




 , Pengxuan Zhang 1, Haiqun Ma 1,*
, Pengxuan Zhang 1, Haiqun Ma 1,*
1 College of Information Management, Heilongjiang University, 150080 Harbin, Heilongjiang, China
Abstract
Artificial intelligence (AI) is profoundly reshaping production modes, lifestyles, and organizational paradigms. Enhancing individual adaptability and creativity in this intelligent era has emerged as an imperative research agenda within public literacy studies. This study investigates the evolution of themes in AI literacy research, with a focus on the evolutionary mechanisms through which the domain’s knowledge architecture transitions from techno-cognitive accumulation to synergistic innovation ecosystems. Employing text-mining methodology, we analyze academic literature spanning 2015–2024. Following standard processing steps—tokenization, stopword removal, and lemmatization—we apply Latent Dirichlet Allocation (LDA) topic modeling to extract and analyze latent topics, tracing paradigm shifts in knowledge production during socio-technical processes of innovation. Evolutionary pathways constructed through topic similarity metrics reveal a progression in AI literacy research from knowledge enlightenment to symbiotic knowledge development. LDA2vec hybrid modeling facilitates deep semantic exploration of stage-specific topics, while subsequent topic intensity evolution and semantic network analyses highlight breakthrough points in AI literacy-driven knowledge innovation. This dual-axis analytical framework—integrating topic evolution with intensity dynamics—provides empirical evidence for predicting disciplinary trajectories while establishing novel theoretical paradigms and methodological approaches to AI literacy. Aligned with knowledge organization principles, these frameworks emphasize systematic structuring, cross-domain classification, and semantic interrelations of AI literacy concepts to enhance knowledge accessibility and interoperability.
Keywords
- AI literacy
- topic evolution
- LDA2vec
- text mining
- knowledge innovation
The emergence and rapid proliferation of artificial intelligence (AI) Literacy stem from dual transformations in knowledge production paradigms during socio-technological institutionalization processes. Technologically, paradigm-shifting breakthroughs in Generative Artificial Intelligence are redrawing the epistemic boundaries of human cognition. Large Language Models (LLMs) exemplified by ChatGPT (specifically GPT-3.5, GPT-4, and GPT-4o, with GPT-4o representing the latest multi-modal iteration as of 2024) through their quasi-human dialogic capabilities and cross-domain knowledge synthesis advantages, are rapidly permeating core societal sectors such as education and healthcare (UNESCO, 2023). These versions exhibit progressive enhancements: GPT-3.5 (2022) introduced foundational conversational abilities: GPT-4 (2023) improved reasoning and contextual understanding: GPT-4o (2024) integrated vision and audio processing, expanding its application in multi-modal literacy scenarios. Comparatively, other LLMs like Google Bard (2023) and Anthropic Claude (2023) demonstrate similar trajectory shifts but with distinct strengths—Bard in real-time data integration, Claude in transparency of reasoning chains—though ChatGPT remains the most referenced in academic literature, justifying its central role here. However, this technological leap forward harbors profound epistemological crises beneath its surface: while AI-generated content exhibits superficial coherence, it fundamentally lacks genuine intentionality and agency, remaining essentially statistical probability-driven semantic collocations (Billingsley et al, 2025). Initially conceptualized as technical comprehension and applicative competencies, AI Literacy has undergone substantive reconceptualization alongside AI’s pervasive societal permeation (Chalmers, 2023). Contemporary scholarship now delineates it as a multidimensional cognitive framework encompassing epistemic critique, ethical discernment, and transdisciplinary synthesis, transcending its original technocentric paradigm (Long and Magerko, 2020).
Contemporary AI Literacy has transcended mere technical proficiency, manifesting as a symbiotic co-evolution with knowledge innovation within socio-technical ecosystems (Laupichler et al, 2022). Through technological enablers, it fundamentally reconfigures the efficiency frontiers and epistemic boundaries of knowledge production, while escalating innovation complexity reciprocally necessitates advancements in AI ethics governance and algorithmic accountability (OECD, 2024). Embodied cognition theory now exposes AI’s ontological constraints: systems lacking corporeal boundaries and historical situatedness remain incapable of developing authentic self-awareness or moral agency (Chalmers, 2023). This limitation manifests acutely in clinical diagnostics, where AI’s structured data processing fails to replicate physicians’ intuitive heuristics and systematic analytical framework embodied expertise (Billingsley et al, 2025). Contemporary AI literacy frameworks necessitate not merely the synergistic coupling of ‘instrumental revolution’ and ‘cognitive revolution’, but more crucially, the institutionalization of a triaxial competency matrix—rooted in knowledge organization principles—that systematically structures and classifies competencies to address challenges including algorithmic bias and digital inequity: (1) Techno-procedural fluency: (2) Domain-embedded expertise: (3) Ethico-critical deliberation. This matrix embodies knowledge organization’s core goals: organizing discrete literacy elements into an interconnected system for enhanced accessibility and application (Wang et al, 2023). The mutually constitutive dynamics between knowledge innovation and AI literacy engender a recursive epistemic ecosystem, wherein knowledge innovation provides teleological momentum and vector specification for artificial intelligence development through problem-driven exigencies, while AI literacy reciprocally supplies methodological infrastructure and epistemic prostheses for innovative breakthroughs. In future advancements, the deep integration of these dual trajectories will propel technological progress and societal transformation. This study positions the topic evolution of AI Literacy literature as its central inquiry, aiming to elucidate how its knowledge architecture transitions from primitive accumulation of technical cognition to a self-evolutionary synergistic innovation network.
Over the past decade, research on AI Literacy has evolved from initial explorations to deepened development. In 2015, the European Union (EU) released the Digital Competence Framework 2.0, This milestone marked the first-time inclusion of “understanding algorithmic logic” into citizen digital literacy standards, signifying that AI Literacy has entered the realm of policy considerations (Vuorikari et al, 2016). In 2016, Stanford University released the Artificial Intelligence Index Report, establishing the world’s first AI literacy assessment framework (Stone et al, 2016). The formal conceptualization of AI Literacy was articulated in 2018 by the University of Southern California’s educational technology team in a paper published in the Journal of Educational Technology Research, which systematically defined four core dimensions: technical understanding (algorithmic logic, data processing), critical evaluation (bias identification, ethical judgment), practical application (tool operation, problem-solving), and social engagement (policy discourse, risk communication) (Perchik et al, 2023). In 2019, Keller and John (2019) validated the framework’s efficacy through a study involving 5000 adult learners, integrating computational thinking with sociological theory to design the AI Literacy Questionnaire (AIL-Q) for non-technical populations. In 2020, Long and Magerko (2020) advocated the “Black Box Transparency” pedagogical strategy, delineating 18 sub-competencies of AI literacy and proposing a “Competency-Context” alignment matrix. In 2023, United Nations Educational, Scientific and Cultural Organization (UNESCO) published the policy brief Generative AI and the Crisis of Digital Literacy: A Global Delphi Study (UNESCO, 2023), analyzing challenges posed by generative AI (e.g., ChatGPT) to global digital literacy and recommending educational countermeasures. In 2024, the Organization for Economic Co-operation and Development (OECD) Centre for Educational Research and Innovation, based on survey data from 15,200 K-12 teachers across 28 countries (including OECD members and partner nations), utilized the OECD Teacher AI Literacy Framework to evaluate teacher competencies across three domains: technological cognition, ethical evaluation, and pedagogical integration (OECD, 2024).
In the Student AI Competency Framework released by UNESCO in 2024, AI literacy is explicitly defined as an integration of knowledge, skills, and values, with particular emphasis on “human-centered AI awareness” and “societal responsibility” (Cukurova and Miao, 2024). UNESCO’s Teacher AI Competency Framework (2023) establishes a three-tiered competency progression—“Acquisition, Deepening, Creation”—spanning five domains (e.g., AI ethics, pedagogical integration, professional development) and further delineated into 18 specific indicators (Cukurova and Miao, 2024). Concurrently, the European Union introduced the AI-Digital Competence Reference Framework for Educators, emphasizing three literacy pillars: functional, critical, and socio-cultural competencies (Ferrari, 2012). In K-12 education, the United States launched the national “AI4K12” initiative, establishing grade-level standards across seven knowledge domains, including machine learning and natural language processing (Casal-Otero et al, 2023). In higher education innovation, MIT’s “AI+X” interdisciplinary curriculum, introduced in 2024, deeply integrates AI literacy with specialized fields such as medicine and law (Biswas et al, 2025).
