























 , Shakeeb Arzoo 1
, Shakeeb Arzoo 11 Documentation Research and Training Centre, Indian Statistical Institute, 560059 Bangalore, India
Abstract
This work introduces OntoBio, a biographical ontology grounded in Linked Data principles. The study reviews existing ontologies to identify limitations in their ability to represent the diversity and complexity of individual lives. To address these gaps, we developed OntoBio using a tripartite framework encompassing Personality, Environment and Milieu, and Achievements/Milestones. This framework is supported by an expressive vocabulary designed to capture the multifaceted nature of biographical knowledge. OntoBio provides a structural foundation for the semantic integration of existing ontologies that only partially represent biographical data. We present a set of use-case scenarios that motivated OntoBio’s development and highlight its key modeling features. To ensure robustness and interoperability, OntoBio was developed following the Yet Another Methodology for large-scale faceted Ontology Construction (YAMO) methodology and in compliance with World Wide Web Consortium (W3C) standards, including Resource Description Framework (RDF), Web Ontology Language (OWL), and SPARQL Protocol and RDF Query Language (SPARQL). Finally, we evaluate the ontology by constructing a biographical knowledge graph illustrating the life of a prominent individual.
Keywords
- ontology
- biographical ontology
- knowledge representation
- semantic web application
- knowledge graph
- personal knowledge graph
- linked data
Biographical knowledge has traditionally been expressed in textual form, one of the most enduring genres of literature, as the lives of eminent individuals continue to fascinate us. Canonical biographies of notable figures often reveal multiple layers of meaning, presented from diverse perspectives that render them complex information artifacts. This complexity unfolds on two levels. First, biographical data are inherently open-ended—frequently incomplete, contested, and subject to reinterpretation. New evidence can emerge at any time, reshaping our understanding and assessment of a person’s life. Second, complexity arises from the diversity of resources that convey biographical information. Biographical research relies on heterogeneous data sources, and it is widely acknowledged that consulting multiple sources to corroborate and authenticate information is essential for maintaining scholarly integrity.
Ontologies represent a sophisticated form of knowledge organization, offering numerous advantages for information systems built on Semantic Web principles (Uschold, 2008; Giunchiglia et al., 2014). These include semantic search, reasoning and analytics, knowledge sharing, and reuse. To leverage these benefits, several initiatives have sought to develop biographical ontologies capable of representing knowledge about individuals in a machine-processable manner. In developing OntoBio, we aimed to integrate prior efforts and consolidate diverse vocabularies within a unified framework to support the semantic exploration of biographies.
Our analysis of existing ontologies revealed that most adopt distinct approaches, each focusing on specific aspects of a biography. To the best of our knowledge, none have attempted to develop a vocabulary encompassing the broad and familiar dimensions of human life—such as daily routines, dietary and dressing habits, organizational affiliations, and personality traits. Currently, representing these aspects requires navigating across multiple domain-specific ontologies: healthcare ontologies for health-related issues, food ontologies for dietary habits, organizational ontologies for education and employment, and so forth. Furthermore, the uniqueness of each individual life poses additional challenges for any classificatory schema.
The objectives of this study are as follows:
(1) To develop a biographical ontology enriched with contextual entities capable of representing biographical facts from the life of an eminent individual (Isaac, 2013).
(2) To design an interoperable, lightweight, and extensible schema (Giunchiglia et al., 2009) that integrates other vocabularies in accordance with Linked Data (LD) principles (Heath and Bizer, 2011).
(3) To establish an ontology that serves as a foundation for semantic applications supporting information retrieval, data analytics, and inferencing.
To achieve these objectives, we examined the domain of biographies through three complementary perspectives (or facets; see Section 4.1) and systematically organized the available knowledge. This faceted approach is both intuitive and novel in its implementation. In alignment with LD principles, OntoBio reuses as many existing vocabularies as possible, acting as a bridge to other domain ontologies, such as Healthcare, Occupation, and Information Resource, through a lightweight schema that can be further extended for web publication.
The principal contributions of this paper are:
(1) The introduction of OntoBio, a biographical ontology designed to capture the diverse aspects of an individual’s life.
(2) A comparative analysis of existing biographical ontologies that underscores the need for OntoBio.
(3) A conceptual discussion of essential biographical knowledge using a faceted approach that defines OntoBio’s structure.
(4) A use case scenario demonstrating the construction of a biographical knowledge graph.
The remainder of the paper is organized as follows: Section 2 presents a literature review highlighting the unique contributions of OntoBio; Section 3 introduces the motivating use case; Section 4 details the ontology’s conceptualization, design, and results; Section 5 describes the construction of a biographical knowledge graph and its modelling aspects; and Section 6 concludes the study with reflections on its limitations and directions for future research.
Information about individuals exists across diverse document formats, resulting in data heterogeneity that complicates interoperability. These sources often contain overlapping or incomplete information, requiring additional processing to determine their nature and scope. The core value of describing a person through an ontology lies in modelling rich relationships among people, organizations, places, roles, and activities—enabling machines to interpret and reason over this knowledge for inference and analytics. Building on Declerck and Sprugnoli (2017), we provide a brief overview of existing biographical ontologies.
The first ontology to formally represent a person’s life was Biographical Information Ontology (BIO1), a vocabulary for biographical information. Its core idea is to model life as a sequence of interconnected events, such as birth, marriage, coronation, or death to form a narrative. Although these events are not exhaustive, BIO allows linking with other vocabularies (e.g., education, employment, travel) to construct a detailed timeline of a person’s life and relationships. Building on this, the Biography Light Ontology (BLO) developed by Ramos (2009) adopts an event-centric approach to collective biographies, addressing the “4Ws” of human life—who, what, where, and why. BLO provides a lightweight framework for structuring common life events, including health changes, personal relationships, relocations, affiliations, occupations, and discoveries.
Biographical Conceptual Reference Model (BIO-CRM) advances prosopographical research by providing a shared semantic framework for life stories from heterogeneous sources (Tuominen et al., 2017). Like BLO, it adopts an event-based approach in which actors are assigned roles within a spatiotemporal context to promote interoperability. Building on BIO-CRM, Hyvönen et al. (2019) developed the Semantic National Biography of Finland (BiographySampo), which enhances biographical dictionaries through Linked Data principles. Its knowledge graph, generated via an NLP pipeline, automatically reconstructs the life stories of Finnish individuals—linking people, places, social networks, life maps, and relationships—resulting in a database of about 13,000 biographical entities connected to external datasets such as Wikipedia for public access.
The Semantic Computing Research Group of Finland also created CultureSampo (Hyvönen et al., 2009), which semantically models Finland’s cultural artefacts—art, music, and paintings—using an event-centric approach. Similarly, OntoLife (Kargioti et al., 2009) is an agent-centric biographical ontology designed to “semantically manage personal information”. Structurally similar to OntoBio, it centers on the Person class, enriched with properties describing social relationships, biological and demographic attributes, education, and life events, while incorporating external ontologies such as Friend of a Friend vocabulary (FOAF) and ResumeRDF.
Shimizu et al. (2020) developed the Enslaved Ontology, a modular framework reconstructing the lives of Africans involved in the transatlantic slave trade. This state-of-the-art system integrates historical data from diverse sources into the Enslaved Knowledge Graph, offering a comprehensive resource for researchers and the public. Likewise, Nguyen et al. (2023) introduced Culture, Race, Ethnicity, and Nationality Ontology (CRENO), an ontology for semantically profiling individuals by race, ethnicity, and nationality to standardize datasets and terminology in support of public health research and diagnosis.
In addition to dedicated biographical ontologies, several others partially capture biographical information. The FOAF2 vocabulary describes individuals along with their social networks and interests, while the Virtual Integrated Knowledge Organization ontology (VIVO) (Corson-Rikert et al., 2012) models scholarly activities for researchers and organizations. CV-type ontologies, such as ResumeRDF, represent a person’s qualifications, skills, and basic biographical data. An extension of FOAF, FOAF+ (Amith et al., 2020), was recently introduced to capture the dynamics of human interaction in various social contexts for public health research. As OntoBio aspires to serve as an integrative framework, these vocabularies have been selectively reused within our ontology.
The key distinction of our study lies in its person-centric rather than event-centric focus, enabling the representation of the major facets of an individual’s life. As summarized in Table 1, we semantically enrich the smallest units of biographical information within the ontology. This approach closely mirrors traditional textual biographies, which aim to portray an individual’s identity, experiences, and relationships within their broader historical and social context. Table 1 outlines the principal differences between this study and previous efforts in the field.
| Previous studies | Current study |
| Most existing ontologies adopt an event-centric approach, focusing on key life phases such as birth, death, marriage, changes in social status, and health transitions. | OntoBio is an agent-centric ontology enriched with contextual entities, representing an individual’s life through three complementary and interconnected perspectives: Personality, Environment and Milieu, and Achievements/Milestones. |
| The reviewed ontologies aim to address the fundamental questions of what, where, who, and when (the 4Ws) in people’s lives. | It seeks to comprehensively represent the major aspects of an eminent individual’s life through a categorical approach. By identifying essential facets and decomposing them into their fundamental components, these elements are then modelled within the OntoBio ontology. |
| Existing biographical ontologies capture the key relationships between the biographee and their significant others. | The focus of this work is the biographee and their social networks, providing a comprehensive description of all relationships, personal, familial, adversarial, mentorships, peers, and acquaintances. |
| Our investigation found that existing ontologies address places associated with individuals’ lives only superficially. | This study builds detailed connections between individuals and the places they frequented or were linked to, an approach previously seen only in the Bio-CRM ontology. |
| In our review of biographical ontologies, we found no attempts to model the personality traits exhibited by individuals. | A key aspect of OntoBio is capturing a person’s personality traits based on commonly observed behaviours noted by others. |
| Conflicting biographical data often appear across sources, but previous ontologies do not address this ambiguity. | OntoBio supports multiple “sources of truth” by using annotation properties to capture provenance, enabling users to verify the accuracy and reliability of biographical statements. |
| Previous ontologies did not integrate knowledge of food habits, dress styles, health, creative works, daily activities, and similar aspects within a single framework. | This study addresses these essential aspects through formal representation within the OntoBio ontology. |
We present various types of information commonly found in biographies, using S. R. Ranganathan, a visionary in Library and Information Science (LIS) (Yogeshwar, 2001), as the biographical subject. The following passages, compiled from multiple sources (Gopinath, 1978), are numbered for reference.
Sc. 1: S. R. Ranganathan (1892–1972) was born in Shiyali, Thanjavur, to Ramamrita Ayyar, a landlord, and Seethalakshmi, a homemaker, of the South Indian Ayyar community. He earned a degree in Mathematics (1913) from Madras Christian College under the mentorship of Edward B. Ross, his lifelong guide.
Sc. 2: In 1924, S. R. Ranganathan traveled abroad for the first time aboard the British ship SS Mariana to pursue professional training in Library Science. His journey began in Washermenpet (Chennai) and ended in London.
Sc. 3: In 1936, Ranganathan collapsed while returning from a wedding, experiencing severe pain and immobility. A doctor diagnosed a torn calf muscle in his left leg and prescribed rest, which he initially followed. During his recovery, family members supported him in moving around.
