





 , Qianheng Li 1, Dandan Wang 1
, Qianheng Li 1, Dandan Wang 11 Academy of Fine Arts, Shandong Normal University, 250061 Jinan, Shandong, China
Abstract
Automatic categorization of fine art paintings across multiple semantic facets, such as artist, style, and genre, is fundamental for large-scale digital archiving, semantic indexing, and knowledge organization of cultural heritage collections. In this paper, we propose convolutional neural network (CNN)-Transformer Hybrid Attention model for art paintings categorization (CTHArt), a CNN-Transformer Hybrid Attention network for multitask art painting categorization. The model employs a dual-branch hybrid backbone that combines a CNN stream for fine-grained local texture modeling and a Transformer stream for global compositional and stylistic context learning. To further exploit inter-facet semantic dependencies, we introduce a Cross-Task Attention Head, which enables task-specific classifiers to exchange information through learnable cross-attention interactions. This design supports coordinated facet prediction consistent with knowledge organization principles. We evaluate the proposed framework on three benchmark datasets. Experimental results demonstrate that CTHArt consistently achieves state-of-the-art performance. The proposed approach provides an effective and scalable solution for artificial intelligence (AI)-assisted knowledge organization of art collections.
Keywords
- Chinese traditional painting classification
- artificial intelligence
- convolutional neural network
- Vision Transformer
- cross attention
The automatic categorization of fine art paintings (including artist attribution, style classification, and genre identification) plays a critical role in large-scale digital archiving, semantic indexing, and structured access to cultural heritage collections (Bianco et al., 2019; Specker et al., 2024). From a Knowledge Organization (KO) perspective, these labels function as complementary semantic facets that support systematic description, retrieval, and analysis of artworks (Hjørland, 2008). KO theory emphasizes that effective knowledge access depends on well-structured conceptual categorization and facet-based organization of domain entities (Giunchiglia et al., 2014; Giunchiglia and Bagchi, 2024). With the rapid growth of digital art repositories, artificial intelligence (AI)-driven methods are increasingly becoming essential components in knowledge organization ecosystems for scalable and consistent metadata construction (Bagchi, 2021a).
Painting analysis differs fundamentally from natural image understanding. Artistic representations often contain deliberate distortions, stylized textures, symbolic abstractions, and historically grounded visual conventions that challenge conventional computer vision assumptions (Zhao and Zhang, 2025; Xu et al., 2025). For example, artistic style encodes high-level aesthetic and historical characteristics such as Impressionism or Baroque rather than simple visual statistics. Artist attribution depends on subtle idiosyncratic cues such as brushstroke patterns and color layering strategies, while genre classification reflects thematic and compositional conventions. These semantic dimensions are not independent but form an interrelated knowledge.
Traditionally, painting categorization has been performed manually by experts, requiring specialized domain knowledge and extensive effort. Recent advances in deep neural networks (DNNs) have enabled automated approaches based on convolutional neural networks (CNNs) (González-Martín et al., 2024) and Vision Transformers (ViTs) (Dosovitskiy et al., 2020). However, existing methods typically treat artist, style, and genre prediction as isolated tasks and rely on single-architecture backbones, which introduces two important limitations (Gao et al., 2025). Firstly, artist, style, and genre are intrinsically linked (e.g., Van Gogh’s post-impressionist works) in art paintings categorization task (as shown in Fig. 1), but single-task models fail to exploit shared and complementary semantic representations across multiple KO facets, reducing both learning efficiency and semantic consistency. Second, CNN-only or Transformer-only architectures provide incomplete feature modeling. CNNs are effective at capturing local visual structures such as textures and brushstrokes but have limited capacity for modeling long range compositional dependencies. Transformers capture global relationships through self-attention but usually require large-scale training data and higher computational cost, which is not always suitable for art datasets that are comparatively limited and fine-grained.
 Fig. 1.
Fig. 1.
Some example art paintings (artist, style, and genre are intrinsically linked).
Recent hybrid CNN-Transformer architectures demonstrate that combining convolutional inductive bias with global attention modeling can yield more balanced representations. CNN layers provide stable local feature hierarchies, while Transformer modules model long-range structural and semantic dependencies. For example, 3M-Hybrid (Yang et al., 2025) integrates pretrained ViTs with CNNs for mural restoration, using frequency-based decomposition to handle scarce data and structural distortions. CDDFuse (Zhao et al., 2023) decomposes cross-modal features into correlated (low-frequency) and unique (high-frequency) components using CNN-Transformer dual branches, enhancing infrared-visible image fusion. These frameworks validate hybrid models’ efficacy but remain unoptimized for multitask art analysis. Their fusion strategies lack explicit mechanisms to model task-specific interactions—e.g., how style features inform artist identification.