The study of AI Literacy originated in the 1970s. In 1972, scholar Agre first proposed the concept from a practitioner’s perspective, but due to technological limitations, it was subsumed under the broader framework of information literacy for decades. By 2015, Konishi redefined AI Literacy as “the cognitive capacity to navigate future technological developments” in an online article, marking its emergence as an independent research domain. In 2016, Burgsteiner et al (2016) further emphasized its necessity as a competency for understanding AI applications (Hinojo-Lucena et al, 2019). Long and Magerko (2020) advanced a four-dimensional framework: technical comprehension, critical evaluation, human-AI interaction, and ethical disposition.
The explosive growth of generative AI post-2020 catalyzed multidimensional expansions in defining AI literacy, alongside breakthroughs in topic differentiation and semantic correlation analysis. On one hand, global institutions like UNESCO and OECD established ethical frameworks and teacher competency standards, prioritizing critical issues such as “data sovereignty” and “algorithmic transparency” (UNESCO, 2023; OECD, 2024). On the other hand, methodologies shifted from traditional content analysis to dynamic topic modeling, leveraging semantic networks to trace latent associations (e.g., “algorithmic bias–ethical risk”) and reveal cross-phase evolutionary pathways. Current research focuses on three directions: (1) Topic Dynamics: Rastogi et al (2023) employed time-decay functions to quantify fluctuations in topic intensity, revealing sustained growth in topics like “human-AI collaboration”. (2) Cross-Domain Synergy: Mahdikhani and Meena (2024) validated bidirectional interactions between “medical AI literacy” and “educational ethics” through text mining. (3) Assessment Innovation: Wang et al (2023) developed a tripartite “Technical-Ethical-Applied” scale, overcoming static limitations in traditional competency evaluations. Future trends point toward neuro-symbolic AI-driven topic integration and the standardization of universal literacy frameworks.
It is noteworthy that the techno-socialization of topic evolution has become increasingly prominent: in the education sector, the focus has shifted from “tool application” to “reconstruction of cognitive infrastructure”, while in healthcare, the paradigm has elevated from “data-driven diagnosis” to “clinician-patient cognitive synergy”. Additionally, research methodologies exhibit a “techno-social dual helix” progression: early reliance on manual coding resulted in coarse topic granularity, whereas contemporary deep learning models, by capturing concept drift phenomena, reveal asynchronous contradictions between literacy demands and technological development. These findings provide policymakers with empirical foundations for managing “technology-response cycles” and establish a foundation for educators to design dynamic curricula.
In summary, while traditional topic extraction methods can effectively identify high-confidence topics and reveal domain-specific research trends, their reliance on manual classification and intervention exhibits significant limitations. Traditional approaches characterized by human annotation and rule-driven mechanisms, despite their stable performance in topic categorization accuracy, face dual challenges of inefficiency and subjective bias infiltration. Notably, breakthroughs in text mining and deep learning technologies are reshaping the paradigm of topic analysis. Unsupervised learning methods, exemplified by the Latent Dirichlet Allocation (LDA) model, have pioneered machine-autonomous identification of semantic patterns by uncovering latent topic structures in document corpora through probability distributions (Griffiths and Steyvers, 2004). However, the LDA model’s inability to incorporate word vector embeddings hinders its capacity to capture dynamic semantic associations between terms, such as the implicit contextual linkage between “algorithmic bias” and “ethical risk”, which may be overlooked.
To address these limitations, improved methods integrating deep semantic representations have emerged. The Word2vec model constructs word vector spaces, mapping terms such as “AI Literacy” and “generative AI” into high-dimensional vectors, significantly enhancing sensitivity to synonym recognition and metaphorical expression detection (Mikolov et al, 2013). This semantic enhancement strategy based on distributed representations enables similarity computations to transcend the constraints of traditional cosine similarity measures.
This study employs text mining methodologies to deeply investigate the evolutionary patterns of AI Literacy research topics. Utilizing specialized text analysis tools and techniques, we process textual data (titles, abstracts, and keywords) from academic literature. Through tokenization, stopword removal, and lemmatization, raw text is transformed into structured formats suitable for computational analysis. The LDA topic model is applied to analyze the distribution of topics across the literature corpus. By calculating topic similarity metrics, we construct topic evolution pathways to visually map the progression of research foci. The study divides academic literature from 2015 to 2024 into six chronological stages, employing the LDA2vec method—a hybrid topic evolution detection approach—to perform deep topic mining on literature collections within each stage. The analytical framework integrates two core dimensions: topic content evolution and topic intensity evolution. This research specifically addresses the following questions:
RQ1: What are the evolutionary patterns of research topics in the field of Artificial Intelligence Literacy?
RQ2: How does Artificial Intelligence Literacy drive knowledge innovation?
RQ3: What future development trends will emerge in Artificial Intelligence Literacy research?
To systematically reveal the evolutionary trajectory of research in the field of AI Literacy, this study employs the LDA2vec model, a method for identifying topic evolution pathways in literature (Rastogi et al, 2023). This model integrates the semantic representation strengths of both LDA and Word2vec, demonstrating unique analytical value in topic exploration (Blei et al, 2003; Mikolov et al, 2013). While the LDA model can extract latent topics from texts, it struggles to capture semantic associations: conversely, the Word2vec model, through training on large-scale textual data, encodes vocabulary from massive corpora into low-dimensional semantic vectors, precisely capturing complex semantic relationships between terms (Wallach et al, 2009). By synergizing these strengths, the LDA2vec model not only achieves precise topic extraction but also constructs semantic association networks between entities, providing robust support for uncovering research topics and mapping the holistic evolutionary pathways of scholarly literature in AI Literacy (Chang et al, 2009).
The application of the LDA2vec model to identify topic evolution pathways involves the following steps: First, preprocess literature data related to AI Literacy collected from Web of Science and Scopus, including cleaning, tokenization, stopword removal, and lemmatization, to transform texts into formats suitable for model processing (Romero and Ventura, 2020). Next, train the LDA model using preprocessed data, determine the optimal number of topics through perplexity evaluation, and perform topic clustering to extract keywords for each topic (Blei et al, 2003). Then, utilize the Word2vec model to train the topic-specific keywords extracted by the LDA model, generating vector representations for each keyword (Mikolov et al, 2013). Subsequently, multiply the probability distribution of keywords in the LDA model by their corresponding Word2vec vectors and aggregate the results through summation to derive topic-level vector embeddings. Based on these vectors, calculate the similarity between adjacent-stage topics, using predefined similarity thresholds to classify evolution types such as split, merge, inheritance, extinction, and emergence. Finally, employ visualization tools like Sankey diagrams to intuitively present the topic evolution process, clearly illustrating inter-stage topic shifts and their interrelationships (Liu et al, 2021). The research framework design is depicted in Fig. 1.
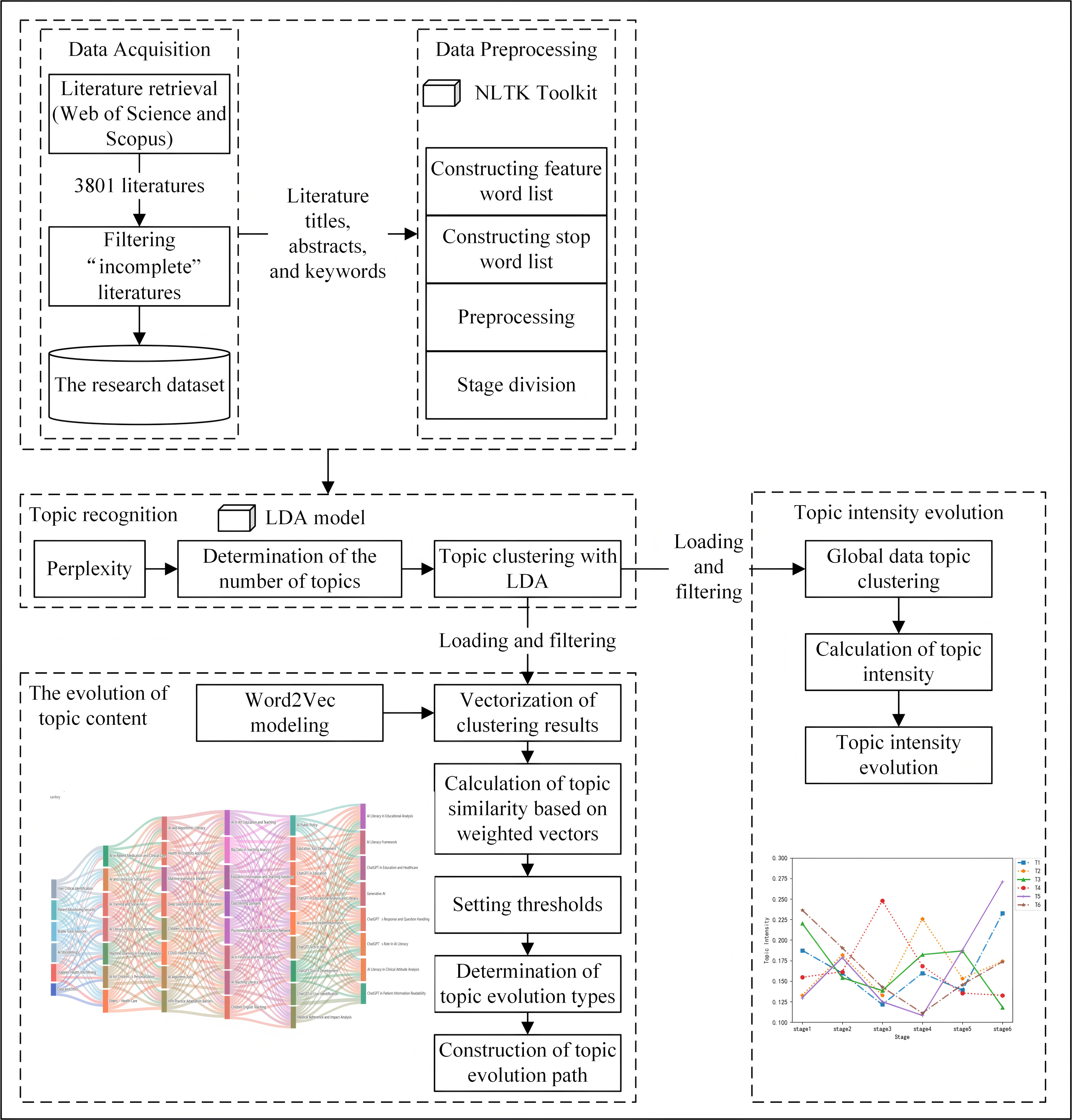 Fig. 1.
