. The demographic characteristics included gender, age, height, weight, body surface area (BSA), body mass index (BMI), smoking history, and alcohol consumption history. Comorbidities were defined as chronic conditions or diseases diagnosed before the patient underwent heart valve replacement surgery. These included hypertension, diabetes, cerebrovascular disease, coronary artery disease and atrial fibrillation (AF). The presence of each comorbidity was confirmed by assessing the patient’s medical history and relevant diagnostic test results. Concomitant medications were defined as any medication being taken by the patient alongside the prescribed warfarin regimen, before or after surgery. This included digoxin, amiodarone, statin, and angiotensin converting enzyme inhibitors (ACEI) that could potentially interact with warfarin. A detailed list of these medications was obtained from the patient’s medical records. Preoperative echocardiographic parameters included ejection fraction (EF), left ventricular end-diastolic diameter (LVEDD), left ventricular end-systolic diameter (LVESD), and left atrial diameter (LAD).
Blood samples were drawn from each patient on the morning of the day before surgery and under fasting conditions. The levels of B-type natriuretic peptide (BNP), alanine transaminase (ALT), aspartate aminotransferase (AST), creatinine, triglycerides (TG), total cholesterol (TC), high density lipoprotein (HDL), low density lipoprotein (LDL), INR, fibrinogen, prothrombin time (PT) and other biochemical parameters were determined in the clinical laboratory of Beijing Anzhen Hospital, Capital Medical University, Beijing, China.
A total of 5 mL of venous blood was collected from eligible patients the day before surgery using an EDTA vacuum tube (BD Vacutainer, Franklin Lakes, NJ, USA) and stored at 4 °C before DNA extraction. Genomic DNA was extracted using the Blood DNA System DNA isolation kit (Catalog number: CW2320, CWBIO, Beijing, China) according to the manufacturer’s instructions and stored at 4 °C for subsequent use. DNA quality and purity were assessed by agarose gel electrophoresis and by measuring optical absorbance at A260/A280.
Genotyping of 6 SNPs was performed using the Illumina SNP GoldenGate Assay (Catalog number: WG-2500A-1001, Illumina, San Diego, CA, USA) according to the manufacturer’s instructions. These SNPs were CYP2C9 (rs1957910), VKORC1 (rs9923231), CYP4F2 (rs2108622), APOE (rs7412), CYP1A2 (rs2069514) and CYP3A4 (rs28371759). Briefly, 250 ng of genomic DNA was amplified at 37 °C for 20 h, followed by fragmentation and precipitation. The dried pellet was then resuspended and hybridized to the beadchips. These were subsequently incubated at 48 °C for 20 h, washed, and a single-base extension step performed. The beadchips were then stained, washed, coated, and dried. Finally, signal-intensity data were generated by an Illumina BeadArray Reader (Catalog number: BeadArray-1000, Illumina, San Diego, CA, USA). Twenty percent of the samples were selected at random for duplicate genotyping, with 99.8% concordance observed. Inconsistent data were excluded from the final analysis.
The collected data were entered into a Microsoft Excel spreadsheet and saved as
a .csv file. During data preprocessing, missing values were first analyzed and
the percentage of missing data determined for each variable to ensure
completeness. If the missing data for a variable was
All clinical and genetic data were included as candidate variables. Analysis of
covariance (ANCOVA) was used to evaluate the effect of clinical and genetic
variables on the target variable while controlling for potential confounders,
selecting variables with statistical significance based on p-values
(p
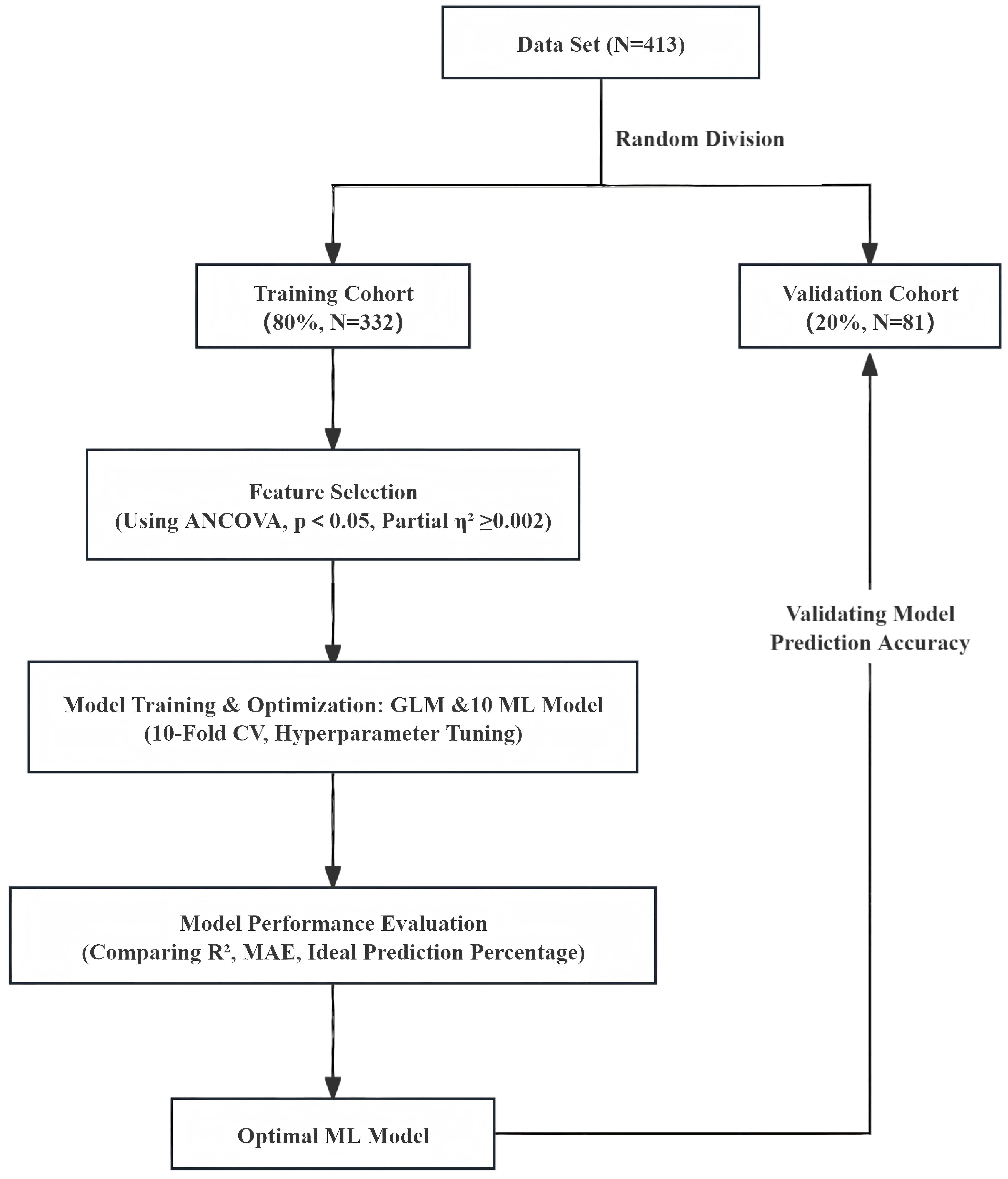
The processed dataset was used for model development and validation, as shown in Fig. 1. The patients included in the study were randomized into the training set and validation set at an 8:2 ratio. Based on previous literature [21, 22, 23], we selected both traditional linear models, such as the general linear model (GLM), and 10 commonly used ML algorithms to build the models, allowing for comparison between traditional and modern approaches. Specifically, these models included support vector machine with a linear kernel (SVM Linear), support vector machine with radial basis function kernel (SVM Radial), recursive partitioning and regression trees (RPART), gradient boosting machine (GBM), random forest (RF), generalized linear model with elastic net regularization (Glmnet), extreme gradient boosting with a linear booster (XGB Linear), kernel k-nearest neighbors (KKNN), convolutional neural network (CNN), and extreme gradient boosting (XGB). Considering the small size of the training and validation sets, we used 10-fold cross-validation (10-fold CV) for model evaluation and grid search for parameter optimization to ensure the robustness and accuracy of the model. In order to reduce the risk of overfitting, 10-fold CV was performed on the training set. In this process, the training set was first randomly divided into 10 subsets, with the model using 9 subsets as training data and the remaining subset as validation data for performance evaluation in each round. To further enhance the predictive performance of the model, grid search was used to optimize the model hyperparameters. The grid search method traverses all possible parameter combinations in the preset hyperparameter space, uses cross-validation to evaluate the performance of each set of hyperparameters, and finally selects the best hyperparameter combination. Specifically, hyperparameter optimization was performed for models such as SVM, RF, and XGB by adjusting parameters such as the C value, gamma value, number of trees, maximum depth, and learning rate to improve the model’s generalization and predictive accuracy. The best-performing model was selected after final evaluation, and its performance was validated using the validation set to ensure it had good generalization ability and clinical application potential. The parameter settings for the 10 ML algorithms are detailed in Supplementary Table 1.