Sc. 4: In the 1930s, while in Madras, Ranganathan maintained a strict daily routine—rising at dawn, walking near Marina Beach around 6 a.m., visiting the market, reviewing his previous night’s writing, shaving and bathing, performing puja, having breakfast, playing with his son, and then heading to work.
Sc. 5: Ranganathan is celebrated as the Father of Library Science in India, and his work continues to inspire research in the field. He helped establish key institutions and maintained connections with renowned figures such as G. H. Hardy, Sir Maurice Gwyer, Sir Frank Francis, Douglas Foskett, P. C. Mahalanobis, Sir A. L. Mudaliar, and S. Radhakrishnan. His students, including A. Neelameghan, M. A. Gopinath, P. N. Kaula, and S. Parthasarathy, became prominent scholars. For his contributions, he received numerous honors, most notably being named National Research Professor in 1965.
The biographical data presented here encompass a range of conceptual categories, including Person, Relationships, Travels, Food, Accomplishments, and Health Records. The designed ontological model, OntoBio, captures the smallest units of biographical information across these categories through a graph-based representation, offering the advantages outlined in the Introduction. In Section 5, we illustrate OntoBio’s potential by demonstrating its knowledge representation capabilities using the passages discussed above. The following section outlines our methodological approach to deconstructing the biographical domain, which guided the design and development of the OntoBio ontology.
The ontology development process comprises two key components: understanding the essential features of biographical knowledge (discussed in Section 4.1) and designing an ontology capable of representing that knowledge (discussed in Section 4.2). These components correspond to the top-down and bottom-up approaches to ontology development outlined below.
Ontology development can be approached in several ways, often depending on the use case, application requirements, and available resources (Kendall and McGuinness, 2019). A widely adopted method integrates both top-down and bottom-up strategies:
Top-Down Approach: This method begins with a high-level view of the domain, organizing abstract concepts first. Once these broader concepts are established, specific entities and relationships are identified to create a strong conceptual foundation.
Bottom-Up Approach: This method starts with detailed data, grouping elements based on their similarity and relatedness. These base-level clusters are then generalized into higher-level abstract concepts.
Both approaches, however, have their own limitations (Dutta et al., 2015). A balanced integration that combines breadth at the top level with depth along selected branches is generally recommended for developing flexible and robust ontological models (Kendall and McGuinness, 2019). Given that our study aims to distill the essence of biographical knowledge, it draws on the strengths of both approaches. These are discussed in the following subsections: Aspects of Biography and Biographical Ontology Development Methodology.
A comprehensive definition of biography appears in A Glossary of Literary Terms, which describes it as “a relatively full account of a particular person’s life, involving the attempt to set forth character, temperament, and milieu, as well as the subject’s activities and experiences” (Abrams, 1991). This definition captures the essence of biographies central to our study, establishing the key dimensions we aim to model and represent. The ongoing attempt to encapsulate biographical knowledge has given rise to diverse methods and approaches to its composition. Denzin (1989) succinctly characterizes the biographical method as “the studied use and collection of life documents that describe the turning-point moments in an individual’s life”.
Our review of existing biographical ontologies (see Section 2) revealed a lack of expressive and comprehensive vocabularies capable of addressing these dimensions. Consequently, our first step was to identify the inherent features of biographical knowledge that necessitate a rich lexicon within a formal representation. We adopted a faceted approach to capture this complexity, ensuring that our terminology aligns with that used in canonical biographical research.
While previous ontologies have largely overlooked the richness and diversity of individual lives, understanding this complexity requires dissecting the multifaceted dimensions of human existence. One way to approach this is by asking: What makes a person a person? In other words, what criteria allow us to reconstruct a person within their historical and social context? At a fundamental level, a person must:
To the defining characteristics of personhood outlined above, we must add spatial and temporal qualifiers—where and when events occurred (e.g., birthplace and date, place of work and date)—to situate individuals within a concrete context. Additionally, establishing causal linkages among these features (e.g., transitions from education to employment or illness to recovery) enables the reconstruction of a person’s life in a coherent and meaningful form. In essence, the biographical method involves collecting relevant facts and interpreting them to reveal patterns of life experience. These foundational concepts, corresponding to the bottom-up approach of gathering biographical data, are discussed in the next section.
Formally, a person can be understood as a manifestation of matter situated within a specific locus of space and time. Endowed with agency, individuals interact with and are shaped by their environment, participating in various life events such as education, employment, marriage, travel, and health issues. These events provide a natural basis for structuring biographical knowledge.
While some classification schemes facetize a person’s core attributes (Binding et al., 2021), our review of the literature reveals three foundational categories for organizing biographical information. For instance, Boyd (1990, 1991), in his biography of Nabokov, clusters subject entries into Life and Character, Work and Thought, and Publications. Similarly, Westfall (1979) organizes Newton’s life and work along comparable lines. Generalizing these, our study adopts the triadic framework of Personality, Environment and Milieu, and Achievements/Milestones. It is worth noting here that although our triadic classification is based on biographies of exceptional academicians and scholars, we perceive the categories—Personality, Environment and Milieu, and Achievements/Milestones—apply broadly to politicians, statesmen, actors, and other notable individuals. This aligns with Hjørland’s eighth approach to domain analysis: “Epistemological and critical studies organize the knowledge of a domain in paradigms according to the basic assumptions of knowledge and reality” (Hjørland, 2002).
Fig. 1 depicts them as overlapping circles. The intersection of all three circles represents the central individual (the subject of the biography), while the overlapping areas illustrate their increasing sense of agency and involvement in the events that shape their life.
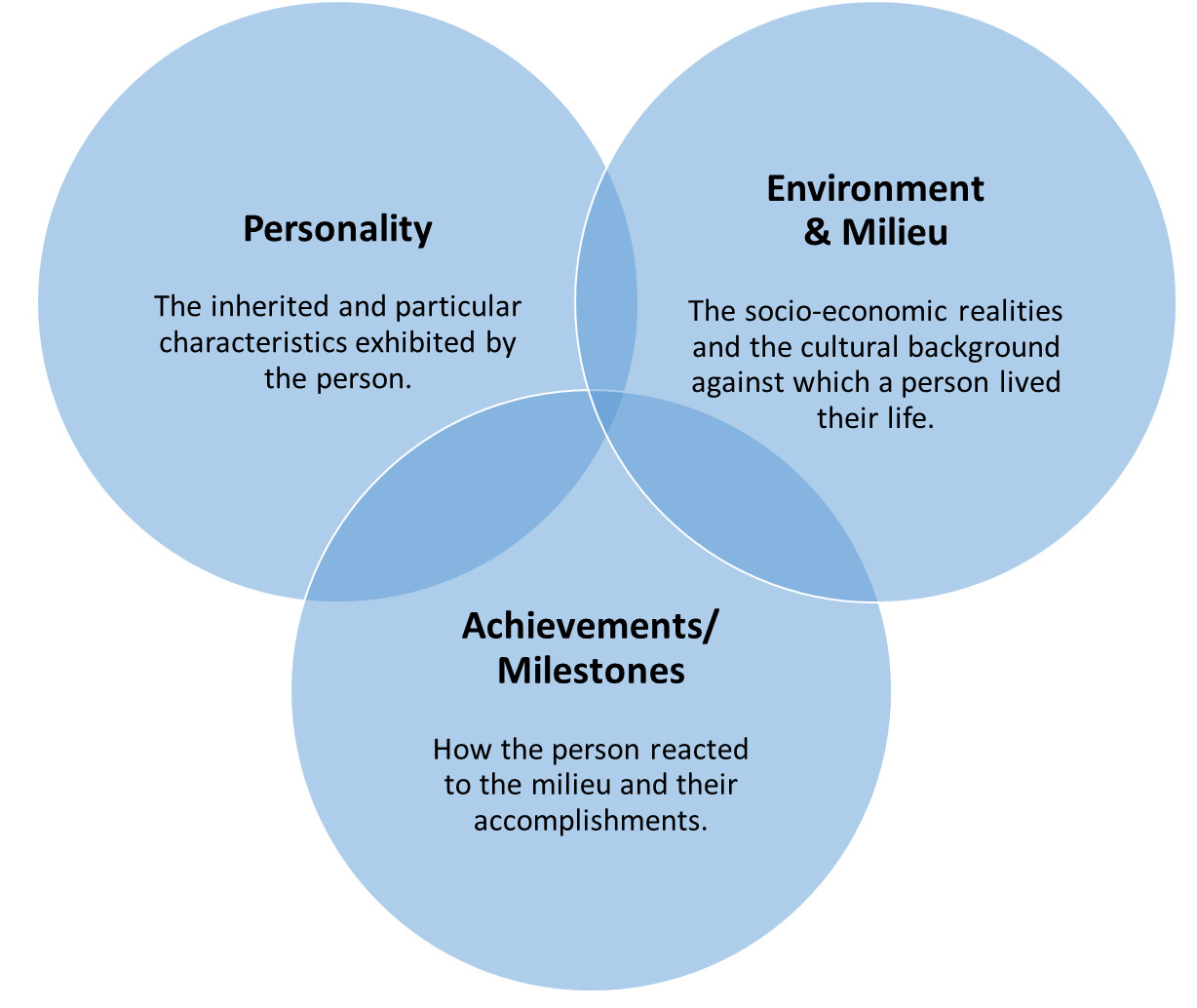 Fig. 1.
Fig. 1.
Aspects of biography.
The personality of an individual encompasses biographical information that is highly personal and individualistic. It serves as the lens through which a person’s identity is expressed. While an individual’s actions are categorized under Achievements, the Personality aspect plays a crucial role in facilitating their expression. In Fig. 2, we break down personality into its tangible and intangible manifestations. The facets that constitute the Personality aspect include dressing habits, food preferences, personality traits, interests, beliefs, and more. The derivation of these facets is detailed in Section 4.2. It is important to note that some facets, such as gender and physical features (e.g., height, complexion) may be influenced by social environment or biology, yet they are intrinsic enough to the individual that they are not categorized elsewhere.
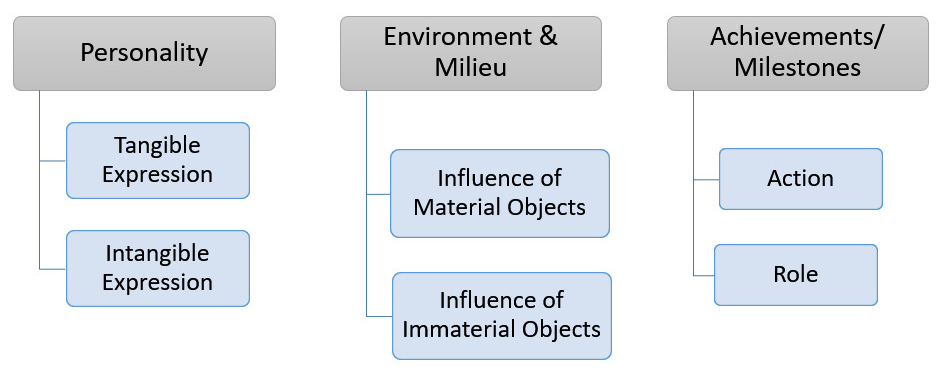 Fig. 2.