Fig. 1.
Overall analysis framework diagram. NLTK, Natural Language Toolkit; LDA, Latent Dirichlet Allocation.
This study’s data was sourced from the Web of Science and Scopus databases, with the search timeframe set to [2015]–[2024]. In Web of Science, the query string TS = (‘Artificial Intelligence literacy’ OR ‘AI literacy’) AND PY = (2015–2024) was used, while in Scopus, the keywords “artificial intelligence literacy” AND “AI literacy” were applied to search fields including Title, Abstract, and Keywords. This approach aimed to collect academic literature related to AI literacy as comprehensively as possible. To ensure data quality and relevance, retrieved results were filtered to exclude non-academic publications such as conference announcements, book reviews, and news articles. By standardizing document fields between Web of Science and Scopus, unifying formats, and merging datasets based on article titles, a final corpus of 3801 publications was compiled as the research dataset.
Data cleaning constitutes a critical step in the data preprocessing workflow. First, duplicate publications were removed by cross-referencing titles, authors, and abstracts to eliminate redundant entries, thereby minimizing redundancy-induced bias in the analysis. Next, data integrity validation was performed to filter out records with missing core information (e.g., incomplete titles, abstracts, keywords, or text content). Additionally, special characters and formatting inconsistencies were addressed using regular expressions and natural language processing (NLP) techniques to sanitize irregular symbols, garbled text, and non-standard encodings, ensuring uniform formatting across the dataset. Ultimately, 3361 validated publications were retained for topic analysis, distributed across six chronological stages. The number of documents in each stage is as follows: Stage 1 (2015–2019): 92; Stage 2 (2020): 115; Stage 3 (2021): 212; Stage 4 (2022): 289; Stage 5 (2023): 686; Stage 6 (2024): 1967. The procedural steps are as follows:
(1) Domain-Specific Lexicon Construction: An initial feature lexicon was built using titles, keywords, and abstracts, with Natural Language Toolkit (NLTK) employed for stemming, deduplication, and filtering.
(2) Text Normalization: Numeric values, punctuation, and special characters were
removed (e.g., simplifying “AI-education” to “AI education”) to reduce noise.
Lemmatization standardized terms to lowercase singular forms (e.g., “Algorithms
(3) Dynamic Stopword Optimization: A domain-specific stopword list was iteratively refined: high-frequency noise terms were excluded after initial LDA clustering, and five iterative refinement cycles retained core vocabulary directly related to AI literacy.
(4) Temporal Stage Partitioning: To analyze topic evolution, literature from 2015–2024 was divided into one 5-year phase (2015–2019, merged due to sparse data) and five 1-year phases (2020–2024). This partitioning enables dynamic tracking of research trajectories, balances uneven temporal distribution of publications, and identifies topic sudden shifts and persistent trends (Zhu et al, 2016). The approach enhances LDA model performance in cross-period semantic coherence and topic distinction, offering a robust framework for deciphering domain evolution, forecasting trends, and informing education policy (Laupichler et al, 2022).
Perplexity, as an evaluation metric for topic models, quantifies a model’s generalization capability to unseen texts. It is fundamentally the exponential form of cross-entropy, reflecting the model’s predictive uncertainty over word sequences in test data (Jurafsky and Martin, 2025). For LDA, perplexity measures generalization performance using held-out test data, with its core formula defined as Eqn. 1:
In this formula,
During computation, it is necessary to integrate the marginal probabilities
across all documents and topics, approximating the posterior distribution through
variational inference or Gibbs sampling (Blei et al, 2003). Notably,
perplexity is susceptible to hyperparameters
Topic Similarity Calculation via Weighted Vectorization. The Skip-gram model from Word2vec was selected to compute topic similarity. As a language training model in Word2vec, Skip-gram predicts contextual words based on a central term. In this study, topic similarity calculation aligns with this principle: treating topic terms as central words, predicting their contextually related vocabulary, and thereby capturing semantic relationships between topic terms. First, the preprocessed global-stage dataset was used as training data to train word embeddings via the gensim library in Python, constructing a word vector model. Next, the trained Word2vec model was applied to vectorize topic terms derived from LDA clustering, generating corresponding vectors for each topic term. To more accurately assess topic-term significance, the topic-term probabilities extracted by the LDA model were used as weights, multiplied by their respective Word2vec-generated vectors, and aggregated through weighted summation to obtain vector representations of topics. The Eqn. 3 is:
In equation,
Finally, Cosine similarity was employed to compute the similarity between adjacent temporal-stage topics. A cosine value closer to 1 indicates higher vector similarity, signifying greater topic alignment between the two topics. The Eqn. 4 is defined as:
This study employs a semantic similarity-based framework for topic evolution analysis, designed to uncover dynamic patterns in cross-stage knowledge structures. By defining a similarity threshold, the framework systematically identifies association states among topic clusters across adjacent temporal units, thereby categorizing five evolutionary patterns: merger, inheritance, disappearance, and emergence (Wallach et al, 2009).
Construction of Topic Evolution Pathways. The Sankey diagram tool from Python’s pyecharts library was utilized to visualize topic evolution pathways. In the Sankey diagram, each rectangular node represents a distinct topic, while the interconnecting flows (lines) between nodes denote evolutionary relationships. The flow direction indicates the trajectory of topic evolution, and the flow thickness corresponds to the strength of inter-topic associations. By inputting computed topic similarity scores and evolution type classifications into the Sankey tool, the study generates an intuitive visualization of the evolutionary pathways for AI Literacy research topics from 2015 to 2024. This graphical representation enables researchers to holistically trace topic continuity, divergence, or emergence, thereby deepening insights into the domain’s developmental dynamics.