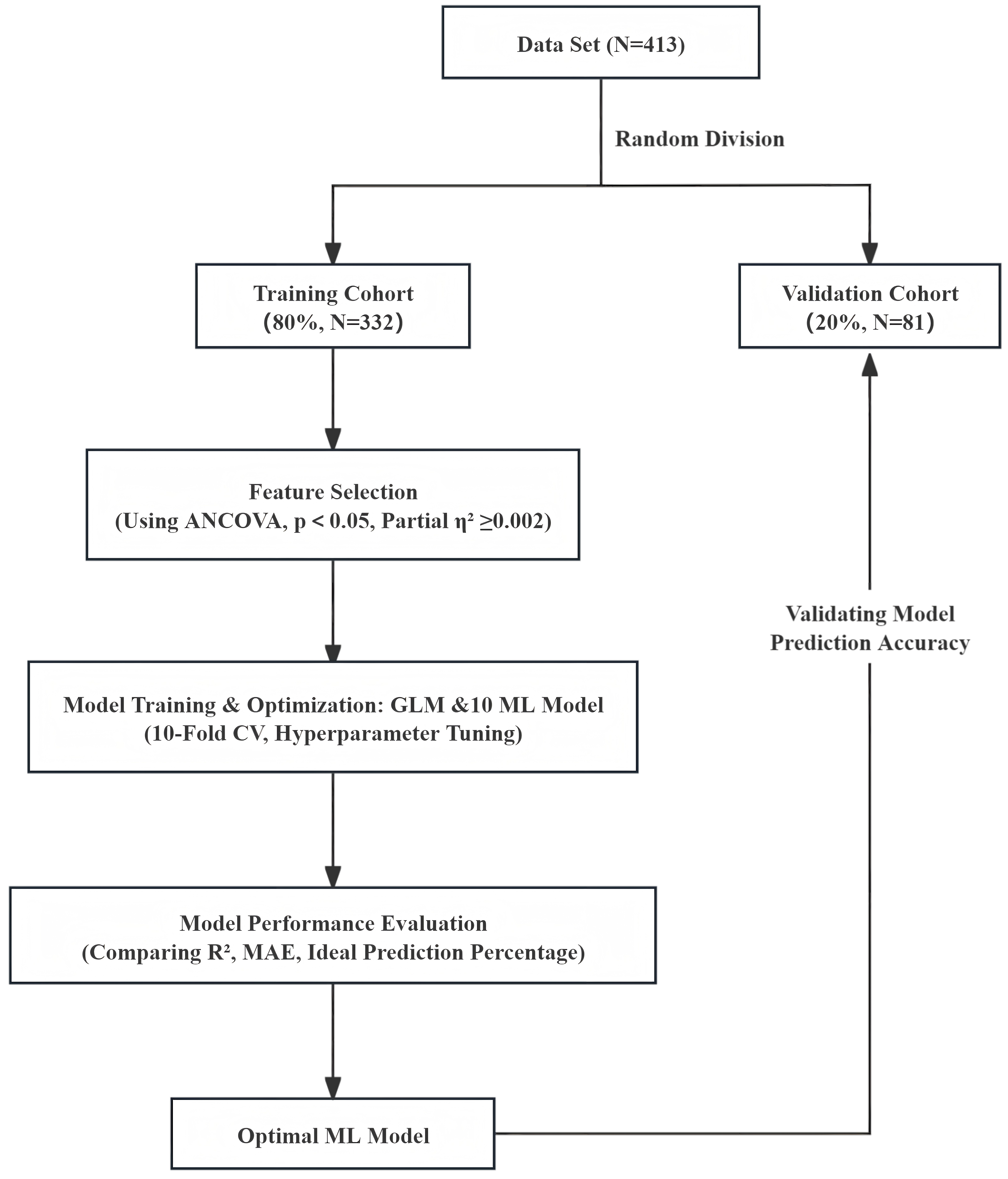 Fig. 1.
Fig. 1.
Flow chart used for modeling. ANCOVA, analysis of covariance; GLM, general linear model; MAE, mean absolute error; ML, machine learning; CV, cross-validation.
To assess the predictive accuracy and performance of the model, the primary evaluation metrics used were mean absolute error (MAE) and R-squared (R2). R2 is the coefficient of determination (also known as goodness of fit) and represents the extent to which the regression model explains the variation in the dependent variable, or how well the model fits the observed data. The value of R2 ranges from 0 to 1. Generally, the closer R2 is to 1, the better the model fit, indicating a higher degree of explanation of the dependent variable by the independent variables. A higher R2 value implies that a larger percentage of the total variability is explained by the model. When the observed values are closer to the regression line, the fit is more accurate [24].
The MAE metric is used to evaluate the accuracy of a predictive model by calculating the average of the absolute differences between the actual values and the predicted values. Lower MAE and higher R2 indicate higher predictive accuracy, and thus better model performance.