Fig. 2.
A deconstruction of biographical knowledge.
Environment and Milieu encompass a range of facets and sub-facets that act as a melting pot in shaping and moulding a person’s character. The presence of external objects within an environment necessitates a relationship with the individual, which is established through their actions. Consequently, the influence of both material and immaterial objects on the individual forms the core of this facet (see Fig. 2). Familial (immediate and extended) and social relationships (friends, mentors, acquaintances) are some of the networks that develop through this aspect (see also Step 3 in Section 4.2). Similarly, immaterial connections, such as linguistic preferences and spiritual beliefs, are more strongly shaped by a person’s surroundings than by their Personality facet.
Achievements/Milestones are the outcomes that emerge from the interplay of the two previously mentioned aspects. Personality provides an individual with a sense of agency that shapes their actions, while the environment influences those actions by providing context. Achievements, therefore, represent the significant milestones a person attains throughout their life. This includes creative contributions, roles, and functions within various institutions such as education, employment, and affiliations. Since biographies often focus on eminent individuals, their societal impacts—such as charitable donations, notable quotes, and honours received—are also considered part of their achievements. In essence, these facets reflect the individual’s growth and development, illustrating a progression from learning to maturity and expertise in relation to their society and era. In Fig. 2, we generalize these facets into two categories: action (which is more active in nature) and role (which is more passive), to help organize the concepts.
The three facets discussed here form the foundational framework of OntoBio, representing a top-down approach to developing the domain ontology. To complement this, we adopt a bottom-up, data-driven method that enriches the model by incorporating terminology and information drawn from biographical literature.
The field of ontological engineering has a history spanning over thirty years, which accounts for the abundance of development methodologies available. Ontology Development Methodologies (ODMs) typically involve steps such as domain identification, formulation of competency questions the ontology should address, identification and standardization of terms for knowledge representation, establishment and classification of domain entities and their relationships, populating the model with relevant data, and model evaluation (Sinha et al., 2022). For OntoBio, we have primarily followed the Yet Another Methodology for large-scale faceted Ontology Construction (YAMO) methodology, which supports the construction of large-scale, faceted ontologies (Dutta et al., 2015). The design steps for OntoBio are illustrated in Fig. 3.
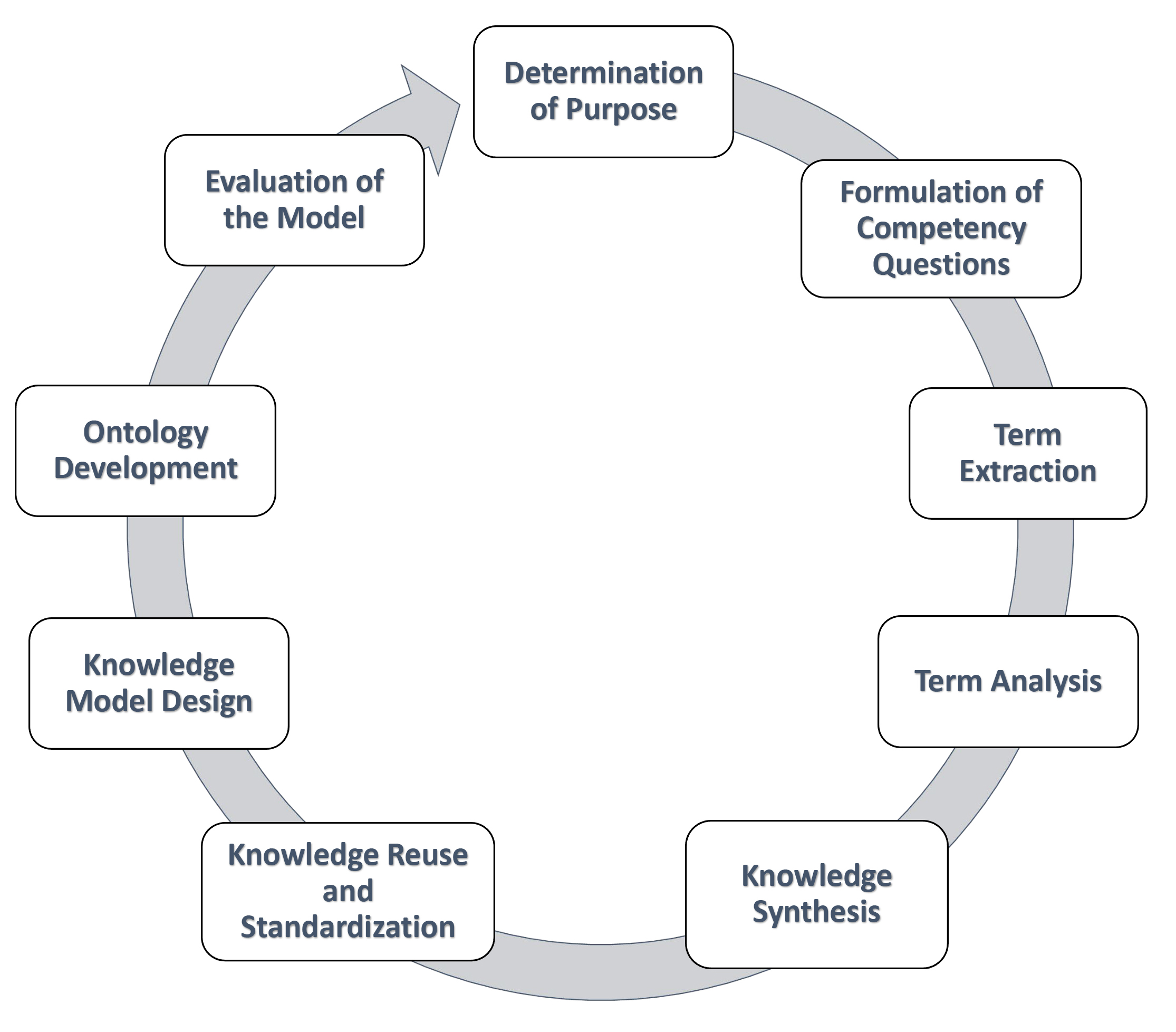 Fig. 3.
Fig. 3.
Yet Another Methodology for large-scale faceted Ontology Construction (YAMO) methodology.
S1. Determination of Purpose: In the initial stage, the purpose and intended application of the ontology are defined. Our goal was to develop a comprehensive, integrative model capable of encompassing the diverse types of biographical data associated with an eminent individual across various sources.
S2. Formulation of Competency Questions (CQs): This step builds on the previous one by defining a set of competency questions that the ontology aims to answer. These questions can also be derived from the use scenario discussed earlier (see Section 3). Examples of such queries include:
(1) What notable travels did the individual undertake?
(2) What were the person’s food habits like?
(3) What was his/her daily routine like?
(4) What were the details of employment?
(5) What were the different relationships that the concerned person was involved in?
(6) What significant awards were conferred upon the individual?
S3. Term Extraction: This step involves collecting the most common terms used within the biographical domain. To accomplish this, we consulted indexes from prominent biographies of eminent figures such as Newton (Westfall, 1979), Pushkin (Binyon, 2002), Nabokov (Boyd, 1990; Boyd, 1991), and others. Examples of these terms include awards, food habits, dressing habits, daily routines, influences and inspirations, endowments, religious practices, travels, and more. Fig. 4 presents a biographical index compiled from the sources mentioned above.
 Fig. 4.
Fig. 4.
Index of terms collected from different biographical texts.
S4. Term Analysis: The terms collected in the previous step must be analyzed and grouped into clusters of related concepts. The YAMO methodology recommends applying several guiding principles to form these clusters based on shared characteristics. These include the principles of relevance, ascertainability, permanence, exhaustiveness, context, among others (Ranganathan, 1967). For a more detailed discussion of these principles, the reader is referred to earlier works by Dutta et al. (2011) and Dutta and Patel (2022).
In this study, we identified several clusters of related concepts from the collected terms. For example, daily routines typically include activities such as waking up, drinking, eating, commuting, working, and sleeping. These “activities” represent a series of actions performed to achieve specific purposes and have been described as the “semantic description of an action” (Snell and Prodromou, 2017). The examples mentioned here—waking, feeding, commuting, bathing, sleeping, etc.—can be categorized as Activities of Daily Living (Physiopedia, 2023). Similarly, other activities grouped by shared characteristics include Religious Activity, Recreational Activity, Occupational Activity, and more. Fig. 5 illustrates this classification based on common features. This process of abstraction was extended to group other clusters of related terms according to their feature similarities.
 Fig. 5.
Fig. 5.
Concept hierarchy for activities.
S5. Knowledge Synthesis: This stage involves integrating knowledge by organizing concepts into hierarchical structures. Grouping concepts into parent-child or broader-narrower relationships typically reflects standard taxonomies found across various domains. Figs. 5,6,7 illustrate such concept hierarchies for everyday activities, educational aspects, and food intake, respectively.
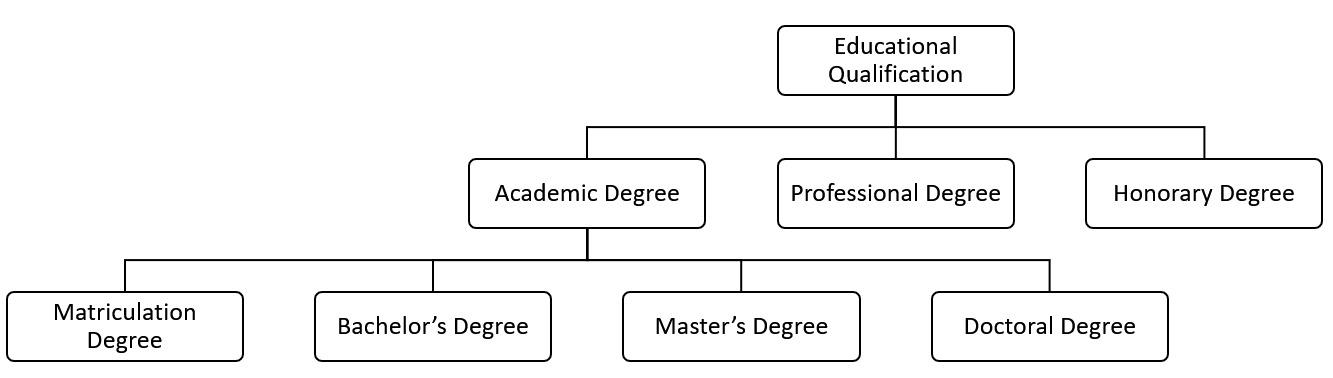 Fig. 6.
Fig. 6.
Concept hierarchy for educational degrees.
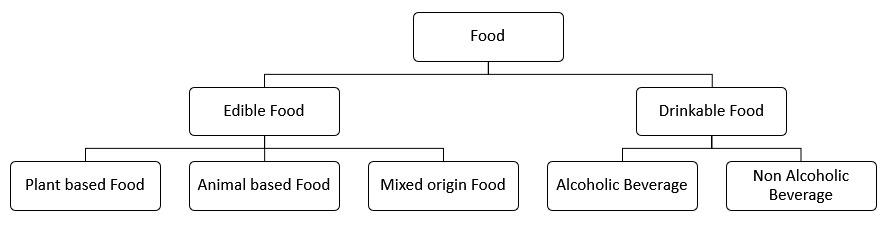 Fig. 7.