To address these limitations, and to better support AI-driven knowledge organization of art collections, we propose a CNN-Transformer Hybrid Attention model for art paintings categorization (CTHArt). The model is designed as a multitask, multibranch architecture that jointly predicts artist, style, and genre labels while modeling their semantic interactions. The hybrid backbone integrates a CNN branch for high-frequency local artistic details and a Transformer branch for global compositional and stylistic context. Multiple classification tasks share this backbone to learn unified semantic representations. On top of the shared features, we introduce a cross-task attention mechanism between task-specific decoder heads, enabling each task to selectively attend to informative features from the other tasks. This design implements flexible inter-facet semantic interaction rather than a fixed hierarchical dependency, aligning with KO principles of facet coordination and semantic linking. We evaluate the proposed framework on serval benchmark art datasets. Experimental results show that our model achieve state-of-the-art (SOTA) performance. Beyond performance gains, the proposed framework can also be viewed as an AI-assisted KO mechanism for cultural heritage data, enabling coordinated facet assignment and semantic enrichment in large-scale art knowledge bases (Bagchi, 2021b).
This work makes three key contributions:
• A CNN-Transformer hybrid backbone that jointly captures fine-grained artistic details and global stylistic semantics for multi-facet painting categorization.
• A cross-task attention mechanism is integrated into the multitask decoder, explicitly capturing inter-task dependencies through learnable feature interactions.
• Extensive experiments and ablation studies demonstrating the effectiveness of hybrid representation learning and cross-task semantic interaction for AI-driven art knowledge organization.
This paper is organized as follows: Section 2 reviews related works; Section 3 details our architecture; Section 4 evaluates performance against state-of-the-art baselines; Section 5 gives the conclusion and future work.
This section should be clear and sufficiently detailed. Clearly outline the procedures, including a comprehensive explanation of data collection, analysis methods, and statistical approaches used. Specify the sources of any datasets, software, or tools utilized (e.g., database names, software versions, or vendors). If established methodologies are used, cite relevant references instead of providing extensive descriptions. Ensure clarity and precision in the presentation of methods.
Multitask learning has become a key paradigm in computational art analysis, exploiting shared visual features to improve classification across related tasks (Yang et al., 2022; Liu, 2024; Tian and Nan, 2022). Early efforts aggregated large art image collections and trained a single network to predict multiple attributes simultaneously. For example, Strezoski and Worring introduced OmniArt (Strezoski and Worring, 2018), a deep multi-task model with a shared representation for artistic data, and released a large-scale dataset of nearly half a million paintings with rich metadata. Their network was trained jointly on tasks such as artist, style, and material prediction, and was shown to outperform both hand-crafted features and single-task CNN baselines. Similarly, Bianco et al. (2019) proposed a Deep Multibranch CNN that processes different resolutions of the painting in parallel branches, solving artist, style, and genre classification in a unified network. This model was evaluated on the MultitaskPainting100k dataset (100K paintings, 1508 artists, 125 styles, 41 genres), demonstrating strong multi-task performance. These works highlight that jointly learning artist/style/genre helps the model leverage common representations. Recent reviews also note the growing use of multi-task deep learning and large art datasets for painting categorization (Ugail et al., 2023), underscoring that multi-task formulations (e.g., shared backbones or feature exchange) can capture inter-task correlations and improve overall accuracy.
Hybrid networks that combine convolutional layers and self-attention (Transformer) modules have gained traction for visual tasks (Arshad et al., 2024; Fang et al., 2022; Chen et al., 2024). These hybrids aim to marry the local detail encoding of CNNs with the global context modeling of Transformers. One representative example is the Convolutional vision Transformer (CvT), which integrates convolutional token embeddings and convolutional projections into a ViT-style model (Wu et al., 2021). By doing so, CvT inherits desirable invariances from CNNs (e.g., shift/scale invariance) while retaining the dynamic attention and long-range reasoning of Transformers. Empirically, CvT achieved state-of-the-art image classification performance on ImageNet with fewer parameters and Floating Point Operations (FLOPs) than comparable ViT models. More generally, Long (2024) survey the design space of CNN-Transformer hybrids and observe that these architectures can capture multi-scale features, “combining the local features extracted by CNNs with the global features learned by ViTs” to yield strong performance. This synergistic effect has been exploited in diverse domains: for instance, hybrid CNN-ViT models have set new benchmarks in medical and remote-sensing image analysis by capturing both fine-grained texture and global layout. Notably, Shah et al. (2024) demonstrate a practical gain: a three-branch hybrid (stacking CNN and ViT encoders) significantly outperforms a pure ViT on a multi-class disease classification task, confirming that fusing CNN and Transformer features improves discriminative power. These studies motivate our use of a dual-stream backbone that leverages convolutional detail and attention-based context in tandem.
Attention mechanisms have become ubiquitous in modern vision models (Guo et al., 2022a). In CNN-based networks, specialized attention modules reweight features to emphasize salient information. For example, Squeeze-and-Excitation blocks (Hu et al., 2018) apply channel-wise attention, and convolutional block attention module (Woo et al., 2018) extends this with spatial attention. In parallel, self-attention was first integrated into CNNs by Wang et al. (2018) via the Non-Local Network, which models long-range dependencies across the image. This work showed that capturing global interactions in convolutional features significantly boosts tasks like detection and segmentation. Building on this, purely attention-driven Vision Transformers (ViT) (Dosovitskiy et al., 2020) have been developed for classification and other vision tasks. ViTs tokenize the image and use multi-head self-attention to aggregate information globally, and they have demonstrated “huge potential” by achieving competitive or superior results to CNNs on many benchmarks. Attention is also being used to integrate information across tasks or modalities (Soydaner, 2022; Lu et al., 2023). For example, Lopes et al. (2023) introduce a cross-task attention mechanism in a multi-task framework: they use correlation-guided attention to exchange features pairwise between task-specific branches, which enhances the shared representations for all task. This shows that attention can explicitly model task correlations. Inspired by such ideas, our model employs cross-task multi-head attention in the decoder heads to allow style, artist, and genre predictions to attend to each other’s features. In summary, attention modules, whether channel/spatial within a CNN, self-attention in a Transformer, or cross-attention across tasks, are a common tool in vision, enabling more powerful and context-aware feature learning.