Additionally, the ideal prediction percentage was used to evaluate the clinical
utility of the model, defined as the percentage of predicted doses within
A dose subgroup analysis was conducted to account for heterogeneity in clinical
practice. The conventional warfarin dose in China is 2.5 mg/day. Based on
clinical recommendations and existing studies [16, 17, 18], dose thresholds were
defined as the 25th and 75th percentiles of the conventional dose, i.e.,
high-dose (
Continuous variables are presented as means
Multiple ML techniques were utilized to model and analyze the data, with a
variety of R packages employed to perform these analyses. These included the
stats package (version 4.2.2; R Foundation for Statistical Computing, Vienna,
Austria; https://www.R-project.org/) for basic
statistical functions, e1071 (version 1.7-14;
https://CRAN.R-project.org/package=e1071)
for SVM implementations, RPART (version
4.1.23; https://CRAN.R-project.org/package=rpart)
for recursive partitioning and decision tree algorithms, GBM (version
2.1.9; https://CRAN.R-project.org/package=gbm)
for generalized boosting machines, RF (version
4.7-1.1; https://CRAN.R-project.org/package=randomForest)
for ensemble learning, Glmnet (version
4.1-8; https://CRAN.R-project.org/package=glmnet)
for penalized regression models, XGBoost (version
1.7.7.1; https://CRAN.R-project.org/package=xgboost)
for gradient boosting machines, Class (version
7.3-22; https://CRAN.R-project.org/package=class)
for classification algorithms, and Keras (version
2.15.0; https://CRAN.R-project.org/package=keras)
for deep learning models. All statistical and machine learning analyses were
performed using R (version 4.2.2; R Foundation for Statistical Computing, Vienna,
Austria; https://www.R-project.org/). For all
statistical tests, a significance threshold of p-value
Following execution of the inclusion and exclusion criteria, a total of 413
patients were enrolled in the study, including 227 males (54.96%). The median
age of participants was 53 (46–59) years, with an average height of 165.86
| Characteristics, unit | Training set (N = 332) | Validation set (N = 81) | p-value | ||
| Demographic information | |||||
| Age, years | 52 (46–59) | 54 (50–59) | 0.220 | ||
| Sex, male, n (%) | 186 (56.02) | 41 (50.62) | 0.381 | ||
| Height, cm | 166.03 |
165.16 |
0.401 | ||
| Weight, kg | 65.5 (59–75) | 65 (59–75) | 0.578 | ||
| BSA, m2 | 1.75 |
1.74 |
0.654 | ||
| BMI, kg/m2 | 24.02 (22.06–27.02) | 24.22 (21.77–26.99) | 0.844 | ||
| Smoke, n (%) | 125 (37.65) | 24 (29.63) | 0.178 | ||
| Drink, n (%) | 75 (22.59) | 17 (20.99) | 0.756 | ||
| Comorbidities | |||||
| Hypertension, n (%) | 75 (22.59) | 18 (22.22) | 0.943 | ||
| Diabetes, n (%) | 24 (7.23) | 4 (4.94) | 0.462 | ||
| Hyperlipidemia, n (%) | 47 (14.16) | 18 (22.22) | 0.074 | ||
| Coronary artery disease, n (%) | 21 (6.33) | 7 (8.64) | 0.457 | ||
| Cerebrovascular disease, n (%) | 15 (4.52) | 1 (1.23) | 0.330* | ||
| AF, n (%) | 102 (30.72) | 24 (29.63) | 0.848 | ||
| Combine medications | |||||
| Digoxin, n (%) | 57 (17.17) | 11 (13.58) | 0.435 | ||
| Amiodarone, n (%) | 50 (15.06) | 9 (11.11) | 0.362 | ||
| Statin, n (%) | 26 (7.83) | 8 (9.88) | 0.548 | ||
| ACEI, n (%) | 12 (3.61) | 1 (1.23) | 0.478* | ||
| Preoperative test indicators | |||||
| BNP, pg/mL | 202.5 (75–479.75) | 186 (65–317) | 0.234 | ||
| ALT, U/L | 17.5 (12–25) | 17 (13–25) | 0.596 | ||
| AST, U/L | 19 (15–25) | 20 (15–23) | 0.906 | ||
| Creatinine, µmol/L | 76.4 (66.65–90.2) | 77.1 (65.1–87.8) | 0.522 | ||
| Triglycerides, mmol/L | 1.35 (1–1.88) | 1.37 (1.01–1.91) | 0.598 | ||
| TC, mmol/L | 4.57 (3.92–5.29) | 4.77 (4.12–5.54) | 0.082 | ||
| HDL, mmol/L | 1.15 (0.92–1.34) | 1.15 (0.94–1.32) | 0.982 | ||
| LDL, mmol/L | 2.76 (2.16–3.43) | 2.89 (2.46–3.53) | 0.129 | ||
| Prothrombin Time, s | 11.8 (11.2–12.75) | 11.6 (11.1–12.9) | 0.784 | ||
| INR | 1.04 (1–1.14) | 1.04 (1–1.17) | 0.783 | ||
| Fibrinogen, g/L | 2.8 (2.3–3.2) | 2.7 (2.4–3.3) | 0.900 | ||
| Preoperative echocardiogram | |||||
| EF, % | 60 (55–64.25) | 60 (54–65) | 0.637 | ||
| LVEDD, mm | 51 (46–60.25) | 50 (45–56) | 0.242 | ||
| LVESD, mm | 35 (30–42) | 35 (30–39) | 0.264 | ||
| LAD, mm | 58 (47–68) | 57 (50–64) | 0.679 | ||
| NYHA classification | 0.284 | ||||
| Level I, n (%) | 10 (3.01) | 3 (3.70) | |||
| Level II, n (%) | 123 (37.05) | 21 (25.93) | |||
| Level III, n (%) | 161 (48.49) | 50 (61.73) | |||
| Level IV, n (%) | 38 (11.45) | 7 (8.64) | |||
| Surgery type | |||||
| Mitral valve replacement, n (%) | 114 (34.34) | 33 (40.74) | 0.281 | ||
| Aortic valve replacement, n (%) | 151 (45.48) | 34 (41.98) | 0.569 | ||
| Double valve replacement, n (%) | 67 (20.18) | 14 (17.28) | 0.556 | ||
| Combined Cox-Maze procedure, n (%) | 51 (15.36) | 8 (9.88) | 0.206 | ||
| Warfarin maintenance dose, mg/day | 3 (2.25–3.38) | 3 (2.25–3.75) | 0.641 | ||
| Steady-state INR | 1.96 (1.78–2.2) | 2.03 (1.8–2.2) | 0.261 | ||
| Genetic profiles | |||||
| CYP2C9 (rs1057910), n (%) | 0.979 | ||||
| *1/*1 | 303 (91.27) | 74 (91.36) | |||
| *1/*3 | 29 (8.73) | 7 (8.64) | |||
| VKORC1 (rs9923231), n (%) | 0.166* | ||||
| AA | 278 (83.73) | 66 (81.48) | |||
| AG | 53 (15.96) | 13 (16.05) | |||
| GG | 1 (0.31) | 2 (2.47) | |||
| CYP4F2 (rs2108622), n (%) | 0.267* | ||||
| CC | 182 (54.82) | 41 (50.62) | |||
| CT | 133 (40.06) | 32 (39.51) | |||
| TT | 17 (5.12) | 8 (9.87) | |||
| APOE (rs7412), n (%) | 1.000* | ||||
| CC | 273 (82.23) | 68 (83.95) | |||
| CT | 56 (16.87) | 13 (16.05) | |||
| TT | 3 (0.90) | 0 | |||
| CYP1A2 (rs2069514), n (%) | 0.664* | ||||
| AA | 278 (83.73) | 65 (80.25) | |||
| AG | 48 (14.46) | 15 (18.52) | |||
| GG | 6 (1.81) | 1 (1.23) | |||
| CYP3A4 (rs28371759), n (%) | 0.474* | ||||
| AA | 321 (96.69) | 80 (98.77) | |||
| AG | 11 (3.31) | 1 (1.23) | |||
Data are presented as the mean
ANCOVA was used to select variables from the potential independent factors.