Fig. 7.
Concept hierarchy for food.
Section 4.1 identified the core elements of the biographical domain. Following the YAMO methodology, we conducted term extraction and subsequent analysis, grouping terms based on their similarities. This synthesis of knowledge through concept hierarchies enables us to further expand the three major biographical aspects—Personality, Environment & Milieu, and Achievements/Milestones—into categories commonly found in biographical indexes (see Fig. 4). Accordingly, Fig. 8 extends our triadic classification by mapping these aspects to their occurrences in biographical literature, forming the foundational structure of the OntoBio ontology, as discussed in Step 8.
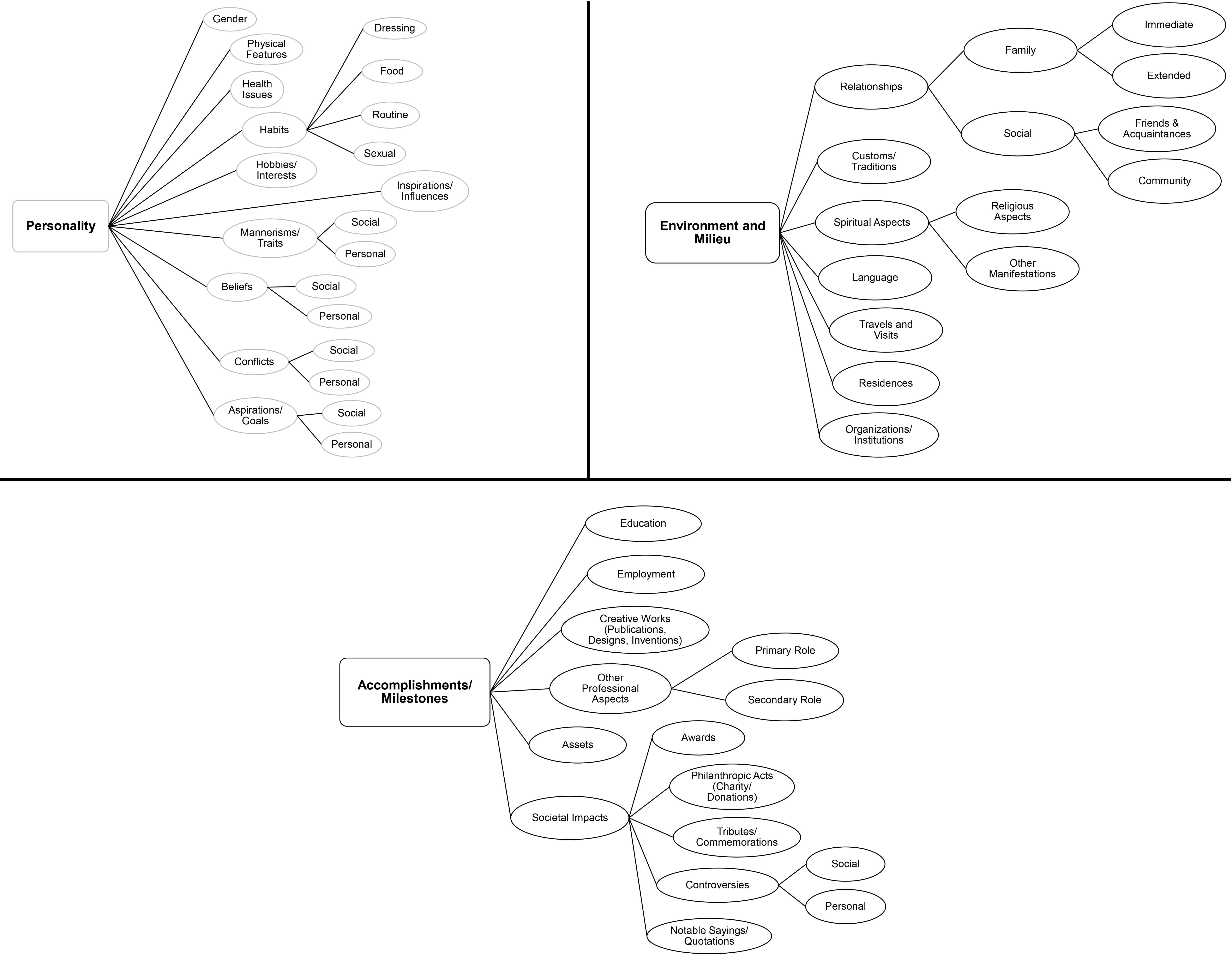 Fig. 8.
Fig. 8.
A feature rich view of the triadic classification of biographical knowledge.
S6. Knowledge Reuse and Standardization: Designing a common, shared vocabulary requires the reuse and standardization of terms. In developing OntoBio, common concepts such as Places and Gender were reused from Schema.org; Agent from the FOAF vocabulary; and Organization from the W3C-recommended Organization ontology4. The Bibliographic Ontology5 (BIBO) and Algorithm Metadata Vocabulary (AMV) vocabulary (Dutta and Patel, 2022) were employed for representing publications. Additionally, the BIO vocabulary was used for concepts like Marriage and Employment, while the Relationship vocabulary6 captured the diverse relationships among people. To represent various health issues, we reused the OpenCare Ontology7. ResumeRDF3 and the VIVO ontology (Corson-Rikert et al., 2012) supported representation of academic affiliations and accomplishments. A classification of occupations was adapted from ISCO-08 (International Labour Office, 2023). Finally, to enrich entities contextually, OntoBio also reuses terms from Wikidata8 and DBpedia9. This approach to term reuse aligns with the guidelines of the Linked Data Vocabulary (Janowicz et al., 2014), making OntoBio a linked data vocabulary.
S7. Knowledge Model Design: This phase focuses on designing the various facets of domain knowledge compiled in earlier steps. It provides structure to the ontology by defining classes, properties, and attributes that enable effective knowledge representation. Fig. 9 presents a high-level UML diagram of the OntoBio ontology, showing selected classes, object properties (OPs), and data properties (DPs). Several of these classes and OPs have been reused from the vocabularies referenced in Step 6. Following the best practices outlined in the Five Stars of Linked Data Vocabulary Use (Janowicz et al., 2014), we declared axioms such as owl:equivalentClass, rdfs:subClassOf, owl:equivalentProperty, and rdfs:subPropertyOf for terms within the OntoBio namespace. For instance, the class amv:InformationResource is reused and declared rdfs:subClassOf schema:CreativeWork. Likewise, the OP OntoBio:specialization is aligned with the Wikidata property wd: P101 (“field of work”) and formally asserted within the ontology.
 Fig. 9.
Fig. 9.
A partial schema diagram of the OntoBio ontology. Terms with prefixes indicate reused concepts from external vocabularies, whereas terms without prefixes represent concepts defined within OntoBio itself.
Sample descriptions of several classes and their corresponding properties are presented in Table 2 and Table 3, respectively. Prefixes are included before each class and property to indicate reuse from existing vocabularies.
| Class name | Description | Some instances |
| foaf:Agent | An agent (person, group, organization, etc.) is a thing that does something. | GovtOfIndia, British Museum, Ross |
| ontobio:Travel | The act of journey or movement of people between geographical locations. | Travel01, Travel02, Travel03 |
| ontobio:Meal | Eating that takes place at a specific time. | Breakfast1, Lunch1, Dinner1 |
| schema:Place | Entities that have a somewhat fixed, physical extension. | India, England, Scotland, Netherlands |
| ontobio:Activity | A series of actions done by an agent. | Feeding, Reading, Bathing, Shaving |
| amv:AcademicDiscipline | A branch of knowledge. | Mathematics, Aerospace Engineering, Statistics |
| schema:Occupation | A profession that may involve prolonged training and/or a formal qualification. | Librarian, Historian, Journalist |
| wiki:Pet | An animal kept for companionship and a person’s enjoyment. | Dog, Cat |
| Type of property | Property name | Description | Domain | Range | Characteristics |
| Object Property | ontobio:hasFoodItem | Indicates the food item contained in a meal. | ontobio:Meal | ontobio:FoodItem | - |
| schema:birthPlace | The place where a person was born. | foaf:Person | schema:Place | Functional | |
| schema:containsPlace | The basic containment relation between a place and one that contains it. | schema:Place | schema:Place | Transitive | |
| relationship:friendOf | A person who shares mutual friendship with this person. | foaf:Person | foaf:Person | Symmetric | |
| Data Property | dcterms:date | A point or period of time associated with an event in the lifecycle of the resource. | amv:InformationResource | xsd:string | - |
| ontobio:hasEpithet | A descriptive term to qualify a person’s most important quality. | foaf:Person | xsd:string | - | |
| ontobio:timeOfBirth | Specifies the time when an individual was born. | foaf:Person | xsd:dateTime | Functional | |
| ontobio:marriageYear | The year when a person entered into a marriage or a marital union. | bio:Marriage | xsd:gYear | Functional |
S8. Ontology Development: For ontology development, we employed the W3C-recommended Web Ontology Language (OWL) language10 together with the Pellet reasoner to perform tasks such as consistency checking, classification, and realization. Modelling was carried out using Protégé (Musen and Protégé Team, 2015). The current version (1.0) of OntoBio comprises 227 classes, 215 object properties (OPs), and 65 data properties (DPs), along with a few illustrative individuals. The ontology’s Description Logic (DL) expressivity level is SROIQ(D) (Horrocks et al., 2006). OntoBio can be browsed and downloaded from https://w3id.org/ontobio in RDF/XML, N-Triples, JSON-LD, and TTL formats. Fig. 10 presents several of the key classes, OPs, and DPs represented within the OntoBio ontology.
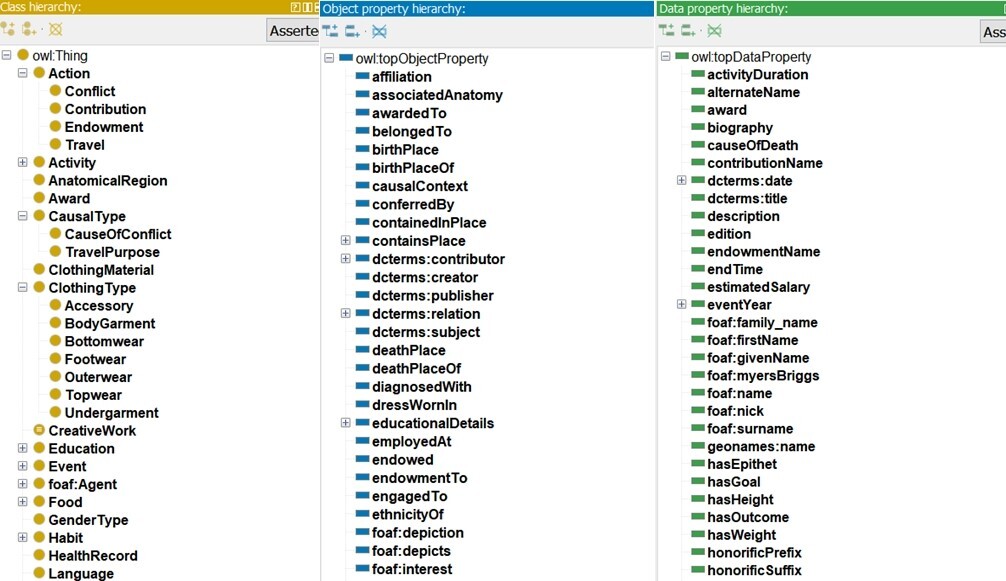 Fig. 10.