Topic Intensity serves as a metric reflecting the attention level of a specific topic within a research domain. An increase in a topic’s intensity over a given period indicates rising scholarly interest and a growing volume of related publications. Calculating topic intensity aims to analyze shifts in the popularity of distinct topics across temporal stages, reveal transitions in research focus within AI literacy, and track changes in the significance of individual topics throughout the research lifecycle. This provides empirical grounding for understanding the field’s developmental trajectory. The Eqn. 5 is defined as:
Here,
The optimal number of topics for each stage was determined by calculating the perplexity of the LDA model. We divided the research timeline into multiple stages and computed perplexity values for different topic cluster counts within each stage’s literature dataset. Lower perplexity values indicate superior model performance, reflecting stable topic structures and minimized prediction errors. Using Python 3.12 (Wilmington, Delaware, United States), we processed the imported data to identify the optimal topic count for each stage. Through this method, the optimal number of topics for the six stages was determined as 6, 7, 8, 8, 9, and 8, respectively. Drawing on research categorizations from Web of Science and Scopus, we manually labeled the top 10 high-probability keywords for each topic based on their semantic significance. This process yielded the topic distribution across stages in AI Literacy, as summarized in Table 1.
| Stages | Topic words |
|---|---|
| Stage 1 | 1_1 (Data and Ethics): dataset, concerns, model, identify, impact; 1_2 (User Critical Identification): critical thinking, identify, user, information seeking, privacy; 1_3 (Diabetes Health Info Mining): diabetes, health information sources, health literacy, information, the network; 1_4 (Braille Tutor Sessions): braille, tutor, session, education, impairment; 1_5 (Patient Monitoring Security): attack, feature, patient monitoring, domain, deception; 1_6 (AI Storytelling): storytelling, knowledge, framework, creation, theory |
| Stage 2 | 2_1 (AI in Patient Medication and Clinical Care): factor, artificial intelligence, patient, medication, clinicians; 2_2 (AI and Literacy in Social Policy): policy, media literacy, internet literacy, artificial intelligence, society; 2_3 (Machine Learning in Financial Analysis): machine learning, consumer, credit, financial, analysis; 2_4 (AI Training and Social Focus): train, vehicle, peer assessment, focus, ideological; 2_5 (Elders’ Health Care): health, elders, chronic, caregivers, cognitive deficits; 2_6 (AI for Children’s Personalization): personalized, children, artificial intelligence, teach, growth mindset; 2_7 (AI Literacy in Industrial Detection): milling, walled workpiece, detection, ai literacy, parameter |
| Stage 3 | 3_1 (AI and Algorithmic Literacy): algorithm, technology, artificial intelligence, algorithmic literacy, challenge; 3_2 (Children’s Health Literacy): health, children, literacy, utilization, machine learning; 3_3 (Health AI Chatbots Application): health, artificial intelligence, technique, chatbots, service; 3_4 (Deep Learning in Children’s Education): teach, education, curriculum, children, deep learning; 3_5 (AI Algorithm Tools): artificial intelligence, algorithm, information, tool, literacy; 3_6 (COVID Health Service Issues): covid, service, health, pandemic, digital health; 3_7 (HPV Practice Adaptation Barriers): practice, HPV, adaptation, barrier, uncertainty; 3_8 (Machine learning in E-health): machine learning, e-health literacy, algorithm, medical, infodemic |
| Stage 4 | 4_1 (Education Information and Teaching Solutions): teach, education, information, privacy, solution; 4_2 (AI in Art Education and Teaching): art, teach, education, artificial intelligence, development; 4_3 (AI in Financial and music education): artificial intelligence, analysis, financial, music education, competence; 4_4 (Data Mining Domains): ai literacy, analysis, domain, data mining, algorithm; 4_5 (Big Data in Teaching Analysis): teach, big data, analysis, implementation, curriculum; 4_6 (AI Teaching Literacy): teach, ai literacy, programme, education, senior; 4_7 (Psychotherapy and Public Opinion Network): psychotherapy, public opinion, the network, supervision, management; 4_8 (Children English Teaching): teach, children, English, education, society |
| Stage 5 | 5_1 (AI Literacy and Health Information): literacy, artificial intelligence, information, health, technology; 5_2 (ChatGPT in Education): ChatGPT, knowledge, practice, education, potential; 5_3 (Education Tool Development): education, tool, human, response, development; 5_4 (ChatGPT in Educational Analysis and Literacy): education, ChatGPT, analysis, potential, literacy; 5_5 (ChatGPT Tech in Web): ChatGPT, technology, website, information, readability; 5_6 (ChatGPT in User Identification): ChatGPT, user, information, identify, survey; 5_7 (ChatGPT Tool in Development): development, question, ChatGPT, competency, tool; 5_8 (Medical Adherence and Impact Analysis): generative AI, impact, adherence, challenge, analysis; 5_9 (AI Public Policy): artificial intelligence, public, literacy, framework, regulation |
| Stage 6 | 6_1 (AI Literacy Framework): ai literacy, framework, role, assessment, feedback; 6_2 (AI Literacy in Educational Analysis): ai literacy, analysis, education, ethical, significant; 6_3 (ChatGPT in Patient Information Readability and Response): readability, ChatGPT, response, patient, information; 6_4 (ChatGPT in Education and Healthcare): ChatGPT.education, healthcare, patient, profession; 6_5 (Generative AI): education, generative AI, potential, technology, concerns; 6_6 (ChatGPT’s Role in AI Literacy): ChatGPT, ai literacy, role, attitude, impact; 6_7 (ChatGPT’s Response and Question Handling): ChatGPT.response, question, accuracy, quality; 6_8 (AI Literacy in Clinical Attitude Analysis): artificial intelligence, clinical, analysis, attitude, positive |
COVID, Corona Virus Disease; HPV, Human Papillomavirus; AI, Artificial Intelligence.
The stage-specific topic terms trained by the LDA model profoundly reflect critical issues within the AI literacy domain, as these topics—approached from multiple dimensions and perspectives—exhibit marked variability and diversity. Through in-depth analysis of research topics across different stages, we can not only trace the historical trajectory of AI literacy’s evolution but also acutely identify its contemporary trends, emerging challenges, and potential future directions. Consequently, comprehensive summarization and analysis of these topic terms hold significant practical and academic value. The temporal stage division, grounded in the technological maturity of AI literacy and evolving societal demands, chronologically captures the paradigm shifts in research focus—from foundational cognition to human-AI collaboration. The six stages collectively map the spiral progression of knowledge production modes, transitioning from enlightenment to symbiotic coexistence.
(1) Knowledge Enlightenment Stage: Technological Cognition and Ethical Framework Foundations (2015–2019). This phase marks the inception of AI literacy research, characterized by the establishment of a technological foundation centered on “Data and Ethics”, which propelled normative debates on algorithmic transparency and data privacy (Lutz, 2019; Long and Magerko, 2020). The introduction of “User Critical Identification” further emphasized individual autonomy and reflective awareness in human-AI interactions. The research scope gradually expanded to healthcare and educational equity practices, where initial validations of social responsibility frameworks were conducted, highlighting the boundaries of AI accountability in addressing critical societal issues. Concurrently, emerging topics such as “AI Storytelling” reflected a paradigm shift from instrumental rationality to humanistic values, infusing the literacy framework with new dimensions of technology communication and ethical empathy.
(2) Knowledge Symbiosis Stage: Coupling Societal Needs with Technical Competencies (2020). Research on AI literacy demonstrated deepened contextualization and alignment with social governance imperatives (Perchik, 2022). The focus shifted from technical ontology to constructing a “Socially Embedded AI Competency Framework”, manifested across three dimensions: First, the healthcare domain developed vertically specialized pathways, encompassing technical-ethical practices such as “AI in Patient Medication and Clinical Care”, alongside intergenerationally inclusive designs like “Elders’ Health Care” and “AI for Children’s Personalization”, reflecting lifecycle-wide literacy demands. Second, technical capacity-building and socio-political policymaking formed bidirectional synergies: “Machine Learning in Financial Analysis” and “AI Literacy in Industrial Detection” enhanced decision transparency in specialized sectors, while “AI and Literacy in Social Policy” drove institutional innovation, establishing a feedback loop between technological empowerment and governance frameworks. Third, the prominence of “AI Training and Social Focus” signaled a paradigm shift from individual skill development to collective cognitive advancement, fostering multi-stakeholder competency co-creation to address complex ethical challenges in technological socialization (Cardon et al, 2023).
(3) Knowledge Critique Stage: Parallel Advancement of Technical Ethics and Problem Reflection (2021). Research on AI literacy entered a new phase marked by the deep integration of technological tool innovation and public health ethics (Ng et al, 2021a). The framework is anchored in “Algorithmic Literacy and Tool Development” as its technical foundation, driving the intelligent allocation of medical resources through innovations such as “Health AI Chatbots” and “Machine Learning in E-Health”. These tools specifically addressed public health crises like “Corona Virus Disease-19 (COVID-19) Health Service Gaps” and “Human Papillomavirus (HPV) Practice Adaptation Barriers”, while scrutinizing algorithmic transparency challenges in healthcare and education. Concurrently, the research focus shifted toward precision adaptation to intergenerational disparities: in education, “Deep Learning in Children’s Education” became central to building ethical evaluation systems for personalized learning: in healthcare, efforts bridged “Children’s Health Literacy” development with elderly health interventions, forming a full-lifecycle health empowerment loop. Notably, studies on algorithmic transparency expanded from “AI Algorithm Tools” development to analyzing “Practical Implementation Barriers”, uncovering friction mechanisms between technological applications and sociocultural cognition (Howard, 2019). This stage critically examined technological instrumentalization, advocating an ethical principle prioritizing “social acceptability” over “technical usability” (Keller and John, 2019).