Based on these criteria, 13 primary input variables were chosen from the initial
factors for subsequent construction of the model (Table 2), namely sex, age, BSA,
height, weight, smoke, digoxin, AF, TC, LDL, Cox-Maze, VKORC1, and
CYP2C9. Among the variables included in the model, AF had the largest
partial
| Included variables, unit | Partial |
| Sex | 0.002 |
| Age, years | 0.003 |
| BSA, m2 | 0.005 |
| Weight, kg | 0.004 |
| Height, cm | 0.004 |
| Smoke | 0.011 |
| Digoxin | 0.011 |
| AF | 0.016 |
| TC, mmol/L | 0.002 |
| LDL, mmol/L | 0.003 |
| Cox-Maze | 0.012 |
| VKORC1 | 0.007 |
| CYP2C9 | 0.009 |
Partial
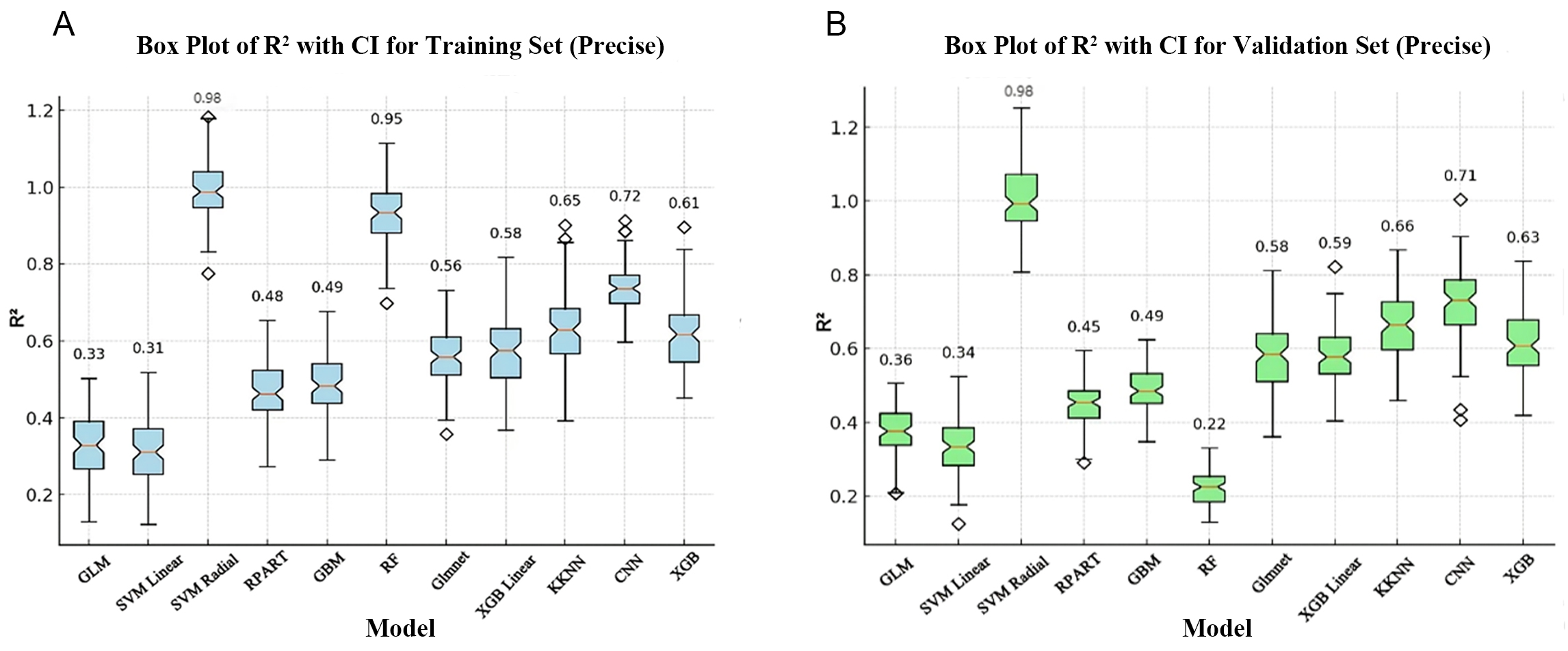
To assess the predictive accuracy and performance of the models, we first evaluated the R2 of 10 ML models and of the GLM model. In the training set, the SVM Radial model and the RF model have the highest R2 of 0.98 and 0.95, respectively, while the SVM Linear model and the GLM model have the lowest R2 of 0.31 and 0.33, respectively. The remaining models have R2 ranging between 0.48 and 0.72 (Fig. 2A). In the validation set, the SVM Radial model had the highest R2 of 0.98, demonstrating high stability and generalization ability, and indicating it has significant advantages in terms of handling complex data patterns and lower susceptibility to overfitting (Fig. 2B). However, RF had the lowest R2 (0.22) in the validation set (Fig. 2B), performing noticeably worse than in the training set. This result suggests potential overfitting, where the model learns too many details and noise from the training data that do not apply to new, unseen data. The R2 for the remaining models with the validation set ranged from 0.34 to 0.71 (Fig. 2B).
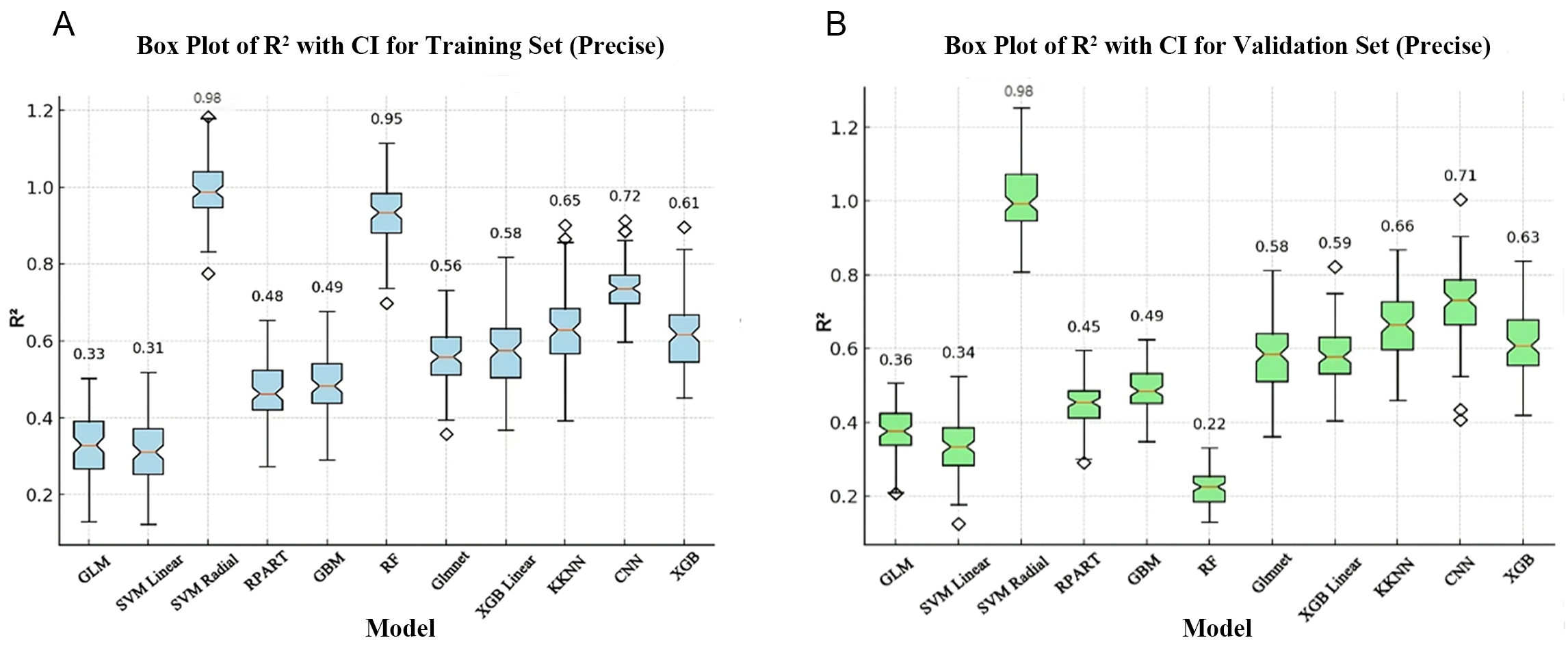 Fig. 2.