Fig. 10.
A snippet of OntoBio classes, object, and data properties from Protégé.
S9. Evaluation: The OntoBio ontology was evaluated using a multi-layered approach to ensure its semantic soundness, quality, expressivity, and structural integrity. This evaluation consisted of four key stages: (A) syntactic correctness, (B) structural and logical validation, (C) assessment of quantitative metrics, and (D) query-based evaluation. Each step utilized specialized tools, as outlined below.
(A) Syntactic correctness: The syntactic validity of OntoBio was assessed using the web-based Ontology Pitfall Scanner (OOPS!) (Poveda-Villalón et al., 2014), which categorizes ontology design issues into three levels: critical, important, and minor. The initial scan (refer Fig. 11) identified several issues, including the Missing domain and range specifications for properties, Missing annotations, and Incorrect use of equivalent properties and classes. Each of these issues was carefully analyzed and resolved through appropriate modifications to the ontology. A subsequent OOPS! scan (Fig. 12) confirmed that most issues had been addressed, with only a few minor ones remaining. Notably, these minor issues were identified as false positives. For example, OOPS! incorrectly suggested that the classes State and Country were equivalent. Likewise, the recommendation that influencedBy and worksWith are inverse properties (Fig. 13) was determined to be inaccurate and therefore disregarded.
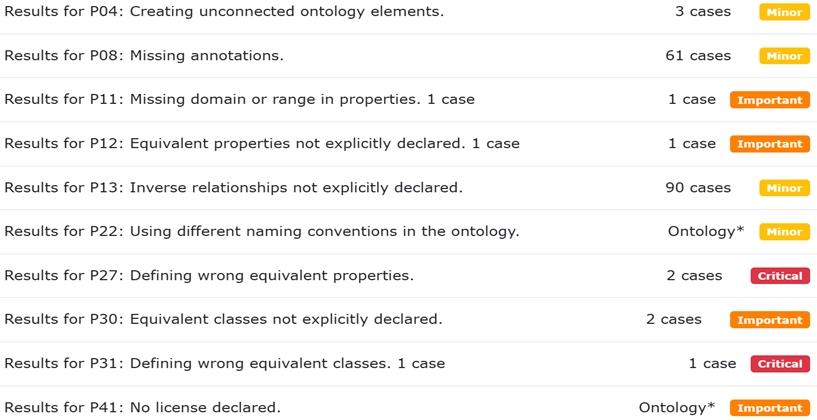
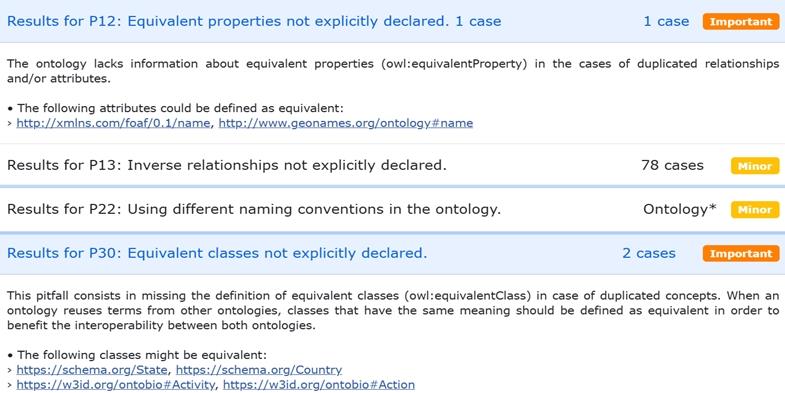 Fig. 12.
Fig. 12.
Test result after the rectification of OntoBio based on OOPS! recommendations.
 Fig. 13.
Fig. 13.
A snippet of OOPS! recommendation.
(B) Structural and logical validation: Structural and logical validation was conducted using the OntoDebug plugin and the Pellet reasoner within Protégé. OntoDebug facilitated the identification of structural inconsistencies and validated the conceptual soundness of the ontology (see Fig. 14).
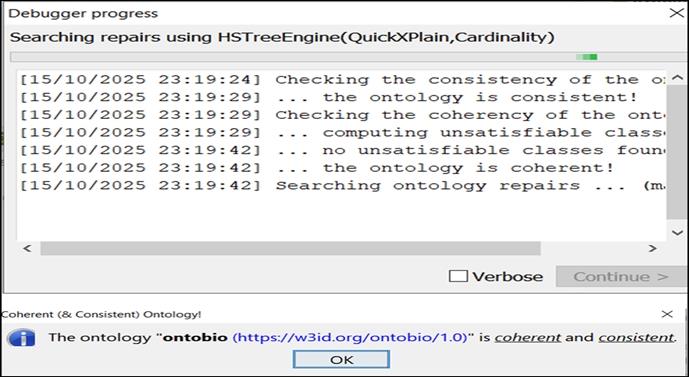 Fig. 14.
Fig. 14.
Structural integrity and debugging with OntoDebug.
Additionally, Pellet, a Web Ontology Language Description Logic (OWL-DL) reasoner, was employed to verify logical consistency. The absence of errors during reasoning confirmed the ontology’s inferencing capability and logical integrity.
(C) Quantitative metrics: To assess the ontology’s richness and expressivity, we employed the OntoMetrics11, which analyzes an ontology’s internal structure across several dimensions: Schema, Instances, Graphs, and Individual Axioms. While a comparative evaluation with similar person-centric biographical ontologies was not feasible (see Section 2), we present internal quantitative metrics to highlight OntoBio’s complexity and depth. Key observations (Fig. 15) include: High Attribute Richness (AR) — reflects a substantial number of attributes per class, indicating expressive modelling; and Graph Metrics, provided comprehensive structural measures, such as depth, breadth, density, and centrality, offering insights into the ontology’s overall topology.
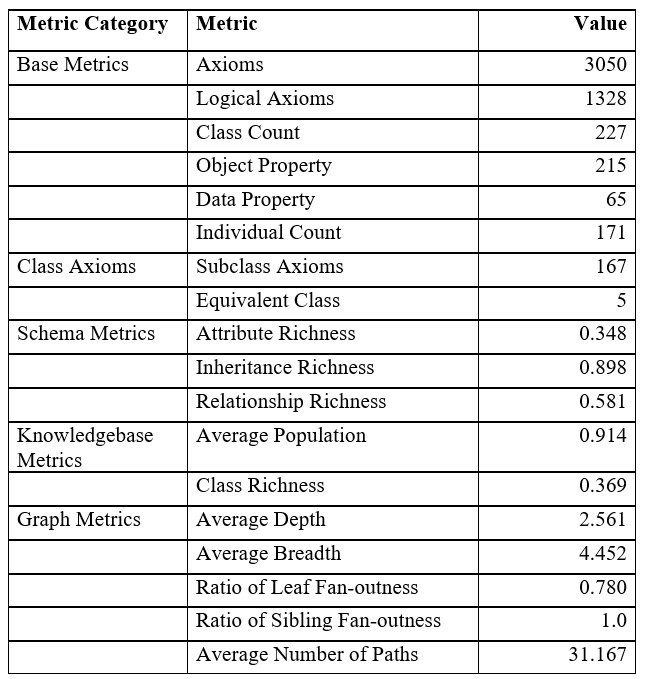 Fig. 15.
Fig. 15.
Quantitative Metrics generated for OntoBio12.
(D) Query-based Evaluation: To evaluate semantic coverage and alignment with design objectives, we conducted a query-based assessment using SPARQL Protocol and Resource Description Framework (RDF) Query Language(SPARQL), as guided by competency questions (CQs) defined in Step 2 of the Ontology Development Methodology (ODM). SPARQL—recommended by W3C for querying graph-based data (DuCharme, 2013)—was used to retrieve meaningful biographical information from OntoBio.
The ontology was populated with detailed biographical data on S. R. Ranganathan from various sources, forming a semantically enriched knowledge graph. Figs. 16,17 present two sample SPARQL queries (CQ1 and CQ5) and their corresponding outputs. Fig. 16 shows travel history, including a 1924 journey from Washermanpet to London aboard the SS Mariana. Fig. 17 displays awards conferred upon Ranganathan, such as the honorary title Rao Sahib in 1935 by the Government of India (Yogeshwar, 2001). All queries were executed on the Apache Jena Fuseki12 platform, and successfully retrieved the expected results.
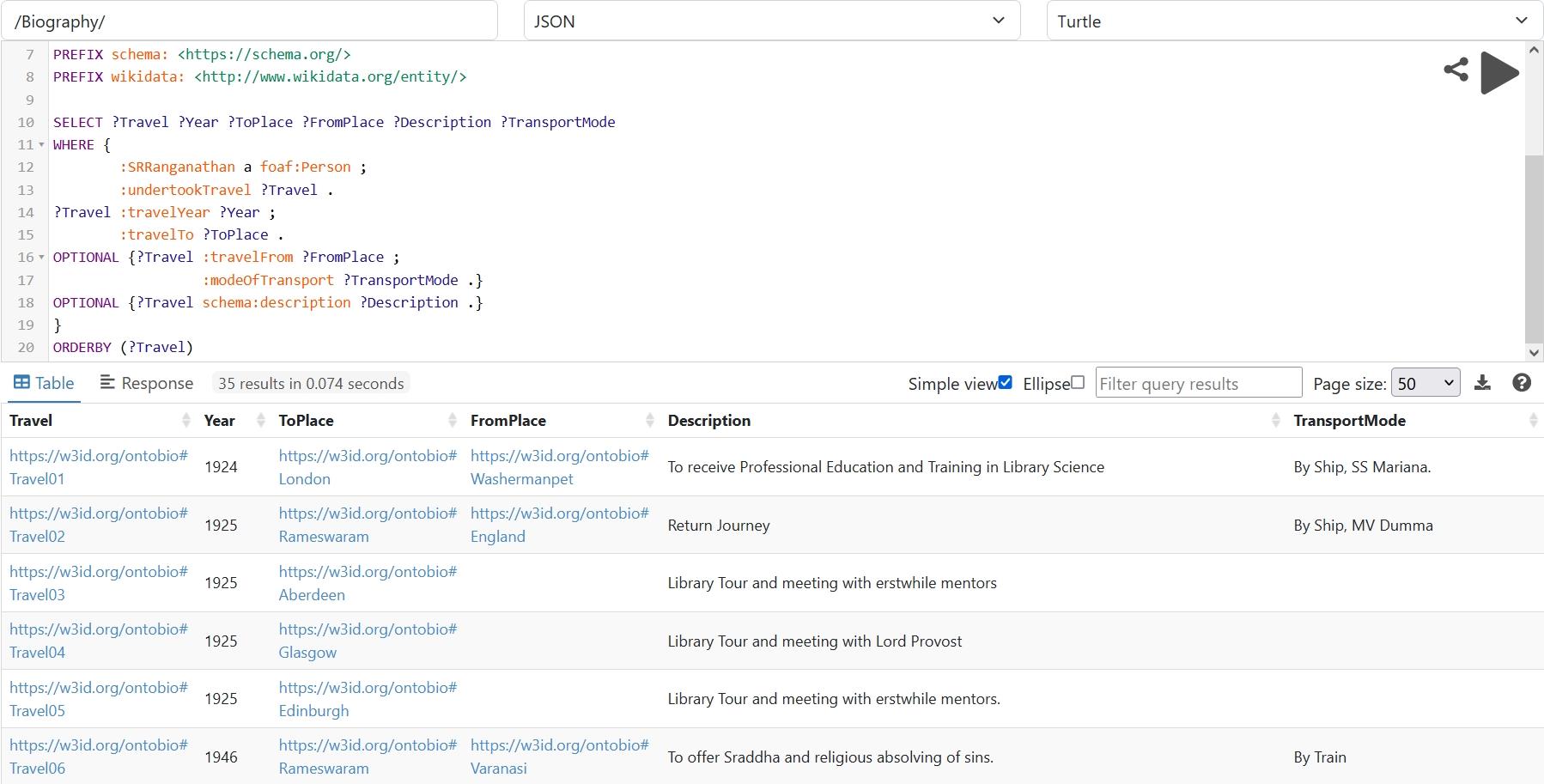 Fig. 16.