In this Section, we first proposed the CNN-Transformer hybrid backbone, which captures local artistic details and global stylistic semantics and is shared by multi-tasks. Then, a cross-task attention mechanism is introduced between task-specific decoder heads, which explicitly captures inter-task dependencies through learnable feature interactions.
In this section, we present the architecture of the proposed Convolution-Transformer Hybrid Attention model (CTHArt) for joint artist, style, and genre classification in fine art paintings. The primary goal of our design is to unify local texture learning and global semantic modeling within a single, end-to-end trainable backbone. To achieve this, we construct a dual-branch network composed of a CNN stream and a ViT stream, as shown in Fig. 2. The CNN branch provides strong locality and texture inductive biases, reducingthe burden on the Transformer to learn low-level visual structures from limited data. The Transformer branch thus focuses on modeling long-range semantic dependencies, improving representational efficiency under data-constrained settings. The CNN branch is based on the ResNet-50 architecture, while the Transformer branch adopts the Swin Transformer framework. Both branches are carefully synchronized in terms of feature map resolution and channel dimensions, enabling effective fusion and interaction across stages. Furthermore, the entire backbone is shared among the multiple classification tasks, which facilitates joint feature representation and captures the intrinsic relationships between artistic attributes.
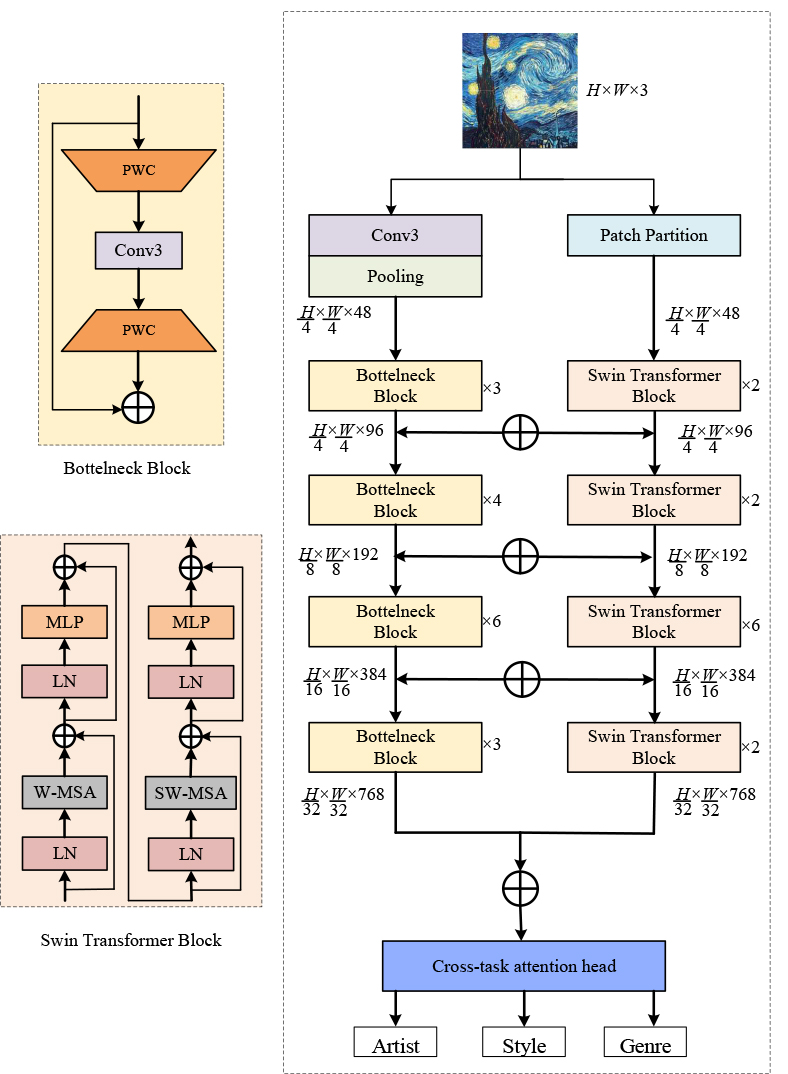 Fig. 2.
Fig. 2.
The architecture of convolutional neural network (CNN)-Transformer hybrid backbone. PWC, Pointwise Convolution; MLP, Multilayer Perceptron; LN, Layer Normalization; W-MSA, Window based Multihead Self-attention; SW-MSA, Shifted windows based Multihead Self-attention.