(4) Knowledge Convergence Stage: Breakthroughs in Interdisciplinary Cognitive Frameworks (2022). Research on AI literacy exhibited dual characteristics of pan-educational scene penetration and cross-modal cognitive framework reconstruction (Kong et al, 2022).The paradigm centered on “Educational Information and Pedagogical Solutions” as a hub, leveraging “Big Data in Teaching Analysis” and “Data Mining Domains” to build intelligent educational decision-making systems, driving a paradigm shift from experience-driven to data-empowered educational workflows. Research boundaries expanded into multidisciplinary depths: AI-driven aesthetic generation in art education, interdisciplinary integration of finance-music education, and cognitive adaptation models for “Children’s English Teaching” collectively mapped a tripartite logic coupling “technological tools–disciplinary knowledge–cognitive principles” (Zhang and Aslan, 2021). Simultaneously, the public dimension of AI literacy extended into socio-psychological realms, with emerging topics like “Psychotherapy and Public Opinion Networks” revealing interaction mechanisms between technical capabilities and collective emotional governance. Notably, “AI Teaching Literacy” evolved from a singular focus on tool operation into a multidimensional competency framework encompassing technical ethics, interdisciplinary integration, and data-critical thinking, signifying the dissolution of disciplinary barriers and the evolution of fragmented knowledge into a transdisciplinary knowledge ecosystem.
(5) Knowledge Creation Stage: Generative AI-Driven Paradigm Shift (2023). Research on AI literacy reached a watershed moment with the societal maturation of generative AI technologies, forming an evolutionary trajectory of “foundational technological breakthroughs–vertical scenario reconfiguration–public governance responses” (Casal-Otero et al, 2023). The focus shifted to the technological penetrability of large language models like ChatGPT, with foundational breakthroughs manifested as: a paradigm upgrade in education from “tool-assisted instruction” to “cognitive infrastructure”: vertical scenario reconfiguration through “ChatGPT in Educational Analysis and Literacy” to build human-AI collaborative pedagogical decision-making systems, while addressing trust and ethical bottlenecks in generative AI via “ChatGPT in User Identification”: public governance responses materialized as health information governance forming a “data-behavior-policy” transmission chain, with “AI Literacy and Health Information” bridging micro-level behavioral interventions (e.g., “Medical Adherence and Impact Analysis”) and macro-level institutional designs (e.g., “AI Public Policy”). Notably, the technological extensibility of ChatGPT propelled research into web ecosystem layers, where its tool development transcended single-application logic to establish cross-scenario intelligent literacy foundations, marking the transition of knowledge production into autonomous creation and systematized governance.
(6) Knowledge Symbiosis Stage: Human-Machine Collaborative Cognitive Revolution (2024). Research on AI literacy signifies a paradigm shift where generative AI technologies transition from scenario-specific tools to cognitive infrastructure (Chen, 2024). The core breakthrough lies in the systematic construction of the “Generative AI Literacy Framework”, which establishes competency evaluation standards—“technical comprehension–ethical judgment–behavioral adaptation”—driven by large language models, validated bidirectionally through “AI Literacy in Educational Analysis” and “AI Literacy in Clinical Attitude Analysis”. The study deconstructs ChatGPT’s multifaceted roles: in healthcare, “ChatGPT in Patient Information Readability and Response” addresses classical challenges of asymmetric clinician-patient cognition, while its adaptive interaction mechanisms in “ChatGPT in Education and Healthcare Cross-Scenario Services” shift literacy cultivation from static knowledge transmission to dynamic problem-solving (Kimiafar et al, 2023). Crucially, generative AI no longer confines itself to tool innovation: instead, as a “Core Enabler in the AI Literacy Framework” (“ChatGPT’s Role in AI Literacy”), it reconstructs knowledge systems from passive dissemination to human-AI symbiotic collaboration through cross-scenario services.
To intuitively visualize the evolutionary trends and pathways of AI literacy
topics, this study first calculated topic similarity for research spanning
2015–2024. Beyond the initial cosine similarity metrics, we innovatively
calculated topic similarity based on topic embeddings generated via LDA2vec,
which integrate LDA’s topic-word probabilities with Word2vec’s semantic vectors.
Based on these computations (including both traditional cosine similarity and the
new LDA2vec-derived embeddings-based similarity), an adjacent-stage topic
similarity matrix was constructed to quantify the semantic associations between
topics across consecutive temporal phases. In text mining, topics with term
probabilities
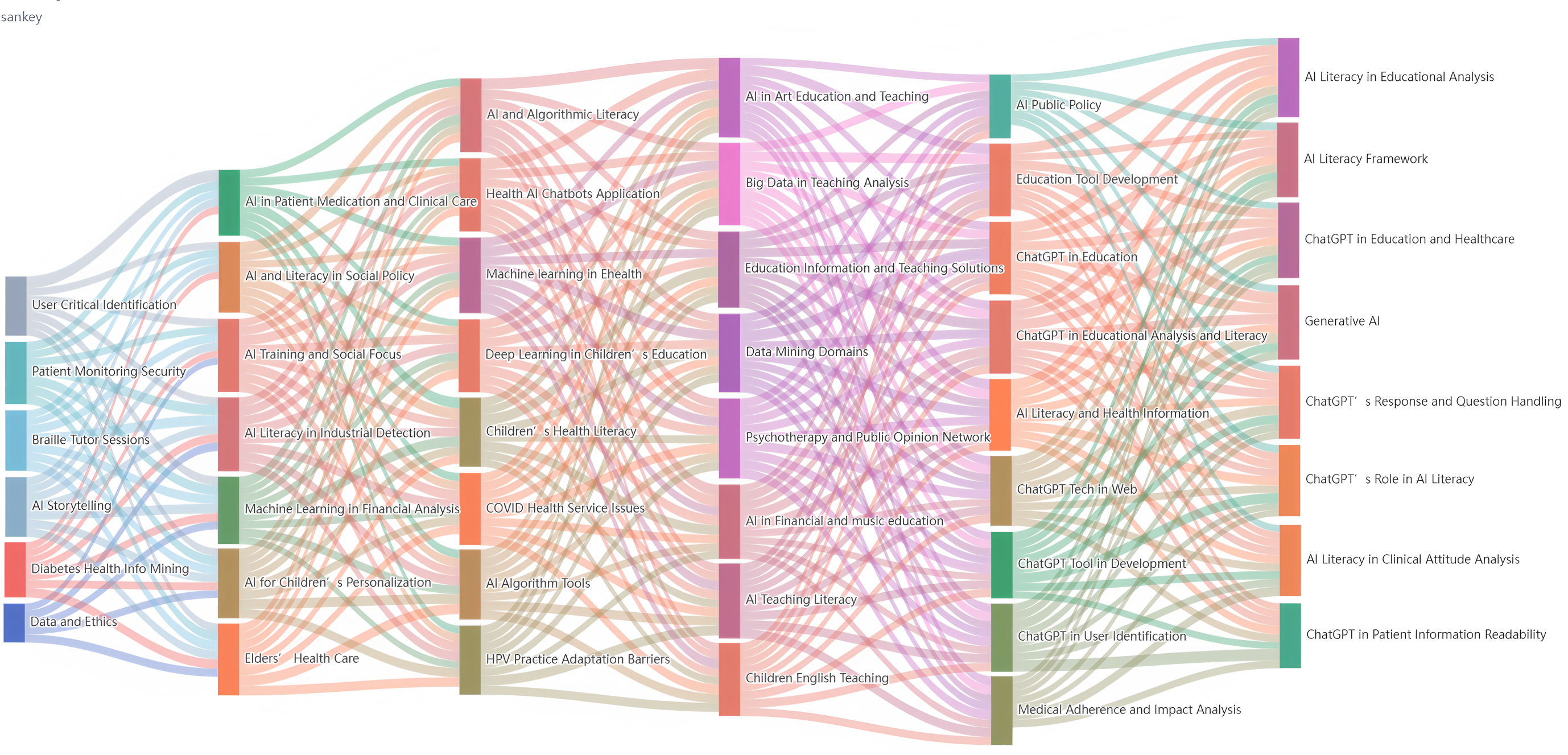 Fig. 2.
Fig. 2.
The topic content evolutionary path.
(1) Differentiation, Merger, and Inheritance Types. By referencing the classification criteria for topic evolution types and analyzing the topic evolution pathways, we observe that differentiation and merger types dominate among all topic evolution categories, accounting for the largest proportions. This phenomenon profoundly reflects the dynamic nature of knowledge advancement and underscores that differentiation and merger are not abrupt shifts but gradual processes that necessitate iterative inheritance overtime. Such patterns demonstrate the temporal continuity of core research agendas, where foundational topics persist and adapt across stages while integrating new conceptual dimensions.