Fig. 2.
Comparison of R2 for the training and validation sets for different algorithms. (A) Box plot of R2 values for the training set. (B) Box plot of R2 values for the validation set. The horizontal axis represents the different models and the vertical axis represents the R2 values. The box plot shows the median, interquartile range and 95% confidence interval (CI) of the R2 values. GLM, general linear model; SVM Linear, support vector machine with linear kernel; SVM Radial, support vector machine with radial basis function kernel; RPART, recursive partitioning and regression trees; GBM, gradient boosting machine; RF, random forest; Glmnet, generalized linear model with elastic net regularization; XGB Linear, extreme gradient boosting with linear booster; KKNN, kernel k-nearest neighbors; CNN, convolutional neural network; XGB, extreme gradient boosting.
Next, we calculated the MAE of all models. The MAE of SVM Radial was the lowest at 0.14 mg/day (95% CI: 0.11–0.17), indicating it was a stable model. In contrast, the MAE in the validation set was highest in RF at 0.93 mg/day (95% CI: 0.88–0.98) (Table 3). This indicates RF was an unstable model, probably due to the small sample size and overfitting.
| Model | MAE (95% CI), mg/day |
| GLM | 0.74 (0.68–0.80) |
| SVM Linear | 0.77 (0.71–0.83) |
| SVM Radial | 0.14 (0.11–0.17) |
| RPART | 0.24 (0.19–0.28) |
| GBM | 0.47 (0.42–0.52) |
| RF | 0.93 (0.88–0.98) |
| Glmnet | 0.75 (0.71–0.79) |
| XGB Linear | 0.76 (0.71–0.81) |
| KKNN | 0.21 (0.17–0.25) |
| CNN | 0.39 (0.33–0.45) |
| XGB | 0.35 (0.30–0.40) |
MAE, mean absolute error; 95% CI, 95% confidence interval; GLM, general linear model; SVM Linear, support vector machine with linear kernel; SVM Radial, support vector machine with radial basis function kernel; RPART, recursive partitioning and regression trees; GBM, gradient boosting machine; RF, random forest; Glmnet, generalized linear model with elastic net regularization; XGB Linear, extreme gradient boosting with linear booster; KKNN, kernel k-nearest neighbors; CNN, convolutional neural network; XGB, extreme gradient boosting.
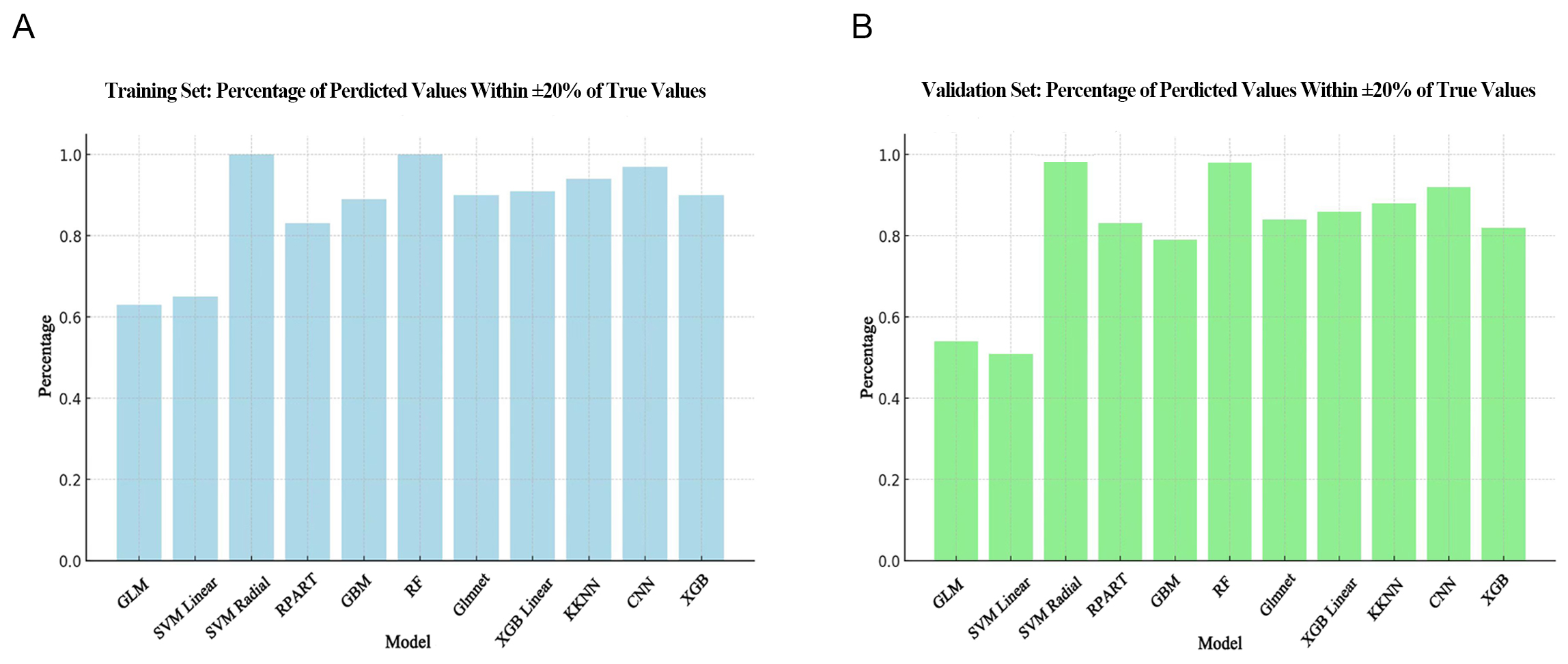
Calculation of the ideal prediction percentage revealed the SVM Radial and RF models performed best. Moreover, the results obtained with the validation set (Fig. 3B) for these two models were as good as with the training set (Fig. 3A). The lowest ideal prediction percentage observed in the training set was GLM, while in the validation set it was SVM Linear.