The proposed CTHArt backbone consists of two parallel and interactive branches:
a CNN stream and a Transformer stream. Each stream processes the input image
through a four-stage hierarchical structure, and their respective outputs at each
stage are fused bidirectionally to enable the integration of local and global
features. Formally, given an input image
The CNN branch follows the structure of ResNet-50 with certain adaptations to
match the hybrid design. The input image first passes through a
In parallel, the Transformer branch adopts the Swin Transformer architecture, a
hierarchical ViT variant designed for scalable image recognition. The Swin
Transformer begins by partitioning the input image into non-overlapping patches,
each of size 4
To promote mutual learning between local and global representations, we
introduce a bidirectional feature fusion mechanism. Specifically, at each stage
These fused features are then passed through the respective stage’s processing blocks. This cross-fusion mechanism introduces a lightweight yet effective inductive bias, enforcing semantic alignment between convolutional and attention-based features. The use of element-wise addition avoids excessive parameterization while ensuring that both branches co-evolve across stages. This strategy enables rich cross-modal interactions and allows the network to simultaneously capture fine-grained local textures (e.g., brushstrokes) and holistic composition cues (e.g., spatial layout, style).
A central feature of CTHArt is the use of a shared CNN-Transformer hybrid
backbone for all classification tasks. This shared representation is advantageous
for multi-task learning, as it allows the model to exploit commonalities and
correlations among the tasks of artist attribution, style recognition, and genre
identification. For instance, stylistic features often serve as strong priors for
inferring genre or even identifying the artist. The outputs from the final stage
of both branches (
The proposed CTHArt network integrates the strengths of CNNs and Transformers in a unified, multitask architecture tailored for art painting categorization. The CNN branch captures local textures and edge details critical for artist and style identification, while the Transformer branch models global relationships and semantic layouts essential for genre recognition. The bidirectional feature fusion and cross-task attention further enhance the model’s ability to jointly learn from multiple, interdependent tasks.
To capture interdependencies among tasks, we introduce a Cross-Task Attention
Head (CTAHead), which operates on the global representation obtained from the
shared backbone as shown in Fig. 3 (Taking MultitaskPainting100k dataset as an
example). The final feature map from the backbone is globally averaged, yielding
a compact representation
with
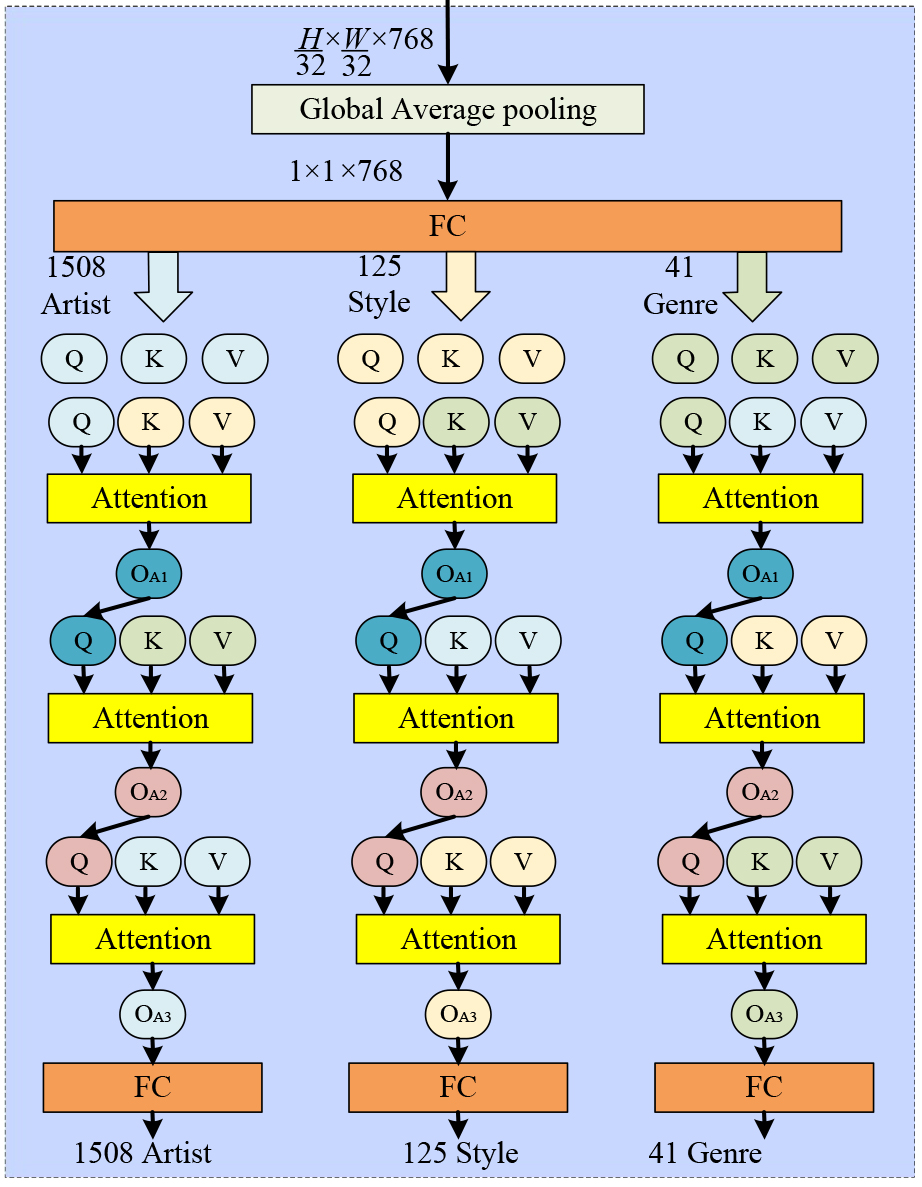 Fig. 3.