Fig. 16.
A SPARQL query to retrieve the Travel details of Ranganathan. SPARQL, SPARQL Protocol and Resource Description Framework (RDF) Query Language.
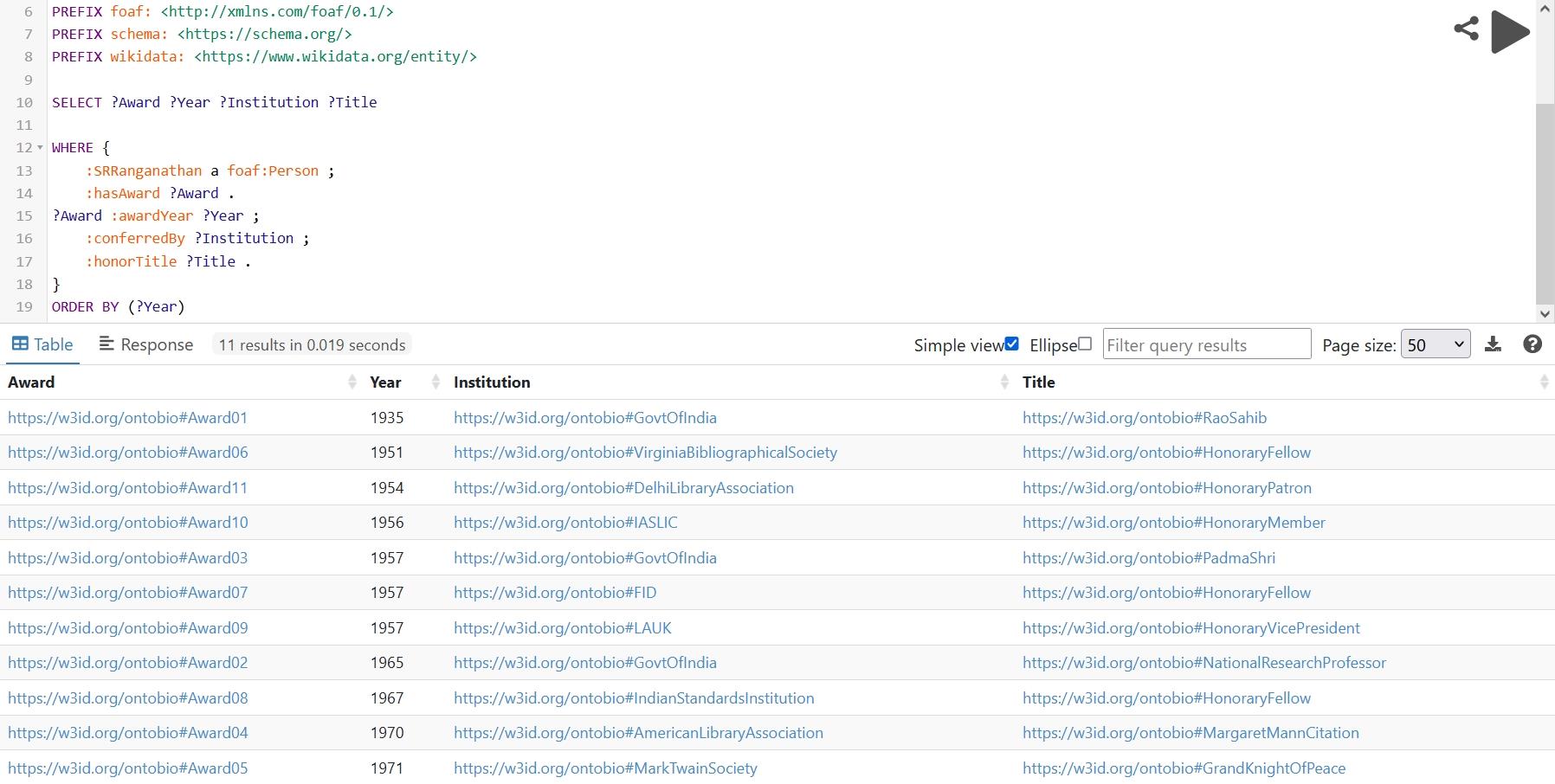 Fig. 17.
Fig. 17.
A SPARQL query to retrieve the Award details of Ranganathan.
Ontologies are often described as the “foundation layers for knowledge graphs” (Al-Aswadi et al., 2022) as they enable semantic search, data analytics, knowledge inference, and the capacity to address complex user queries. In Section 3, we introduced several biographical scenarios (Sc.) that motivated the development of OntoBio. In this section, we examine OntoBio’s expressivity—specifically, how it allows us to capture and represent the diverse forms of biographical knowledge present across various resources.
Sc. 2 discussed an aspect of S. R. Ranganathan’s travels can be formally represented within OntoBio, as shown in Fig. 18.
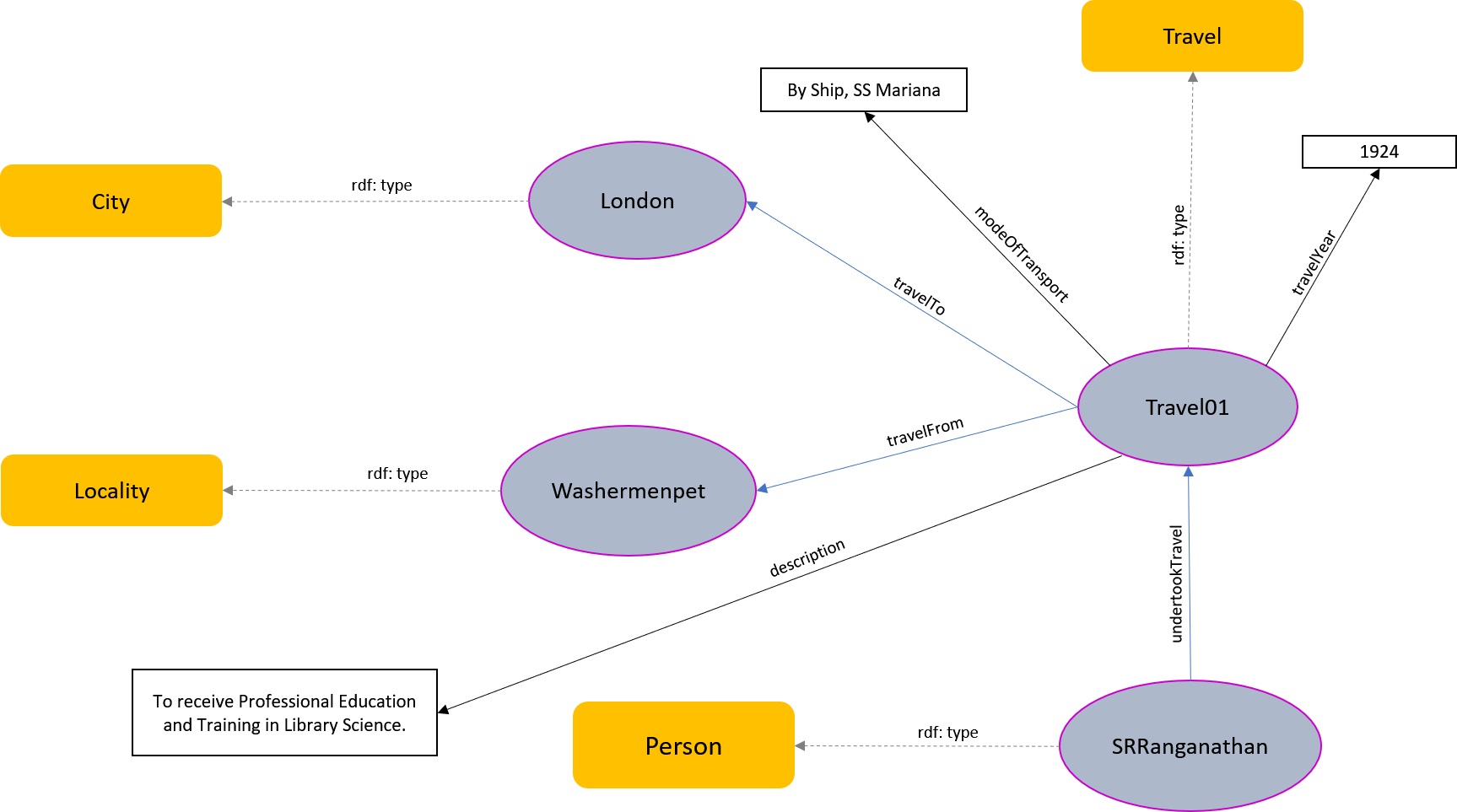 Fig. 18.
Fig. 18.
A Snippet from OntoBio showing the travel details. Note that only the immediate superclasses are displayed for clarity. For example, the classes schema:City and OntoBio:Locality have the superclass schema:Place in the actual ontology (accessible at https://w3id.org/ontobio).
The discrete units of biographical information represented within the graph schema include the person (“S. R. Ranganathan”), places (“Washermenpet” and “London”), the year of travel (“1924”), and the mode of transport (“by ship, SS Mariana”). These elements are interconnected at both class and instance levels through various associative properties, as illustrated in Fig. 18. In this representation, the instance “Travel01” is created under the “Travel” class. The two locations, Washermenpet and London, are instantiated under the “Place” class (with their respective subclasses shown in Fig. 18) and are linked to the Travel01 entity via the object properties (OPs) “travelFrom” and “travelTo”. The details of transportation (British ship, SS Mariana) are associated with Travel01 through the data property (DP) “modeOfTransport”. The travel purpose (“to receive professional education and training in Library Science”) is linked to “Travel01” via the DP “description”, while the year of travel (“1924”) is associated through the DP “travelYear”. Finally, the Travel01 entity is linked to the entity “SRRanganathan”, which is an instantiation of the “Person” class in the ontology.