(2) Topic Evolution Differentiation Types. The differentiation type describes the process where a topic gradually branches over time into multiple more specialized subtopics. For instance, the topic “Data and Ethics” (stage 1_1) was divided into subtopics: “AI and Algorithmic Literacy” (stage 3_1), “AI Algorithm Tools” (stage 3_5), and “AI Literacy Framework” (stage 6_1). This signifies a shift in AI literacy ethics research from theoretical abstraction to practical operability, revealing interdisciplinary knowledge reorganization that upgrades ethical knowledge from an “external constraint” to an “endogenous variable”. Through the integration of a global governance framework (stage 6_1), fragmented domain practices are unified into a cohesive cognitive foundation, forming a knowledge system with both theoretical explanatory power and policy intervention capacity, thereby offering scalable, iterative solutions for AI literacy’s societal complexities. Similarly, the topic “AI in Patient Medication and Clinical Care” (stage 2_1) split into “Health AI Chatbots Application” (stage 3_3), “Medical Adherence and Impact Analysis” (stage 5_8), and “ChatGPT in Patient Information Readability” (stage 6_3). This marks an innovation in medical AI literacy knowledge production, transcending traditional single-point technical optimization. By empowering patients to transition from “passive recipients” to “active participants” and equipping clinicians with end-to-end data-to-decision support, it redefines patient-provider dynamics in AI-augmented healthcare (Ali et al, 2023). Lastly, the topic “AI Teaching Literacy” (stage 4_6) branched into “AI Literacy in Educational Analysis” (stage 6_2), “ChatGPT in Education and Healthcare” (stage 6_4), and “Response and Question Handling” (stage 6_7). This reflects a paradigm shift in educational AI literacy research, moving beyond the confines of “technology-assisted instruction” to redefine the foundational logic of pedagogical literacy in the intelligent era, emphasizing adaptive problem-solving and cross-domain cognitive integration.
(3) Topic Evolution Merger Types. The merger type “ChatGPT in Education and Healthcare” (stage 6_4) integrates cross-domain knowledge from education (stage 3_2), health (stage 4_8), and policy (stage 5_9), revealing innovations in transdisciplinary knowledge production driven by AI literacy. Through “system interoperability” enabled by technological mediation, it unifies physiological indicators (health literacy), cognitive trajectories (language proficiency), and institutional constraints (policy design) into a cohesive intervention framework for child development. This marks a shift from single-issue remediation to sociotechnical ecosystem optimization in AI literacy-driven interventions, offering systemic solutions that harmonize biological principles, learning sciences, and governance realities. Similarly, the merger type “Generative AI” (stage 6_5) synthesizes industrial quality inspection (stage 2_7) and medical intervention (stage 5_8), redefining cross-domain knowledge production paradigms. Generative AI encodes the spatial topological logic of industrial scenarios and the temporal causal logic of healthcare into a unified computable knowledge system, catalyzing a bidirectional innovation pathway of “machine vision cognition–human behavioral inference”. Additionally, the merger type “ChatGPT in Patient Information Readability and Response” (stage 6_3) synergistically addresses public health emergencies (stage 3_6) and techno-cultural barriers (stage 3_7), exemplifying crisis-driven knowledge production innovation. ChatGPT integrates dynamic response logic during health crises with static cultural barriers in technology adoption, forming a “technologically mediated knowledge reconstruction” framework. This mechanism deeply aligns technical responsiveness with cultural contexts, automatically adapting to local linguistic norms and belief-based taboos, thereby bridging the divide between “technical precision” and “cultural acceptance” in public health interventions. The result is a data-linked, dynamically balanced intelligent decision-making framework that accommodates multi-stakeholder needs.
(4) Topic Evolution Inheritance Types. The inheritance type is exemplified by the paradigm reconfiguration of “User Critical Identification” (stage 1_2) through generative AI technologies (stage 5_6/stage 6_7), marking a knowledge revolution in human-AI interaction theory. The ChatGPT-driven identity verification mechanism transcends traditional entity-binding logic reliant on biometrics, constructing an innovative framework based on cognitive-behavioral flow topology analysis. This shift from “entity-binding” to “behavioral flow analytics” not only preserves the core objective of “user critical identification” from earlier research but also enables adaptive evolution in identity recognition through real-time cross-scenario behavioral data correlation, establishing a cognitively aligned trust mechanism for human-AI collaboration. The topics “Medical Adherence and Impact Analysis” (stage 5_8) and “AI Literacy in Clinical Attitude Analysis” (stage 6_8) evolved from “AI in Patient Medication and Clinical Care” (stage 2_1), pioneering a transdisciplinary knowledge production paradigm in clinical behavioral science. By leveraging reinforcement learning for real-time intervention strategy iteration, this paradigm not only redefines the empirical foundation of behavioral medicine but also catalyzes the emergence of clinical decision manifold theory. The paradigm shift in “Big Data in Teaching Analysis” (stage 4_5) unveils a meta-model innovation in translating data science into cognitive science. It transitions traditional pedagogical big data (stage 4_5) from behavioral correlation analysis to cognitive mechanism interpretation (stage 6_2), while reconstructing the foundational logic of cognitive interventions via generative technologies (stage 6_5). This advancement not only dissolves disciplinary barriers between education and cognitive science but also inaugurates a new paradigm of educational neuro-symbolic AI.
(5) Topic Evolution Disappearance and Emergence Types. The isolated obsolescence of technological nodes (e.g., stage 1_6, stage 2_3, stage 4_3) reveals a compensatory evolution law of cross-domain connectivity within knowledge innovation ecosystems: when specific technologies (e.g., narrative AI) fail to achieve deep integration between “technological narratives” and “cognitive architectures” through generative infrastructures (stage 6_5), or when domain applications lack institutional support from policy frameworks (stage 5_9), their knowledge production value is systematically reconfigured into network-centric alternatives (stage 6_4). The co-emergence of generative AI-driven technological infrastructures (stage 6_1/stage 6_5) and human-AI collaborative paradigms (stage 6_6/stage 6_7) signifies a topological revolution in knowledge production ecosystems. By constructing a three-dimensional governance manifold (“ethics-algorithms-policy”, stage 6_1) and a cross-domain cognitive infrastructure (“industry-healthcare-education”, stage 6_5), generative AI not only enables ubiquitous penetration of technical capabilities but also catalyzes self-organizing principles for trans-domain knowledge production networks, redefining the axiomatic logic of socio-technical evolution.
Stage-Specific Evolutionary Linkage Characteristics. Across different stages, the evolutionary capacity of topics exhibits variability. Within adjacent intervals, topics are interconnected by dense, progressively expanding linkages, reflecting intensifying cross-stage interactions. The topic evolution linkages within intervals are characterized by:
(1) Diversity. Stage 1 and stage 2 independently developed within domains such as education, healthcare, and industry, with topics spanning vertical scenarios like algorithmic finance and data mining. For instance, “User Critical Identification” (stage 1) and “Educational Tool Development” (stage 2) formed technological silos, exemplifying single-domain innovation (Su et al, 2023). Stage 3 and stage 4 introduced non-technical topics such as policy, ethics, and societal focus, addressing diverse demands ranging from foundational pedagogy to special education (Kong et al, 2021). Stage 5 and stage 6 encompassed generative AI integration across education, healthcare, and public opinion networks, transitioning from “AI Training and Social Focus” to “Health-Opinion Networks”, reflecting the deep integration of technical and societal issues.
(2) Interconnectivity. In stage 2, the initial emergence of “Generative AI” is depicted by sparse pink flows linking education and healthcare. “Medical Monitoring Safety” (purple flow) unidirectionally feeds into “Clinical Attitude Analysis”. In stage 3, green flows (healthcare) and orange flows (policy) intertwine, forming “technology-institution feedback loops”. For example, “Children’s Health Literacy” (gold flow) bidirectionally connects “Health Information Readability” and “AI Social Policy”. In stage 6, purple flows (healthcare), green flows (education), and orange flows (policy) converge through the “Generative AI” node (stage 6_5) to form a closed-loop system. Notably, the “ChatGPT in Education and Healthcare” node (stage 6_4) in Fig. 2 acts as a superhub, connecting over 10 subtopics via gold flows, demonstrating unparalleled cross-domain integration.
(3) Dynamicity. From stage 1 to stage 2, flow directions transitioned from
unidirectional pathways (e.g., educational data
Topic Intensity Evolution reveals the temporal variations in topic prominence within the AI literacy domain. Through the calculation of perplexity and training of the LDA model, this study determined the number of topic clusters in the global stage to be 6. Subsequently, six topics were identified and labeled as: “Intelligent Ethics” (T1), “Smart Livelihoods” (T2), “Health Education” (T3), “Smart Education” (T4), “Technological Applications” (T5), and “Literacy Empowerment” (T6). To further enhance the credibility of this topic-clustering result, we introduce the word-cloud diagram in Fig. 3. The word-cloud diagram, which is generated based on the keywords of all topics, visually presents the frequency and distribution of these keywords. By observing the word-cloud, we can intuitively see that keywords corresponding to each topic. The top 10 keywords for each topic are listed in Table 2.