Fig. 3.
Architecture of the Cross-Task Attention Head. Three task-specific heads (artist, style, genre) operate in parallel and perform pairwise cross-attention with each other.
To model task dependencies, we employ a cross-task attention mechanism based on parallel task heads with pairwise attention interactions. The three tasks (artist, style, and genre) are predicted simultaneously, and each task head attends to the feature representations of the other two tasks to capture inter-task correlations. Each task attends to the other two through pairwise cross-attention, forming a parallel and mutually interactive multitask prediction structure. The final output of each head is passed through a fully connected layer followed by a softmax operation to yield the artist classification probabilities. The calculation process of artist decoder head is as follows:
Each sub-vector is projected to task-specific query, key, and value vectors:
We first perform attention from the artist task to the style task:
The intermediate output Q1 a is then projected:
Next, artist queries attend to the genre features:
The intermediate output Q1 a is then projected:
The final artist query attends to its own keys and values:
This final artist representation is passed through a fully connected layer and softmax activation.
The similar computation flow is applied for style and genre predictions, with task roles rotated accordingly. This structured cross-attention mechanism enables semantic communication across heads, reinforcing predictions with inter-task context. For instance, an expressionist style feature may support the prediction of a 20th-century genre or a specific artist known for that movement.
This hierarchical attention structure is mirrored for the style and genre heads, with each task attending to the others in a cyclic order. Through this cross-task attention, the decoder heads dynamically exchange semantic information, capturing interdependencies among artistic attributes. This design enhances prediction performance by allowing the network to exploit subtle correlations across tasks, such as stylistic indicators that hint at an artist’s identity or genre-related elements that inform stylistic decisions.
To comprehensively evaluate the performance of the proposed CTHArt model, we con-duct experiments on three widely used benchmark datasets in the domain of computational art analysis: Painting-91 (Khan et al., 2014), WikiArt (Tan et al., 2018), and MultitaskPainting100k (Bianco et al., 2019). These datasets are selected for their diversity in artistic content, their inclusion of multiple classification tasks (e.g., artist, style, genre), and their adoption in previous literature, which enables fair comparisons with existing approaches.
The Painting-91 dataset is one of the earliest curated datasets used in computer vision-based art analysis. It consists of 4266 images from 91 different artists. The artworks cover a variety of painting styles and time periods, making the dataset suitable primarily for artist classification tasks. The number of samples per artist is not uniformly distributed, leading to a moderate class imbalance. This dataset has been extensively used in artist identification tasks and remains a standard benchmark for evaluating model performance in artist attribution.
The WikiArt dataset is a large-scale collection of fine art images compiled from the WikiArt.org repository. It includes over 80,000 images from thousands of artists, spanning various styles, genres, and centuries. For the purpose of consistent benchmarking, we follow the preprocessed version released by previous works, which consists of a curated subset with three label types: artist, style, and genre. Specifically, we adopt a version containing approximately 65,000 paintings with complete labels across all three tasks. The style labels include 27 classes, such as Impressionism, Expressionism, and Baroque, while the genre labels include 10 categories like Portrait, Landscape, and Abstract. Artist labels in this subset span 1195 artists. WikiArt dataset supports multitask classification and allows joint learning of multiple visual attributes. However, due to the large number of artist classes and data imbalance across artists and styles, training robust models on this dataset remains challenging.
The MultitaskPainting100k dataset is a recent large-scale benchmark introduced to facilitate multi-label and multitask learning in computational art understanding. It contains 99,816 images labeled with three hierarchical attributes: 1508 artists, 125 styles, and 41 genres. This dataset is significantly larger and more comprehensive than both Painting-91 and WikiArt, and it introduces several challenges, including extreme label sparsity, high inter-class correlation, and severe class imbalance. Each image is annotated with all three types of labels, making this dataset particularly suitable for evaluating the effectiveness of joint representation learning and cross-task interactions. The large label space (especially for artist classification) poses a challenge for both representation capacity and regularization.
The three datasets used in our study cover complementary aspects of fine art classification. Painting-91 emphasizes artist identification under limited data; WikiArt offers moderate-scale multitask classification with diverse artistic content; and MultitaskPainting100k challenges models with extreme-scale multitask learning. This comprehensive setup allows us to evaluate both the accuracy and scalability of the proposed CTHArt architecture.