Sc. 3 discussed S. R. Ranaganathan’s health records, which can be represented through OntoBio ontology as shown in Fig. 19.
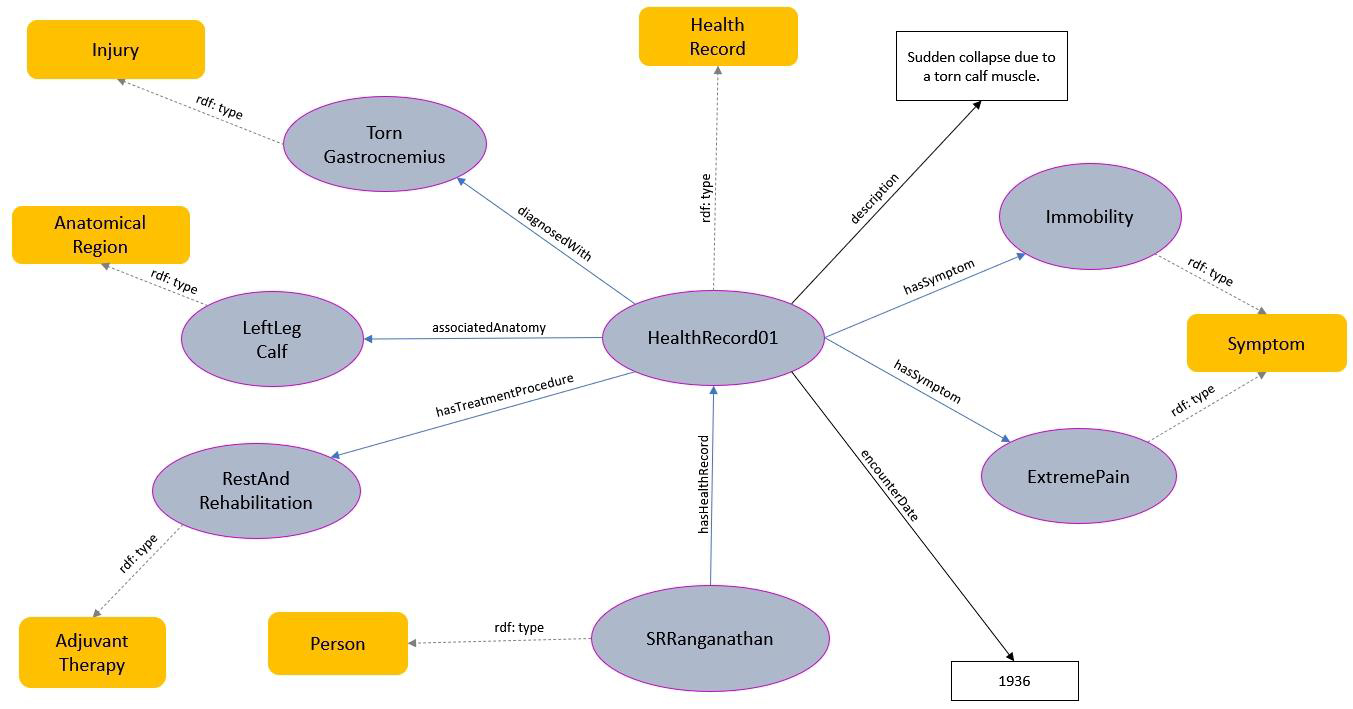 Fig. 19.
Fig. 19.
A Snippet from OntoBio showing health-related information. As with the previous example, only the immediate super-classes are shown for clarity.
The incident described in Sc. 3 forms an instance (say “HealthRecord01”) of the class “Health Record”. Two observed symptoms, “ExtremePain” and “Immobility”, are instantiated under the “Symptom” class and linked to “HealthRecord01” through the OP “hasSymptom”. The treatment procedure “RestAndRehabilitation” is an individual under the class “AdjuvantTherapy”, a subclass of “Treatment Procedure” (not shown here), and is connected to “HealthRecord01” via the OP “hasTreatmentProcedure”. The affected anatomy, “LeftLegCalf”, is an instance of the “AssociatedAnatomy” class and is linked to “HealthRecord01” through the OP “associatedAnatomy”. The diagnosis, formally named “Torn Gastrocnemius”, is an instance of the “Injury” class and is connected through the OP “diagnosedWith”, as shown above. Similarly, the date of the injury, “1936”, is linked to the instance “HealthRecord01” through the DP “encounterDate”. The entire record includes a “description” DP associated with the “HealthRecord01” entity, as illustrated in the figure. Lastly, “HealthRecord01” is connected to the entity “SRRanganathan”, an instance of the “Person” class, through the OP “hasHealthRecord”.
Sc. 4 discussed Ranganthan’s daily routine, which can be captured through OntoBio as shown in Fig. 20.
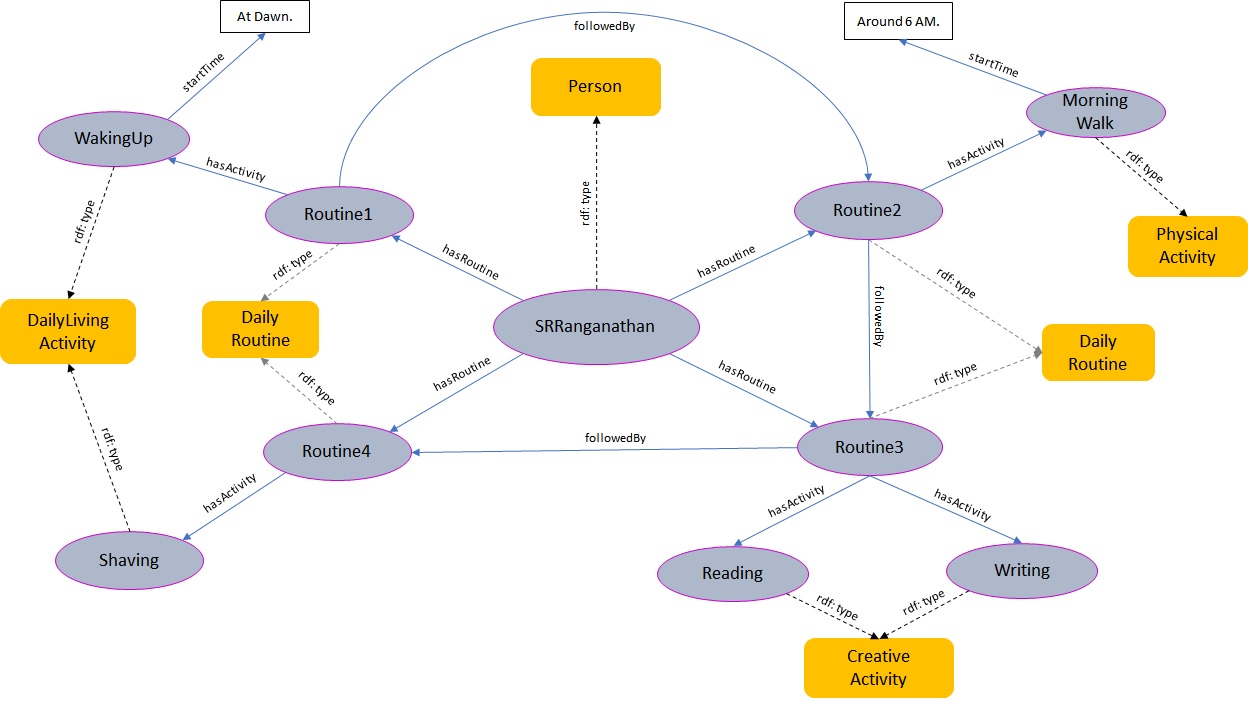 Fig. 20.
Fig. 20.
A snippet from Ontobio showing the representation of daily activities. To enhance clarity and minimize visual clutter, only the immediate superclasses are displayed. Moreover, of the eleven activities mentioned above, only five are shown here. The complete representation can be viewed by accessing the ontology file at https://w3id.org/ontobio.
In the passage from Sc. 4, the various activities that constitute S. R. Ranganathan’s daily routine are “WakingUp”, “MorningWalk”, “Shopping”, “Writing”, “Reading”, “Shaving”, “Bathing”, “Puja”, “Feeding”, “Playing”, and “WorkingOnJob”. These are instantiated under the respective subclasses of the “Activity” class (the reader is referred to Step 5 of Section 4.2 and Fig. 5 for its hierarchy) and are linked to “Routine1”, “Routine2”, “Routine3”, and so on through the OP “hasActivity”. These instances, in turn, form an instantiation of the “DailyRoutine” class, a subclass of the “Habit” class. The instance of the “Person” class, “SRRanganathan”, is linked to the “DailyRoutine” class through the OP “hasRoutine”. Furthermore, the sequence of activities is maintained through the OPs “followedBy” and “precededBy” (i.e., “Routine1” is “followedBy” “Routine2”, and so forth). Additional DPs such as “startTime”, “activityDuration”, and “description” further enrich OntoBio’s representational scope.
As previously noted, OntoBio supports the representation of personality traits. This is illustrated in the following example. Biographical sources (Yogeshwar, 2001; Palmer, 1976) describe Ranganathan as a “tireless worker” or “workaholic”, maintaining an intensive work schedule of approximately 12–16 hours per day. While this often led to conflicts with his contemporaries, it also contributed significantly to his major achievements. In the OntoBio ontology, this information is represented as shown in Fig. 21. The personality trait “Workaholic” is linked to the individual through the properties traitObservedBy and traitManifestedIn. Specifically, Ranganathan is modeled as having the personality trait (hasPersonalityTrait) “Workaholic,” which is reflected in his daily activities (see Scenario 4 for a detailed account of his routine). This trait is observed and documented by two individuals—his son, Yogeshwar Ranganathan, and his contemporary and friend, Bernard Palmer, a noted information scientist. Their respective relationships to the central figure, “SRRanganathan”, are modeled using appropriate relational properties within the ontology, as illustrated in Fig. 21.