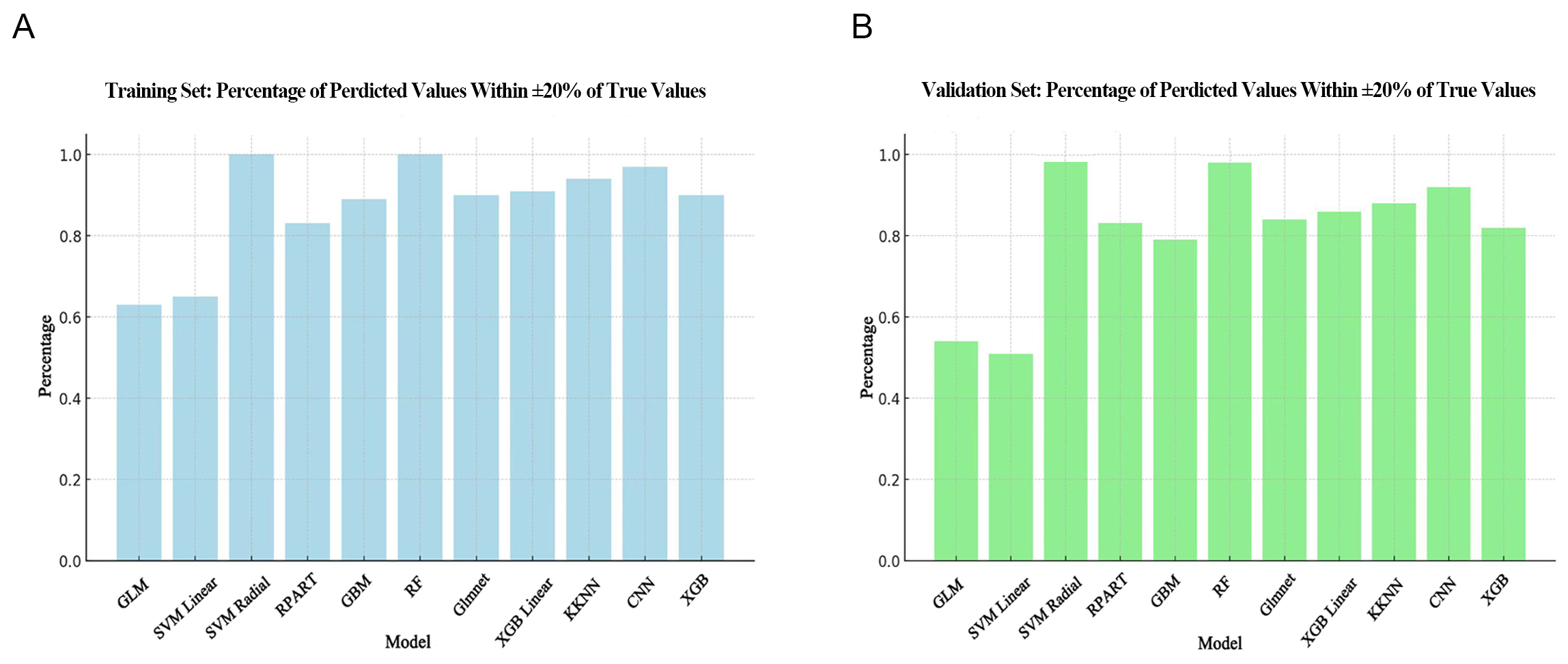 Fig. 3.
Fig. 3.
Comparison of ideal prediction percentage for different
algorithms. (A) Ideal prediction percentage in the training set. (B) Ideal
prediction percentage in the validation set. The horizontal axis shows the
different models, while the vertical axis shows the proportion of samples where
the predicted value is within
In summary, the SVM Radial model demonstrated the highest R2, the best ideal prediction percentage, and the smallest MAE. We therefore selected SVM Radial as the optimal model for predicting stable warfarin dose in patients following surgery for mechanical heart valve replacement.
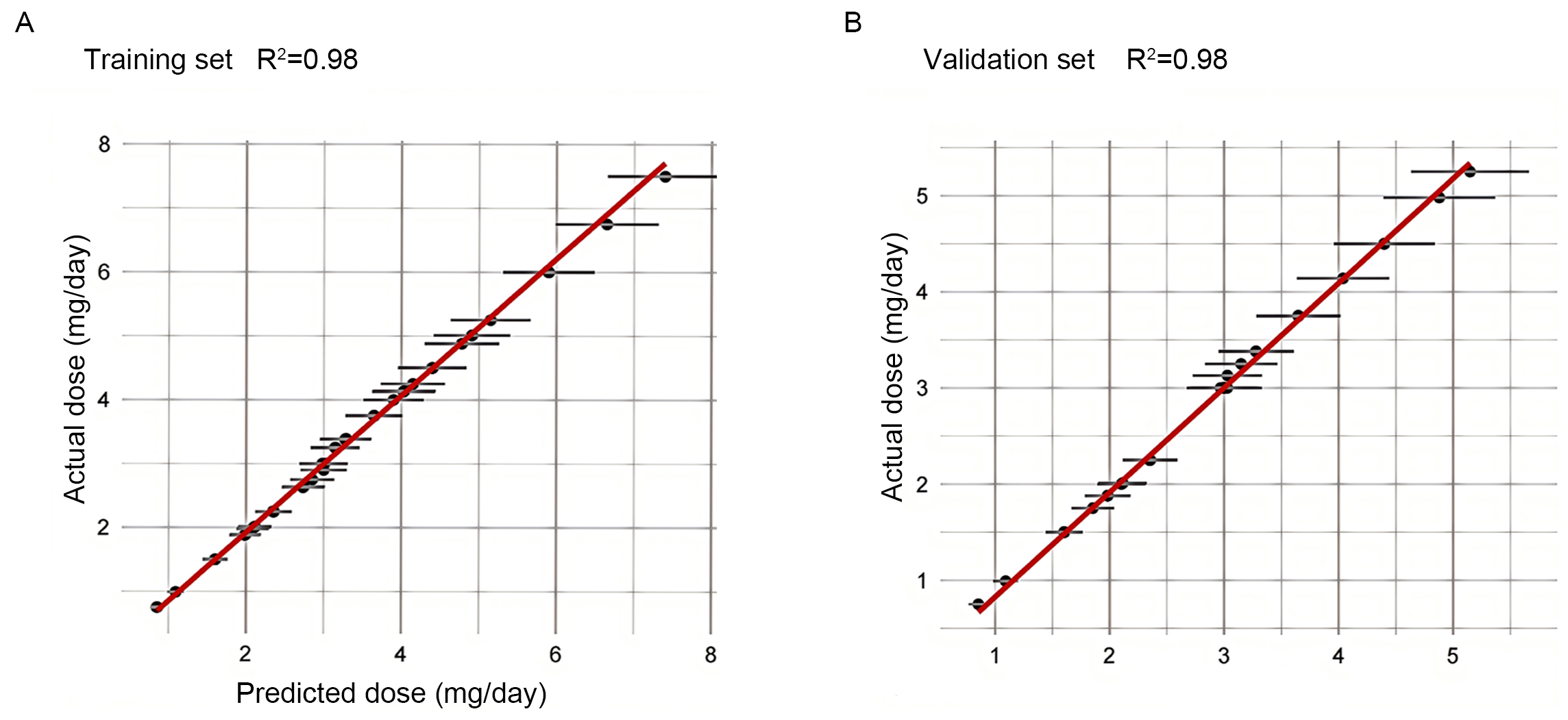
To further evaluate the overall predictive performance of the SVM Radial model, we plotted the predicted dose versus actual dose fit assessment in both the training and validation datasets (Fig. 4). In the training and validation sets, R2 was 0.98, indicating a strong correlation between the predicted values and the actual observations, and demonstrating the excellent predictive capabilities of the SVM Radial model.