To train the proposed CTHArt model effectively across multiple tasks, we adopt a
consistent and robust training strategy based on best practices in deep visual
representation learning. All images are resized to 224
We compare our approach against a broad range of state-of-the-art CNN models [the accuracies of ResNet (He et al., 2016), Res2Net (Gao et al., 2021), ResNeXt (Xie et al., 2017), RegNet (Xu et al., 2023), ResNeSt (Zhang et al., 2022), Efficient-Net (Tan and Le, 2019) are reported in (Zhao et al., 2021)], Transformer-based models [ViT (Dosovitskiy et al., 2020), Swin-Transformer (Liu et al., 2021)], hybrid networks [CMT (Guo et al., 2022b), CoAtNet (Dai et al., 2021)], and report performance across artist, style, and genre classification tasks.
Painting-91 is a relatively small-scale dataset, primarily used to evaluate artist and style classification. Table 1 summarizes the performance of various methods. Our model achieves the highest accuracy on both artist and style classification tasks, with 73.25% and 80.84% respectively. Compared with traditional CNN backbones such as ResNet (58.92%, 66.54%) and Res2Net (58.81%, 70.13%), CTHArt shows significant improvements, highlighting the benefits of integrating Transformer-based global context modeling. Even against more advanced architectures like RegNetX and EfficientNet, our model demonstrates superior results. EfficientNet, known for its scaling efficiency, achieves 71.27% artist accuracy and 79.23% style accuracy, which are both surpassed by our approach. The improvement in artist classification, which typically depends on fine-grained local texture and brushstroke details, suggests that our CNN branch effectively captures discriminative patterns. Meanwhile, the performance gain in style classification implies that the Transformer stream and attention modules successfully encode higher-level semantics and global composition cues.
| Method | (Chu and Wu, 2018) | EfficientNet | ResNet | Res2Net | RegNetX | ResNetSt | Ours |
| Artist | 64.32 | 71.27 | 58.92 | 58.81 | 65.44 | 60.07 | 73.25 |
| Style | 78.27 | 79.23 | 66.54 | 70.13 | 73.35 | 62.96 | 80.84 |
| Mean | 71.30 | 75.25 | 62.73 | 64.47 | 69.40 | 61.52 | 77.05 |
Table 2 presents the results of our model and various baselines on the WikiArt and MultitaskPainting100k datasets. These datasets are larger and more complex than Painting-91, incorporating all three classification tasks: artist, style, and genre.
| Dataset | Method | FLOPs | Artist | Style | Genre | Mean |
| WikiArt | (Zhong et al., 2020) | - | 88.38 | 58.99 | 76.27 | 74.55 |
| (Cetinic et al., 2018) | - | 81.94 | 56.43 | 77.60 | 71.99 | |
| ResNet | 4.2 G | 88.03 | 65.76 | 76.69 | 76.83 | |
| Res2Net | 4.2 G | 88.14 | 65.97 | 76.54 | 76.88 | |
| ResNeXt | 4.2 G | 88.29 | 66.62 | 76.74 | 77.22 | |
| RegNetX | 3.2 G | 89.08 | 67.10 | 76.63 | 77.60 | |
| RegNetY | 4.0 G | 76.29 | 69.51 | 77.41 | 74.40 | |
| ResNetSt | 4.3 G | 88.17 | 69.97 | 77.94 | 78.69 | |
| EfficientNet | 4.2 G | 91.73 | 69.19 | 78.03 | 79.65 | |
| ViT | 55.4 G | 90.65 | 68.49 | 77.84 | 78.99 | |
| Swin-Transformer | 8.7 G | 91.86 | 69.02 | 78.13 | 79.67 | |
| CMT-B | 9.3 G | 92.71 | 69.46 | 78.79 | 80.32 | |
| CoAtNet | 8.4 G | 93.03 | 68.97 | 79.21 | 80.40 | |
| Ours | 7.3 G | 93.24 | 70.65 | 79.64 | 81.18 | |
| MultitaskPainting100k | (Bianco et al., 2019) | - | 56.50 | 57.20 | 63.60 | 59.10 |
| ResNet | 4.2 G | 59.05 | 59.41 | 65.77 | 61.41 | |
| Res2Net | 4.2 G | 61.28 | 60.81 | 66.31 | 62.80 | |
| ResNeXt | 4.2 G | 59.93 | 60.73 | 66.27 | 62.31 | |
| RegNetX | 3.2 G | 59.97 | 60.60 | 65.99 | 62.19 | |
| RegNetY | 4.0 G | 61.22 | 62.80 | 66.82 | 63.61 | |
| ResNetSt | 4.3 G | 62.78 | 62.64 | 67.83 | 64.42 | |
| EfficientNet | 4.2 G | 65.50 | 63.15 | 66.99 | 65.21 | |
| ViT | 17.6 G | 66.05 | 64.32 | 68.02 | 66.13 | |
| Swin-Transformer | 8.7 G | 66.32 | 64.29 | 68.14 | 66.25 | |
| CMT-B | 9.3 G | 67.32 | 64.18 | 67.93 | 66.48 | |
| CoAtNet | 8.4 G | 66.89 | 65.13 | 68.32 | 66.78 | |
| Ours | 7.3 G | 67.49 | 65.07 | 68.99 | 67.18 |
The WikiArt dataset provides a large-scale and diverse benchmark for multi-facet art classification, covering artist, style, and genre simultaneously. As shown in Table 2, our CTHArt model achieves the best overall performance among all compared methods, reaching a mean accuracy of 81.18%, outperforming both pure CNN, pure Transformer, and recent CNN-Transformer hybrid architectures. Compared with strong CNN baselines such as ResNeSt (78.69%) and EfficientNet (79.65%), our model improves the mean accuracy by 2.49% and 1.53%, respectively. This improvement indicates that incorporating global self-attention modeling alongside convolutional inductive bias yields more discriminative representations for complex artistic attributes. In particular, CNN backbones tend to perform competitively on artist classification due to their strength in capturing local texture patterns, but they are relatively weaker in style recognition, which requires more global compositional and semantic understanding.