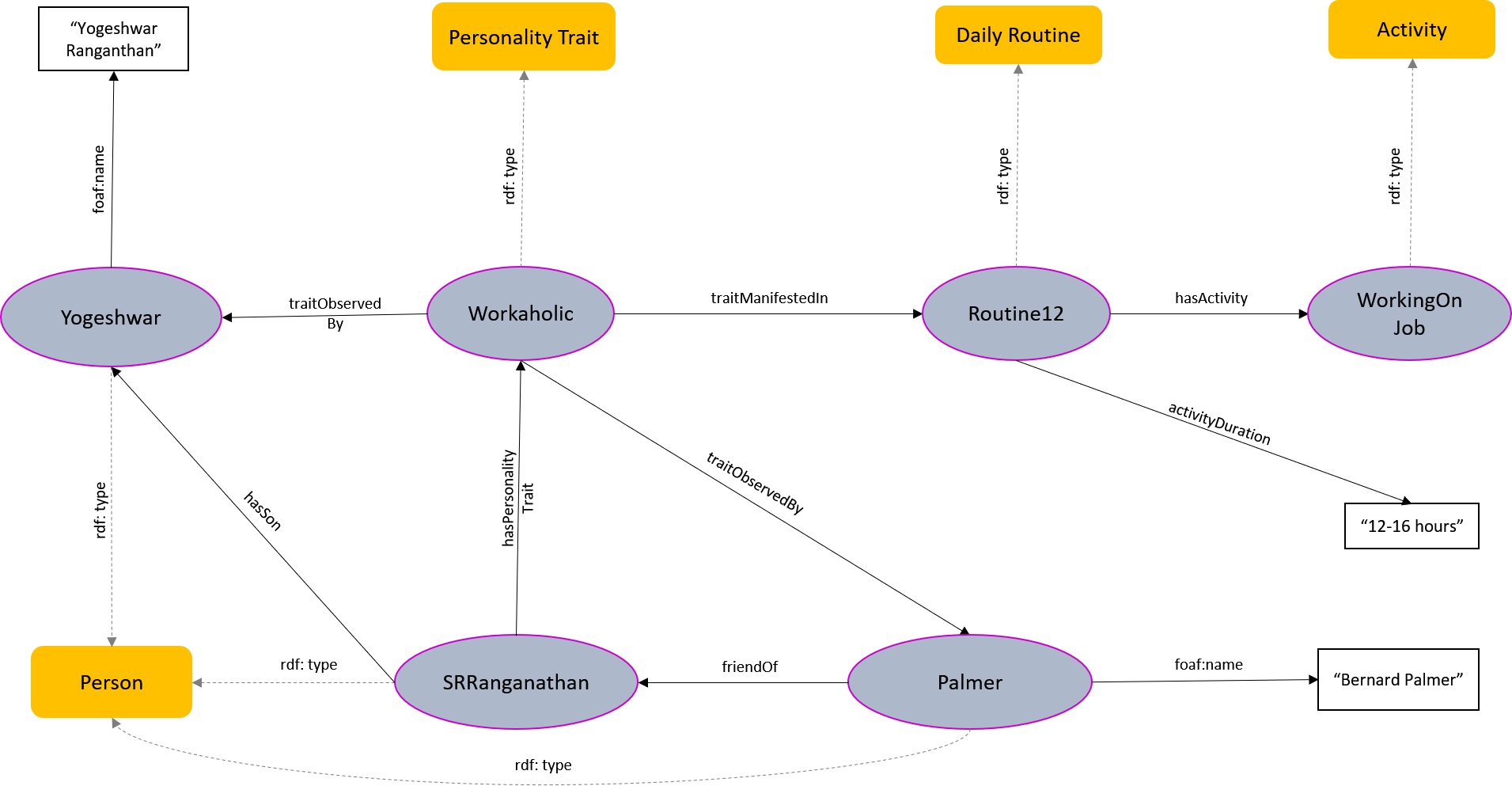 Fig. 21.
Fig. 21.
Representation of Personality traits of S. R. Ranganathan through OntoBio. A full representation can be viewed by accessing the ontology available from https://w3id.org/ontobio.
In addition to the scenarios presented in Section 3, we integrated numerous other biographical data related to Ranganathan’s life and works, demonstrating the capabilities of the OntoBio ontology. A sample knowledge graph of Ranganathan’s life is available at https://w3id.org/ontobio. A conceptual representation of the Ranganathan Knowledge Graph (RKG) realized using the OntoBio ontology is shown in Fig. 22.
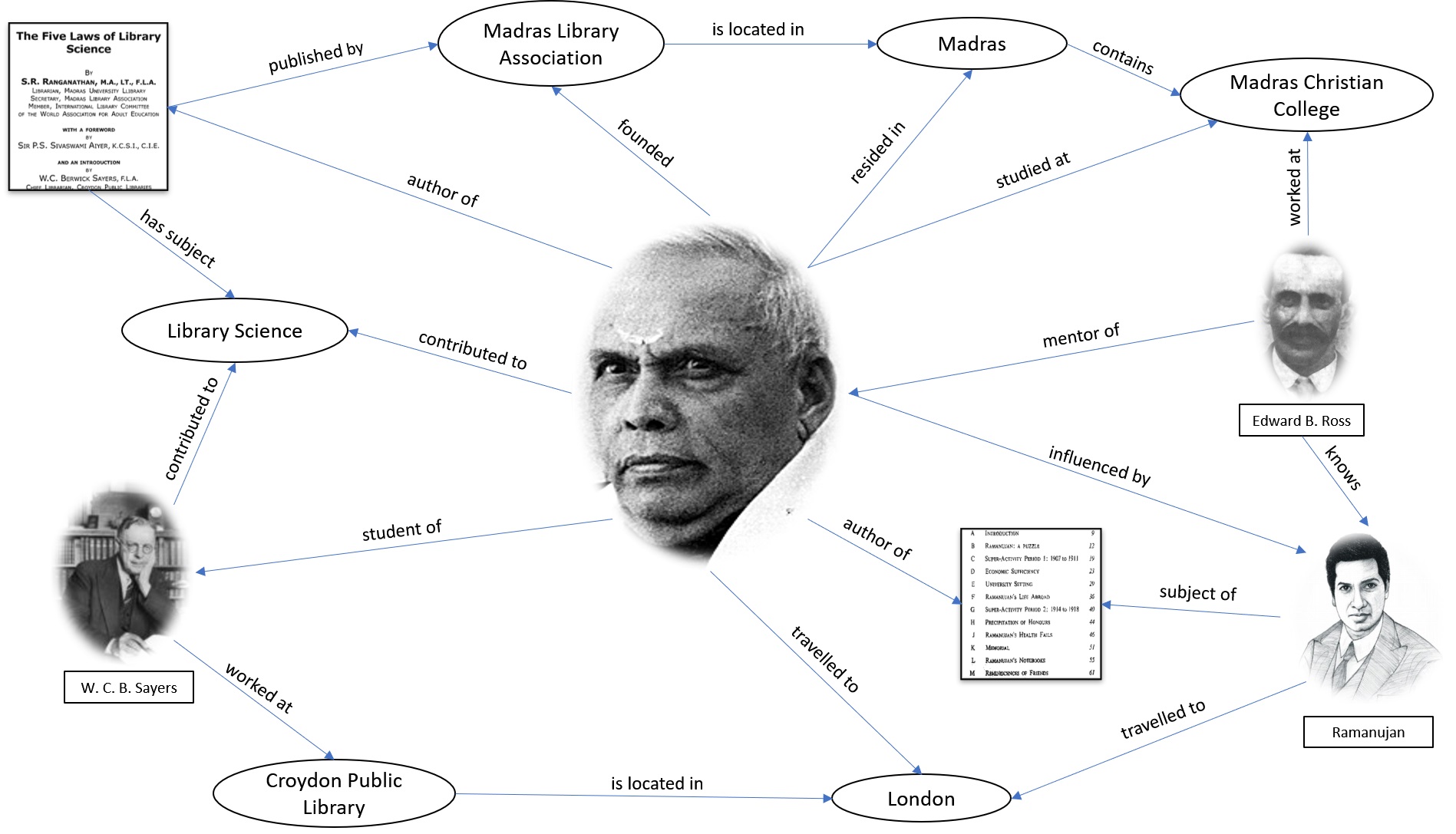 Fig. 22.
Fig. 22.
A visual representation of RKG with the central node representing S. R. Ranganathan.
It is important to recognize that conflicting information may arise across different biographical sources—for instance, discrepancies in the date or location of a specific event in a person’s life. OntoBio addresses this challenge by employing the annotation property “dcterms:source”, which allows for the documentation and traceability of multiple sources associated with such conflicting data. Moreover, since OntoBio is designed to support the construction of personal knowledge graphs, from curated biographical records to potentially lifelong data of living individuals—issues of privacy, security, and copyright become especially relevant. To address these concerns, OntoBio incorporates a set of annotation properties aimed at managing rights, privacy, and data sensitivity. These include:
| dcterms:rights, dcterms:accessRights, dcterms:license, dcterms:rightsHolder, :requiresComplianceWith, :accessLevel, :accessCondition, dcterms:audience, :sensitivityLevel, :intendedUse |
The properties prefixed with “dcterms” are reused from the Dublin Core Metadata Vocabulary13, while the unprefixed properties are defined within the OntoBio ontology itself. Together, these properties embed data governance considerations directly into the ontology, supporting the responsible and compliant development of personal knowledge graphs.
Biographies present a unique challenge for knowledge representation due to the complexity of the domain and the nature of the available data. It is evident from the biographical genre that no “object description” can ever be truly exhaustive, as the ultimate goal is to reconstruct a human life and situate it within its historical and cultural context (Hjørland, 2023; Possing, 2015). To address this challenge, we focused solely on verifiable “facts” and designed an ontology capable of capturing their diversity. Our aim is not to interpret or explain the biographee, but rather to provide a comprehensive, 360° view of the individual through a graph-based schema that facilitates exploration of their life and achievements.
We develop a framework to contextualize the categories of biographical data. To the best of our knowledge, this work represents a significant advancement in leveraging biographical knowledge for machine processing. As a test case, a biographical knowledge graph centered on the life and works of S. R. Ranganathan was constructed using OntoBio, and some sample data are discussed in this paper.
Our initial aim was to represent biographical information about eminent academicians, intellectuals, scientists, and other creative thinkers within a semantic framework. We focused on the academic and research community due to our professional background, especially that of the first author, a faculty member and researcher in the Library and Information Science (LIS) domain. This perspective also informed the selection of Prof. S. R. Ranganathan as a case study for evaluating the OntoBio ontology. OntoBio’s top-level categories: Personality, Environment and Milieu, and Achievements/Milestones, along with their subdivisions, are abstract enough to accommodate data on other prominent academicians across different regions. While its broader applicability is still being explored, preliminary efforts are already underway. However, the ontology may currently under-represent figures from other fields, such as athletes, political leaders, or war heroes.
A major aspect in the development of our study is the link to upper-level ontologies such as DOLCE (Borgo et al., 2022) where the commonalities to our approach are visible. Our identification of the core aspects of biographical literature (Personality, Environment & Milieu, Achievements/Milestones) bears similarity to their categories of Accomplishment, Role, Social Agent, Physical Object, Non-Physical Object, etc. We envisage the ramifications of such a model to be immense, from integrating heterogeneous data sources to an entirely new framework for representing and understanding biographical knowledge about eminent personages and their associated personal events.
All data reported in this paper is available from https://w3id.org/ontobio.
BD: conceptualized and designed the research study, performed the research, wrote and reviewed the manuscript, supervised the study. SA: performed the research, collected the data, analyzed the data, wrote and reviewed the manuscript. Both authors contributed to editorial changes in the manuscript. Both authors read and approved the final manuscript. Both authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
Not applicable.
This work is executed under the research project entitled “Facility for transforming library data to linked library data, 02/93/2022-23/RP/MJ/OBC”, funded by the Indian Council of Social Science Research (ICSSR), Govt. of India, New Delhi.
The authors declare no conflict of interest.
During the preparation of this work the authors used ChatGPT-5 mini in order to check spelling and grammar. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
2 https://bioportal.bioontology.org/ontologies/FOAF
5 http://purl.org/ontology/bibo
6 http://purl.org/vocab/relationship
10 https://www.w3.org/TR/owl2-primer/
11 https://ontometrics.informatik.uni-rostock.de/ontologymetrics/
13 https://www.dublincore.org/specifications/dublin-core/dcmi-terms/
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.