 Fig. 3.
Fig. 3.
The word-cloud diagram.
| Topics | Topic words (Top 10) |
|---|---|
| T1: Intelligent Ethics | artificial intelligence, ethical, privacy, algorithm, concerns, regulation, framework, impact, identify, transparency |
| T2: Smart Livelihoods | artificial intelligence, public, society, service, elders, children, support, technology, management, charity |
| T3: Health Education | health, education, health literacy, information, teaching, diabetes, covid, HPV, utilization, clinical |
| T4: Smart Education | education, generative AI, system, teach, curriculum, ChatGPT, deep learning, big data, tool, ai literacy |
| T5: Technology Applications | technology, application, artificial intelligence, machine learning, data mining, algorithm, digital health, industrial, e-health, implementation |
| T6: Literacy Empowerment | literacy, ai literacy, health literacy, media literacy, internet literacy, empowerment, utilization, competence, education, development |
After identifying the six global-stage topics, we calculated the topic intensity for each topic across stages using the topic intensity evolution formula. Based on the results, a topic intensity trend diagram was plotted, as shown in Fig. 4.
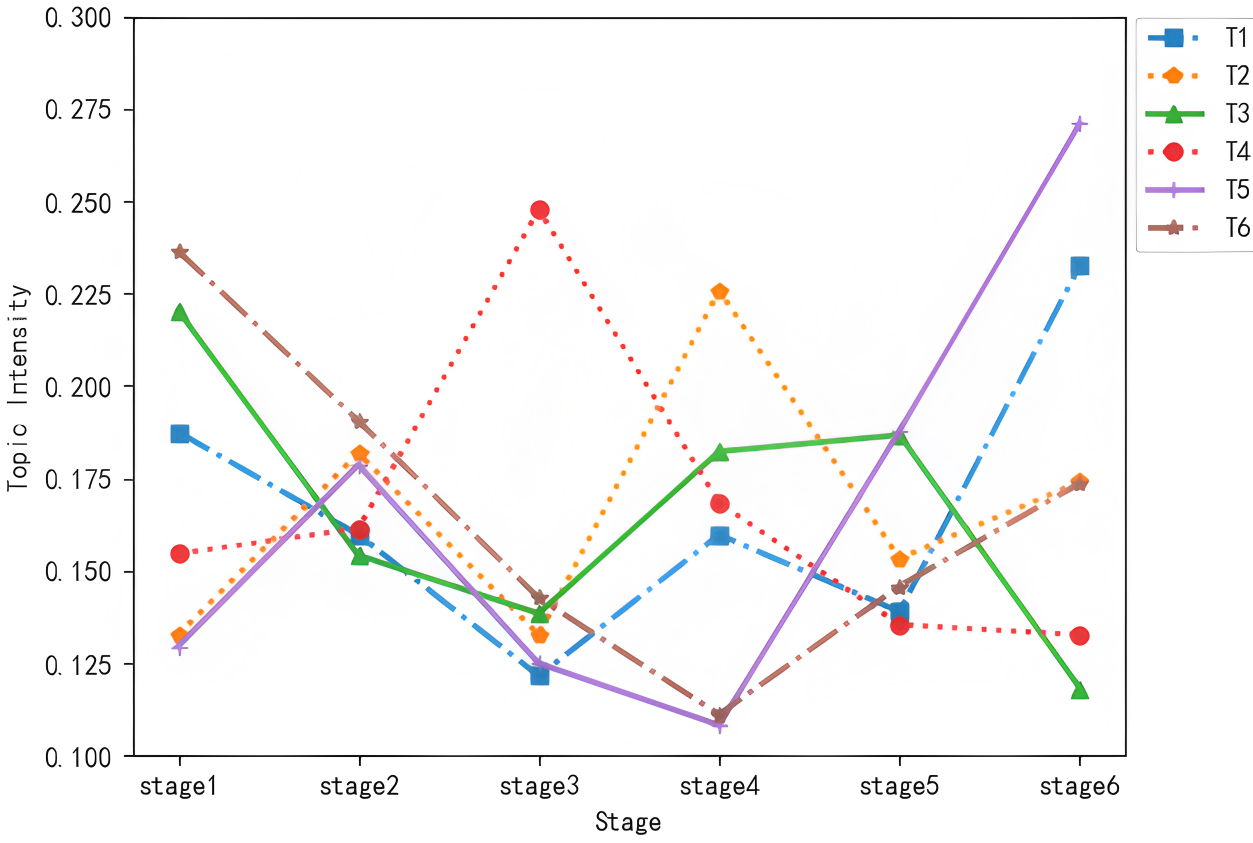 Fig. 4.
Fig. 4.
Evolutionary trend of topic intensity.
Analysis of Topic Intensity Trends. As shown in Fig. 4, Intelligent Ethics (T1, blue dashed line): The intensity is relatively high in stage 1 (2015–2019), then fluctuates and declines from stage 2 (2020) to stage 4 (2022). After a drop in stage 5 (2023), it rebounds in stage 6 (2024). This trend aligns with the initial policy attention to AI ethics (e.g., the EU’ s Digital Competence Framework 2.0 in 2015 emphasizing algorithmic logic understanding). The mid-term decline reflects a temporary shift toward technical application amid rapid AI advancement, while the late rebound is driven by ethical crises from generative AI (e.g., deepfakes, biased content), prompting renewed focus on regulatory frameworks.
Smart Livelihoods (T2, orange dotted line): The intensity surged in stage 2 (2020), declined in stage 3 (2021), peaked in stage 4 (2022), and then decreased afterward. The 2020 surge was fueled by the COVID-19 pandemic, which accelerated demand for AI-driven public services (e.g., remote healthcare, smart community management). The 2021 dip resulted from challenges in scaling early solutions, while the 2022 peak corresponded to mature deployments (e.g., AI-enabled elderly care, child safety systems). The subsequent decline reflects a shift to more specialized subfields (e.g., targeted services for vulnerable groups).
Health Education (T3, green solid line): The intensity was highly emphasized in stage 1 (2015–2019) but dropped sharply in stage 2 (2020), followed by a slight rebound in stages 3–5 (2021–2023) before declining again in stage 6 (2024). Early focus stemmed from initial explorations of AI in health literacy (e.g., diabetes information mining). The 2020 drop occurred as research attention shifted to urgent pandemic-related AI applications (e.g., COVID-19 tracking). The modest rebound reflected post-pandemic interest in AI-aided health education, but the 2024 decline arose from its replacement by integrated health-AI frameworks (e.g., clinician-AI collaborative systems) that transcended single-scenario education.
Smart Education (T4, red dotted line): The intensity peaked significantly in stage 3 (2021), with relatively stable intensity in the preceding and subsequent stages. The 2021 peak coincided with global initiatives like the U.S. “AI4K12” standards and deep learning applications in K-12 curricula, driving concentrated research on AI’s pedagogical implementation. Stable pre- and post-peak intensity reflects sustained baseline interest, as focus shifted from theoretical frameworks to iterative optimization of existing educational tools.
Technology Applications (T5, purple solid line): The intensity remained low from stages 1–4 (2015–2022) but began a steady rise in stage 5 (2023), with a sudden surge in stage 6 (2024). Early low intensity was due to limited technological maturity—early AI models had narrow application scopes and struggled with real-world integration. The 2023 rise followed breakthroughs in generative AI (e.g., GPT-4) enabling cross-domain deployment, while the 2024 surge was catalyzed by large-scale adoption (e.g., LLM-based diagnostic tools, intelligent teaching assistants) and policy support.
Literacy Empowerment (T6, brown dashed line): The intensity starts at its highest in stage 1 (2015–2019), gradually declines through stages 2–4 (2020–2022), then begins to rise steadily from stage 5 (2023) onward, with a notable surge in stage 6 (2024). The initial high intensity in stage 1 aligns with early efforts to define foundational literacy frameworks (e.g., the 2018 formal conceptualization of AI Literacy by the University of Southern California). The gradual decline through stages 2–4 reflects a temporary focus on technical development over competency building, as researchers prioritized advancing AI tools over literacy frameworks. The resurgence from stage 5 onward is driven by the widespread adoption of generative AI, which exposed critical literacy gaps—this prompted urgent demand for empowerment initiatives, such as UNESCO’s 2024 Student and Teacher AI Competency Frameworks, fueling the sharp rise in stage 6.