Transformer-based models such as ViT and Swin-Transformer achieve strong performance, but at higher computational cost. ViT requires 55.4 Giga FLOPs, nearly eight times that of our model, while still yielding lower mean accuracy (78.99%). Swin-Transformer improves efficiency but remains inferior to our method in all three tasks. This demonstrates that a carefully designed hybrid backbone with staged cross-branch fusion can achieve better accuracy-efficiency trade-offs than standalone Transformer architectures.
When compared with recent hybrid models such as CMT-B and CoAtNet, our approach still shows consistent gains. CTHArt achieves the highest accuracy in all three tasks, surpassing CoAtNet by 0.78% in mean accuracy while using lower computational cost (7.3 G vs. 8.4 Giga FLOPs). The most notable gain appears in style classification, where global stylistic semantics and cross-task cues are especially important. This suggests that the proposed cross-task attention head effectively transfers complementary information between artist, style, and genre branches, leading to more semantically consistent predictions.
MultitaskPainting100k is a more challenging large-scale multitask benchmark with a very large artist label space and strong class imbalance. As reported in Table 2, 400 the proposed CTHArt model again achieves the best overall performance, with a mean accuracy of 67.18%, outperforming all compared CNN, Transformer, and hybrid baselines.
Compared with the original multitask CNN model (Bianco et al., 2019), our method improves the mean accuracy by more than 8 percentage points, confirming the effectiveness of hybrid representation learning and explicit cross-task interaction under extreme label cardinality. Traditional CNN backbones such as ResNet, Res2Net, and RegNet variants achieve mean accuracies in the range of 61–64%, indicating limited capacity in modeling long-range structure and cross-facet semantics when tasks are learned jointly.
Transformer-based models provide stronger global modeling and show clear gains over CNNs. ViT and Swin-Transformer reach mean accuracies of 66.13% and 66.25%, respectively. However, our model still surpasses them while requiring fewer FLOPs than ViT and slightly less than Swin. This suggests that combining convolutional texture priors with hierarchical Transformer features is more data-efficient than relying on attention mechanisms alone, especially in fine-grained art datasets where training samples per class can be limited.
Among hybrid architectures, CMT-B and CoAtNet also show competitive performance, with mean accuracies of 66.48% and 66.78%. Our model further improves the mean score to 67.18%, achieving the best artist accuracy (67.49%) and genre accuracy (68.99%). Overall, the WikiArt and MultitaskPainting100k results verify that the proposed multitask hybrid architecture not only improves accuracy across all facets but also maintains favorable computational efficiency. Notably, the performance gains on MultitaskPainting100k are consistent but more moderate than those on WikiArt. This behavior is expected due to the heavier label imbalance and larger class space, which increases task difficulty and reduces the margin between strong models. Nevertheless, the proposed method still delivers the top overall performance with controlled computational complexity.
In addition to accuracy, we further evaluate our model using macro F1-score on datasets with strong class imbalance. On WikiArt and MultitaskPainting100k, our method achieves F1-scores of 0.74 and 0.62, respectively. Since prior published methods on these benchmarks report only accuracy and do not provide precision/recall or F1 statistics, direct F1 comparison is not available. We therefore report F1 results for our model to provide complementary and more imbalance-aware evaluation while keeping accuracy-based comparisons for fairness with existing literature.
To better understand the contribution of the proposed CTAHead, we conduct an ablation study by comparing the full CTHArt model with a reduced variant where the CTAHead is removed. In the ablated model, the global feature vector obtained from the backbone is directly passed to three independent fully connected layers for artist, style, and genre classification, without any task interaction or attention-based reasoning. All other components (hybrid backbone, training protocols) remain identical. As shown in Fig. 4, the mean accuracy was improved by more than 1% on three datasets, with the help of CTAHead.