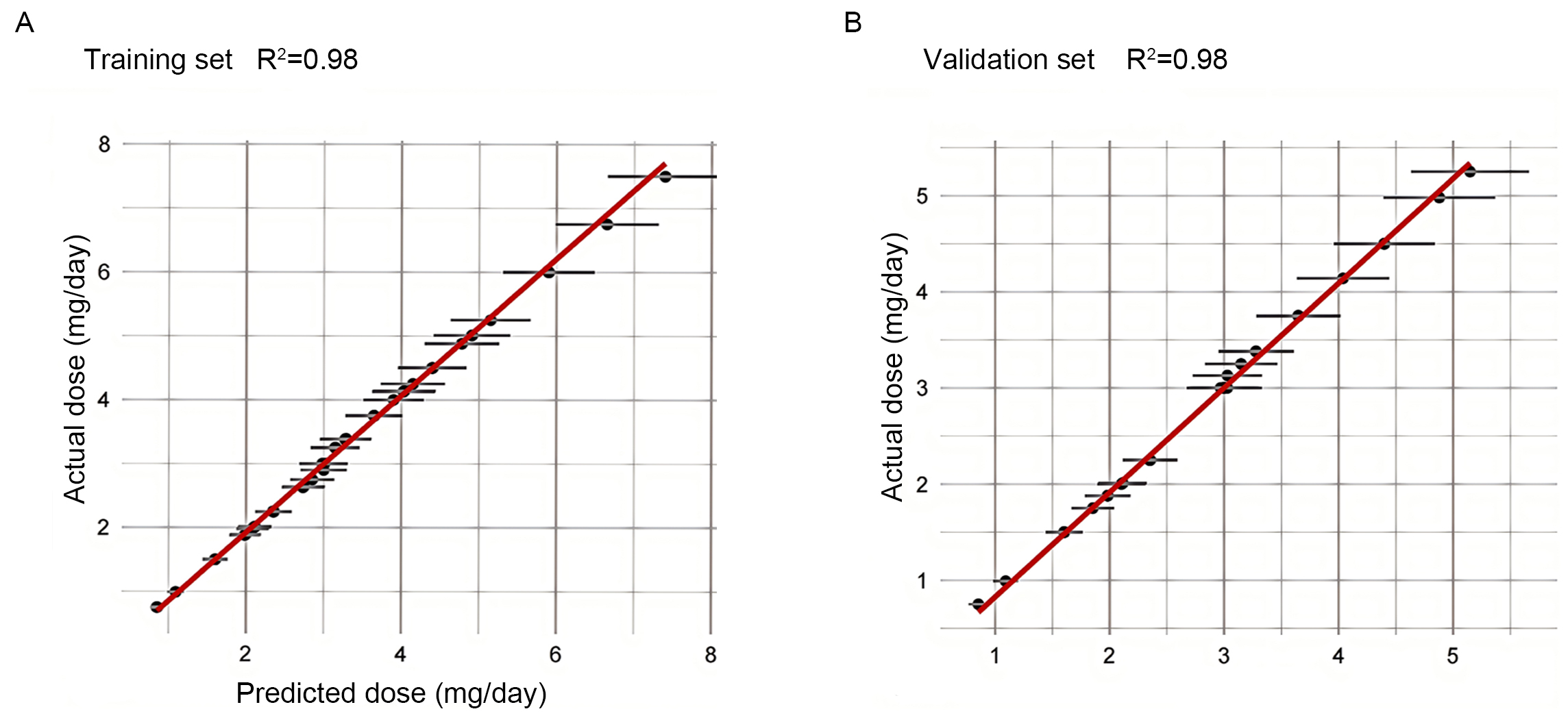 Fig. 4.
Fig. 4.
Plot of predicted versus actual dose fit assessment for the training and validation sets. (A) Plot of predicted versus actual dose fit assessment for the training set. (B) Plot of predicted versus actual dose fit assessment for the validation set. The horizontal axis shows the predicted dose, and the vertical axis shows the actual dose. The solid red line indicates the ideal fit (y = x), and the black dots represent the median of the actual values within each prediction interval, while the error bars reflect the variability of the data within that interval.
In the dose subgroup analysis, the SVM Radial model demonstrated high accuracy
for predicting warfarin doses. For the total sample, this model successfully
predicted the ideal dose in 98.06% of cases. A detailed analysis of different
dose levels revealed a prediction success rate of 95.00% for the 40 subjects
requiring a low daily dose (
| Actual dose | N | Ideal (%) | Underestimate (%) | Overestimate (%) | |
| Total cohort | 413 | 405 (98.06) | 7 (1.70) | 1 (0.24) | |
| 40 (9.69) | 38 (95.00) | 1 (2.50) | 1 (2.50) | ||
| 1.875–3.125 mg/day | 245 (59.32) | 242 (98.78) | 3 (1.22) | 0 | |
| 128 (30.99) | 125 (97.66) | 3 (2.34) | 0 | ||
| Validation cohort | 81 | 76 (93.83) | 4 (4.94) | 1 (1.23) | |
| 7 (8.65) | 6 (85.71) | 0 | 1 (14.29) | ||
| 1.875–3.125 mg/day | 49 (60.49) | 47 (95.92) | 2 (4.08) | 0 | |
| 25 (30.86) | 23 (92.00) | 2 (8.00) | 0 | ||
Data are presented as n (%). The total cohort includes the training cohort and
validation cohort. Ideal percentage of patients whose predicted absolute error
between the predicted and actual doses was within 20% of the actual dose.
Underestimate percentage of patients whose predicted dose was less than the
actual dose, and the predicted absolute error between the predicted and actual
doses was
The SVM Radial model accurately predicted the dose for 93.83% of the 81
subjects in the validation cohort. In the different dose groups, the prediction
accuracy was 85.71% for 7 subjects in the low-dose group (
Our study had the following important features. First, this study was based on case data from the Beijing Anzhen Hospital, recognized as a highly authoritative cardiovascular center in China. We included a wide range of clinical and genetic factors in our model construction to broaden its array of features. The genetic factors consisted of six SNP loci whose inclusion further enhance the model’s predictive performance and have not been included in most previous studies. Second, due to the relatively small sample size of this study, we also evaluated the performance of 10 artificial intelligence ML methods and selected the best-performing model to ensure predictive accuracy. Third, the median warfarin maintenance dose in our study was 3 mg/day, which is lower than the 4 mg/day maintenance dose used in the IWPC model [8]. The target INR range was set at 1.5–2.5, which is significantly lower than the internationally used range of 2.0–3.0. The lower the intensity of anticoagulation, the lower the warfarin dose. Research has shown that in Chinese patients undergoing heart valve replacement surgery, low-intensity anticoagulation therapy (INR 1.5–2.5) does not increase the incidence of embolic or thrombotic complications, but significantly reduces the risk of bleeding complications and mortality [25]. Therefore, our algorithm is particularly suitable for individualized warfarin anticoagulation treatment of Chinese patients following heart valve surgery. By implementing this individualized dosing model, patient safety can be enhanced by minimizing the risk of adverse events such as bleeding or thrombosis. Additionally, the need for frequent dose adjustments is reduced, thereby making the overall management of warfarin therapy more efficient.