Most themes exhibit a pattern of “initial attention—mid-term fluctuations—late-stage divergence”, reflecting the field’s trajectory from foundational theories to practical applications, then to technological reflection. T5’s surge highlights the shift toward “technology implementation”, propelled by generative AI breakthroughs. T3’s consistent low intensity reveals limitations of single-scenario research, while T2’s periodic peaks demonstrate public demand-driven trends. These dynamics provide a clear basis for analyzing the AI literacy landscape and identifying future directions (e.g., deepening T5 and reinforcing T1 ethical standards).
The research topics in the AI literacy domain exhibit a three-tiered
‘technological infrastructure–scenario penetration–paradigm reconfiguration’
knowledge production architecture, which is inherently a knowledge organization
system. The technological infrastructure layer, anchored in foundational issues
such as algorithmic transparency (stage 3_1) and data ethics (stage 1_1),
constructs a meta-theoretical framework for knowledge innovation by classifying
core concepts and establishing their semantic relationships—key practices in
knowledge organization. For example, “AI algorithm tool development” (stage
3_5) not only generates technical knowledge but also catalyzes novel
methodologies like “interpretability design” (stage 6_3), driving the
transition from experience-driven to computationally validated knowledge
production. The scenario penetration layer forms knowledge diffusion networks in
vertical domains such as healthcare (stage 2_1
The topic evolution of AI literacy research comprehensively demonstrates a
six-stage spiral trajectory of “Knowledge Enlightenment
Research in AI literacy is undergoing a profound paradigm shift from a “techno-instrumental paradigm” to a “human-AI symbiotic paradigm”, grounded in the techno-social coevolutionary dynamics revealed through topic evolution analysis. Future studies in AI literacy will adopt a tripartite knowledge production architecture integrating “technological advancement–cognitive paradigms–institutional frameworks”. At the technological advancement level, the explosive proliferation of generative AI (post-2023 topic intensity surge) directly reconfigures knowledge production logic, with its cross-domain connectivity in healthcare and education scenarios significantly outpacing traditional technologies, driving cognitive modeling from tool efficiency to human-AI collaboration. For instance, dynamic literacy assessment systems based on large language models demonstrate far superior alignment accuracy compared to static evaluations in Hong Kong’s preschool education practices, confirming the decisive role of technological infrastructure in shaping cognitive manifolds. Notably, Hong Kong’s linguistic context—marked by the coexistence of Cantonese, English, and Mandarin, alongside prevalent code-switching—presents unique challenges for AI literacy research. Technical terminologies central to AI (e.g., ‘algorithmic bias’) often undergo translation across these languages, with subtle semantic shifts that may influence educators’ and learners’ grasp of core concepts. Such linguistic nuances could partially account for the observed variations in assessment accuracy between Hong Kong’s preschool settings and those in American English-dominant contexts, underscoring the importance of addressing cross-linguistic and cross-cultural factors when developing universal AI literacy frameworks. At the cognitive paradigm level, interdisciplinary knowledge recombination—evidenced by the surge in topic mergers (2022–2024)—forms trans-domain connective networks. For example, medical ethics (stage 3_3) and educational equity (stage 4_6) establish robust correlations through generative AI nodes (stage 6_5), predicting systemic efficiency gains in cross-domain problem-solving, a hypothesis corroborated by empirical data from MIT’s “AI+X” curriculum showing enhanced learner cross-domain capabilities. The cognitive migration between clinical decision support (stage 6_8) and educational diagnostics (stage 6_2) demonstrates that cross-scenario knowledge transfer has transcended traditional boundaries, enabling techno-cognitive dual drivers for trans-domain knowledge production. Concurrently, literacy institutional frameworks will evolve dynamically: the annual growth rate of ethical governance topics and their coupling intensity with technical topics highlight the urgency of institutional innovation. The synergy between multimodal data streams (stage 6_2/stage 6_7) and personalized adaptation topics (stage 6_4) predicts the future upgrade of OECD assessment systems into real-time diagnostic platforms. These trends collectively signal a paradigm shift in AI literacy research from “technical proficiency” to “cognitive infrastructure”, ultimately propelling knowledge innovation into a new era of “human-AI symbiosis”, where socio-technical ecosystems are redefined through seamless integration of adaptive tools, ethical governance, and cognitive co-creation.
This study systematically reveals the evolutionary trajectory of the AI literacy knowledge system from enlightenment to symbiosis through LDA2vec model-based topic evolution analysis of research from 2015 to 2024, validating the paradigm reconfiguration of knowledge production mechanisms during technological socialization. The findings demonstrate that generative AI-driven human-machine cognitive collaboration not only achieves transformative leaps in knowledge forms but also facilitates a qualitative shift in the knowledge innovation ecosystem—from linear accumulation to symbiotic co-creation—through a technical-ethical-social dynamic capability network, where ethical governance frameworks and socio-technical adaptability evolve synergistically to redefine the epistemic foundations of AI-augmented societies.
The study reveals that the evolution of AI literacy exhibits spiral progression characteristics: during the Knowledge Enlightenment period (2015–2019), it centered on algorithmic comprehension and data ethics, focusing on foundational technological construction: the Knowledge Integration period (2020–2022) expanded into vertical scenarios like healthcare and educational equity, forming a “technology-policy-society” collaborative innovation network: the Knowledge Creation and Symbiosis period (2023–2024) leveraged large language models as cross-domain hubs to transcend disciplinary boundaries, constructing a transdisciplinary cognitive infrastructure that revolutionizes knowledge production from tool empowerment to human-AI collaboration. Topic intensity analysis shows alternating dominance between technological applications and ethical issues, confirming “techno-social adaptation” as the core challenge of the new era. Addressing three central questions, this paper provides empirical answers: (1) AI literacy research has evolved from algorithm-based ethical frameworks to digital twin-enabled vertical scenario penetration, culminating in generative AI-driven cross-domain cognitive infrastructure; (2) its knowledge innovation breakthroughs manifest as a tripartite interplay of technological iteration, crisis response mechanisms, and cognitive framework restructuring, establishing a “technology-institution-society” coevolutionary system; (3) future research will prioritize human-AI collaboration, trans-domain knowledge production, and literacy governance frameworks, advancing AI literacy from tool adaptation to ecological civilization paradigms. These findings offer theoretical references and practical pathways for governing AI literacy education and designing ethical frameworks in the intelligent era, bridging the gap between technological advancement and socio-ethical sustainability.
Additionally, this study has certain limitations: the data sources are concentrated in Web of Science and Scopus databases, potentially omitting non-English literature and grey literature, resulting in insufficient coverage of practice-oriented topics: the temporal window partitioning (e.g., lumping 2015–2019 into a single stage) may obscure nuanced evolutionary trajectories of early topics, necessitating future refinements using wavelet analysis to optimize temporal granularity. In conclusion, this exploratory work aims to propel AI literacy research from ‘technological adaptation’ toward ‘societal symbiosis’, with a focus on advancing knowledge organization in the field—systematically structuring, classifying, and interrelating AI literacy concepts to enhance their utility across domains. It offers more robust academic foundations for building an inclusive digital civilization that harmonizes technological advancement with humanistic values and institutional resilience, aligned with the mission of knowledge organization.
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
TZ: Proposal of research topic, Conceptual framework design; PZ: Draft writing, Data analysis, Visualization, Revision; HM: Review, Provision of revision suggestions, Data interpretation, Paper revision. All authors contributed to editorial changes in the manuscript. All authors read and approved the final manuscript. All authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
Not applicable.
This research was funded by the National Social Science Fund General Project “Research on the Risk Governance Path of Intelligence Analysis Algorithms in the Digital Intelligence Environment”, grant number 22BTQ064, and the Natural Science Foundation of Heilongjiang Province of China, “Research on the Construction of Interpretable Models for Intelligent Algorithms in Complex Systems under Uncertain Environments”, grant number PL2024G019.
The author declares no conflict of interest.
During the writing process of this research, the authors used ChatGPT-3.5: in addition to basic spelling and grammar checks, this tool was specifically used to assist in the translation of non-English content and the polishing of academic expressions.
All content generated or modified by artificial intelligence (including translated texts and polished expressions) has undergone systematic review, editing, and verification by the authors. This process includes cross-checking the translated content with multilingual original sources to ensure accuracy and consistency, adjusting the polished expressions to preserve the original research intent of the study, and verifying that the overall writing style meets the requirements of academic rigor.
The authors assume full responsibility for the final content of this publication, confirming that all materials assisted by artificial intelligence in translation or polishing have undergone comprehensive human supervision, and that the authenticity, accuracy, and ethical compliance of this research are solely the responsibility of the authors.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.