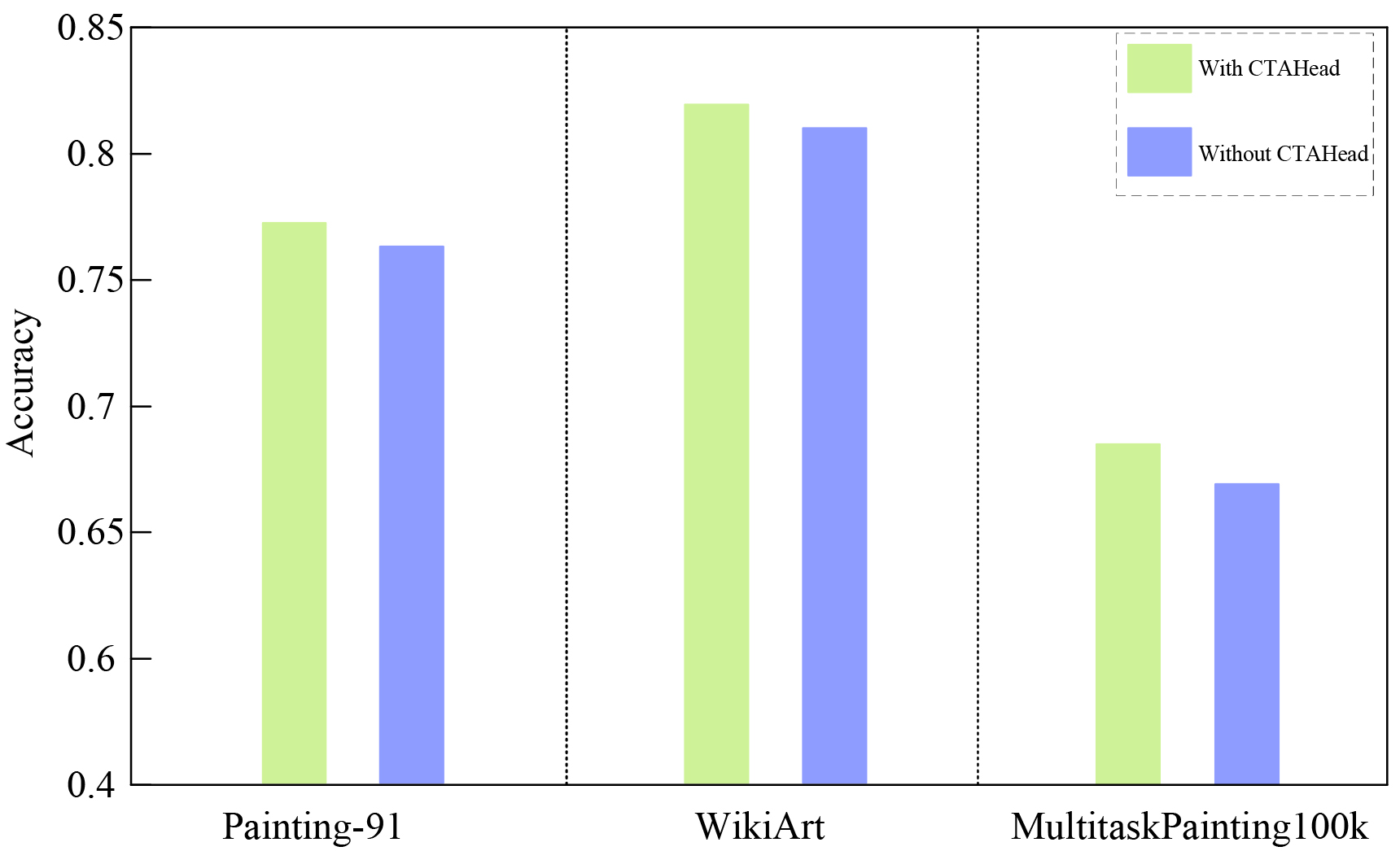 Fig. 4.
Fig. 4.
The results of ablation study. CTAHead, Cross-Task Attention Head.
Ablation experiments demonstrate that removing CTAHead leads to notable performance drops across all tasks, confirming its critical role in the architecture. By embedding structured attention across artist, style, and genre representations, CTAHead elevates the model’s capacity for nuanced interpretation in the artistic domain.
In this work, we presented CTHArt, a CNN-Transformer hybrid multitask framework for fine art painting categorization across artist, style, and genre facets. The proposed architecture integrates a dual-branch hybrid backbone with stage-wise cross-branch fusion, enabling the model to jointly capture fine-grained local artistic details and global semantic structure. On top of the shared backbone, we introduced a Cross-Task Attention Head to improve accuracy by inter-task dependencies.
Extensive experiments on Painting-91, WikiArt, and MultitaskPainting100k demonstrate that the proposed model consistently outperforms strong CNN, Transformer, and recent hybrid baselines, achieving state-of-the-art accuracy with competitive computational cost. The gains are especially evident in multitask settings with large label spaces and class imbalance, confirming the benefit of hybrid representation learning and cross-task semantic interaction. Beyond accuracy gains, the proposed framework also provides a practical technical pathway for AI-assisted knowledge organization in large-scale art repositories, supporting coordinated facet assignment and semantically consistent metadata construction. Future work will explore lighter-weight hybrid designs, more advanced task-relation modeling strategies, and extensions to additional art attributes and multimodal cultural heritage data.
All data reported in this paper will be shared by the corresponding author upon resonable request.
LW: Formal Analysis, Methodology, Software, Writing - Review & Editing, Validation. QL: Funding Acquisition, Supervision, Writing - Original Draft, Visualization, Resources. DW: Project Administration, Investigation, Conceptualization, Data Curation. DW reviewed the paper critically for important intellectual content. All authors contributed to editorial changes in the manuscript. All authors have reviewed the final version of the manuscript and have agreed to its publication; all authors take responsibility for the study.
Not applicable.
This research was funded by Shandong Province Cultural and Tourism Research Project (Project No. 24WL(Y)91).
The authors declare no conflicts of interest.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.