Robust evidence already exists in the literature regarding factors that influence the stable maintenance dose of warfarin investigated in this study. Height, weight, and BSA were positively correlated with warfarin dosage. Age, height, and weight have been reported to account for 76.8% of the variations in warfarin dosage [26], with most researchers agreeing that older adults require lower doses [27]. This might be due to reduced hepatic blood flow with increasing age, resulting in decreased warfarin transport to the liver and possibly diminished vitamin K absorption in elderly patients [28]. AF is positively correlated with warfarin dose, and the relatively high intensity of anticoagulation in targets with combined AF leads to an increase in the required dose [29]. The Cox-Maze procedure is a viable technique for treating heart valve disease combined with AF [30]. To minimize bleeding and thromboembolic complications, radiofrequency ablation is usually performed concurrently with valve replacement, thus requiring optimal perioperative anticoagulation with warfarin [31]. With regard to concomitant medications, amiodarone is one of the most frequently included features in previous warfarin dosing prediction models. However, it was not included as a key variable in the present study due to its relatively small weight. Our study did however incorporate digoxin, which competitively binds to P-glycoprotein to reduce the transport and elimination of warfarin, thereby enhancing the drug concentration and anticoagulant effect [32]. Furthermore, our study suggests that inclusion of TC and LDL levels may lead to the development of models with higher prediction accuracy. A possible underlying mechanism is that high cholesterol and elevated LDL levels are associated with fatty liver, which can impact the fluidity of liver cell membranes and affect the cytochrome P450 enzyme system, particularly CYP2C9, thereby influencing warfarin metabolism [33]. Additionally, high cholesterol may alter plasma protein levels [34], affecting the binding of warfarin to albumin and its free fraction, and thus modifying its anticoagulant effect [35]. Elevated cholesterol may also increase inflammatory markers such as C-reactive protein (CRP), potentially altering the patient’s coagulation status and reducing the efficacy of warfarin [36].
VKORC1 and CYP2C9 have been reported to account for approximately 35%–50% of the variability in warfarin dose requirements [37]. These genes are widely recognized for their significant influence on the warfarin dosage. VKORC1 is a rate-limiting enzyme in the vitamin K cycle and the activation of clotting factors. It affects warfarin pharmacodynamics through its interaction with various warfarin targets [38]. Significant differences have been reported in the frequency of VKORC1 genotypes between different races. Most of the Chinese Han population carry the VKORC1 mutant genotype (AA/AG), which requires a lower warfarin dose compared to wild-type (GG) patients [6]. CYP2C9 is a key drug-metabolizing enzyme found primarily in the liver. It catalyzes the conversion of S-warfarin to its metabolites, altering the stable therapeutic dose by influencing warfarin metabolism. The *3 variant of CYP2C9 is the most prevalent variant in the Chinese population [39], and frequencies of the CYP2C9 *1/*1, *1/*3 and *3/*3 genotypes in the Chinese Han population are 91.0%, 8.44% and 0.55%, respectively [40]. Their frequencies in the current study (91.28%, 8.72% and 0, respectively) concur with the previous results. Compared to CYP2C9*1 homozygous patients, those harboring the *3 mutation require only a low dose of warfarin to achieve the same anticoagulant effect [41]. Authoritative dosing algorithms, such as IWPC [8] and Gage [9], have demonstrated that genetic data can significantly enhance the predictive performance of these models, explaining why our algorithm also has high predictive accuracy.
The MAE of our SVM Radial model was 0.14 mg/day, or close to 0.98 mg/week. This is considerably lower than the IWPC genetic model of 8.5 mg/week [8]. Moreover, the SVM Radial model had a higher R2 value (0.98 vs. 0.43). In the dose subgroup analyses, the SVM Radial model had a higher ideal prediction percentage compared to the IWPC model in the low-dose (85.71% vs. 33.00%, respectively), medium-dose (95.92% vs. 54.60%), and high-dose (92.00% vs. 36.80%) subgroups, thus demonstrating better predictive performance. The predictive accuracy of the ML algorithm was significantly improved compared to MLR.
Several ML algorithms have been used for warfarin dose prediction. Tao
et al. [42] built an adaptive neuro-fuzzy inference system (ANFIS). Our
SVM Radial model outperformed the ANFIS model in terms of ideal prediction
percentage (93.83% vs. 63.7%, respectively) and MAE (0.140 vs. 0.603). Li
et al. [16] developed a back-propagation neural network (BPNN) model to
predict the maintenance dose of warfarin after heart valve surgery. The BPNN
model had a higher MAE value than the SVM Radial model (0.614 vs. 0.140,
respectively), and worse performance on the ideal prediction percentage (47.86%
vs. 93.83%). The strength of both the Tao et al. [42] and Li et
al. [16] studies was their large sample size of
There were some limitations to this study. Firstly, the construction of our model was based on a specific population of post-surgical patients who underwent mechanical heart valve replacement in a single center. The results were highly specific and sensitive, thus limiting their generalizability and universality to different patient groups, especially in high-risk patient populations. Future studies should include a large sample size to ensure diversity and representativeness of the training data, and to improve the customization of high-risk patient groups. Second, this was a retrospective study with a relatively small sample size and lack of external validation. Future studies should aim to increase the sample size, recruit more subjects, have a prospective study design, and include multicenter validation to test the predictive performance of any new models. Meanwhile, the models should be continuously optimized and updated by including new clinical data and multicenter data. They should be dynamically adjusted to maintain the accuracy of prediction and to ensure the model is capable of adapting to changing clinical needs. Due to the unpopularity and expense of genetic testing in developing countries and the complexity of ML algorithms, the practical application of these models is still limited by their high implementation cost, complex operational requirements, high patient compliance requirement, and high demand for medical resources. By integrating SHapley Additive exPlanations (SHAP) or Local Interpretable Model-agnostic Explanations (LIME) tools [44, 45], model interpretability can be enhanced, making decision-making processes more transparent and fostering greater trust and adoption. Alternatively, developing hybrid pharmacokinetic (PK)/pharmacodynamic (PD)-ML models [46] can enable more precise, individualized healthcare, improving medical efficiency and further boosting the clinical utility of these models in the future.
The SVM Radial model based on clinical and genetic factors demonstrated high predictive accuracy, especially in low- and high-dose groups. This model shows great promise in predicting the appropriate maintenance dose of warfarin after surgery for mechanical heart valve replacement. However, further validation through large, multicenter prospective studies is necessary to improve the generalizability and practical application of the SVM Radial model in different patient populations.
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
BWG, CC, YL and RD were responsible for the design, supervision of the study, and revision of the manuscript. BWG drafted the manuscript. YS, TSL, and JBZ designed a statistical plan. YL and RD performed data validation and methodological refinement. KZ, JHJ participated in data acquisition. All authors contributed to editorial changes in the manuscript. All authors read and agreed to the final manuscript. All authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
This study was conducted in accordance with the principles of the Declaration of Helsinki. Approval was granted by the Ethics Committee of Beijing Anzhen Hospital, Capital Medical University (No. 2020067X). Written informed consent was obtained from all individual participants included in the study.
We would like to acknowledge everyone for their helpful contributions on this paper.
This work was supported by Beijing Municipal Health Commission-The Capital Health Research and Development of Special (Capital Development 2020-2Z-2067).
The authors declare no conflict of interest.
Supplementary material associated with this article can be found, in the online version, at https://doi.org/10.31083/RCM33425.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.