



1 Institute of History and Philology, Academia Sinica, 11529 Taipei, Taiwan
2 Graduate Institute of Library, Information and Archival Studies, National Chengchi University, 11605 Taipei, Taiwan
3 Department of Library and Information Science, National Taiwan University, 106319 Taipei, Taiwan
Abstract
Generative Artificial Intelligence (GAI) has emerged as a transformative tool for knowledge organization, offering new possibilities for thesaurus construction through automated synonym identification and scope note generation. This study investigates the integration of GAI into thesaurus development and proposes a structured AI-human collaborative framework to enhance lexical precision and contextual accuracy. Using Confucius Ceremony cultural vocabulary as a case study, the research evaluates AI’s ability to identify synonym relationships and generate structured scope notes through prompt engineering combined with expert validation. An iterative experimental design was adopted, incorporating gold sample testing, structured prompt frameworks, and expert-guided refinements to optimize AI-generated outputs. Results indicate that AI, when directed by structured prompts, can efficiently identify core synonyms and generate semantically rich scope notes. However, challenges persist in contextual reasoning, historical lexicon interpretation, and cultural nuance recognition. The findings highlight the importance of ontology-based reasoning, explicit metadata integration, and domain-specific knowledge graphs in improving AI’s applicability to knowledge organization systems (KOS). This study contributes to AI-assisted thesaurus development by outlining best practices in prompt engineering and human-AI collaboration for multilingual and historically complex terminologies. Future research should explore AI’s adaptability across broader domains, including structured scientific thesauri and indigenous knowledge systems while advancing automated evaluation methods and transparency mechanisms for AI-generated lexicographic content. The findings underscore the necessity of integrating AI capabilities with human expertise to ensure semantic accuracy, cultural sensitivity, and ethical integrity in AI-driven knowledge organization.
Keywords
- Generative Artificial Intelligence (GAI)
- thesaurus construction
- prompt engineering
- synonym identification
- scope note development
In recent years, Generative Artificial Intelligence (GAI) has played an increasingly significant role in information processing and knowledge management. Powered by large language models (LLMs), GAI demonstrates strong capabilities in natural language processing, contextual text generation, and semantic reasoning, facilitating applications in multilingual translation, automated summarization, and content synthesis (Raiaan et al, 2024; Zhu et al, 2024). These developments have contributed to GAI’s growing adoption in interdisciplinary research, particularly within the social sciences and digital humanities (Bail, 2024; Dedema and Ma, 2024; Rane and Choudhary, 2024).
While GAI adoption continues to expand, its integration into Knowledge Organization Systems (KOS) remains a developing area. Thesauri, controlled vocabularies, and ontologies require precise semantic relationships, contextual depth, and cultural sensitivity—areas where AI presents both potential and limitations. Understanding how GAI can assist in KOS while addressing challenges such as accuracy, interpretability, and consistency is critical to improving its practical application in knowledge structuring and information retrieval.
The application of GAI in thesaurus construction presents both opportunities and challenges. Prompt engineering has emerged as a key technique for optimizing AI-generated outputs, particularly in areas such as controlled vocabulary development, semantic relationship identification, and metadata standardization (Chow et al, 2024; Hannah et al, 2025). Recent discussions at the Networked Knowledge Organization Systems (NKOS) Consolidated Workshop 2024, themed “KOS in AI & AI in KOS”, underscored AI’s potential to revolutionize knowledge organization systems (Busch, 2024; Networked Knowledge Organization Systems, 2024).
At the 2024 Getty International Terminology Working Group (ITWG) meeting, multiple presenters explored the application of generative AI in cultural heritage vocabularies. These included experiments involving Iconclass and iconographic metadata (Brandhorst, 2024), subject tagging for the Metropolitan Museum collection (Choi, 2024), and multilingual metadata enrichment (Zeng, 2024). In this context, the J. Paul Getty Research Institute (GRI), in collaboration with international partners, has spearheaded multilingual development of the Art and Architecture Thesaurus (AAT). The AAT-Taiwan project was the only initiative to apply generative AI directly to AAT’s editorial structures and bilingual translation workflows. This study builds on that preliminary work, first introduced at the 2024 ITWG meeting (Chen, 2024), by systematically evaluating prompt design strategies, AI-generated output quality, and human-AI collaboration in thesaurus construction.
This study examines a collaborative initiative between the Academia Sinica Center for Digital Cultures (ASCDC) and the Getty Research Institute (GRI) aimed at translating AAT into Chinese and incorporating culturally specific Chinese and Taiwanese concepts to AAT’s English edition. Researchers have proposed four alignment models for controlled vocabulary structures in Chinese and English (Chen et al, 2016) and developed systematic methodologies for thesaurus editing (Chen, 2021).
Building on this foundation, the study explores how GAI can enhance thesaurus construction, particularly in:
Using ChatGPT-4o (version gpt-4o-2024-08-06, hereafter AI; available at https://openai.com/chatgpt), the research investigates AI’s ability to assist in thesaurus contributions, specifically in constructing vocabulary relationships and drafting scope notes.
Among thesaurus relationships, equivalence relationships are fundamental to retrieval accuracy and consistency. Given the semantic and cultural complexities of equivalence relationships, they serve as ideal entry point for evaluating AI’s role in thesaurus development. This study addresses the following research questions:
RQ1: To what extent can AI identify and recommend equivalence relationships among vocabularies during thesaurus construction?
RQ2: How can Generative AI support and enhance scope notes drafting for localized vocabularies in thesauri?
Additionally, the study explores human-AI collaboration in vocabulary construction, assessing AI’s ability to improve efficiency while maintaining semantic integrity. Special emphasis is placed on prompt design and optimization, employing an iterative refinement process to enhance AI-generated outputs while minimizing manual intervention.
The findings offer empirical insights and a methodological framework for integrating AI into thesaurus development, with broader implications for digital humanities and knowledge organization systems.
Generative AI (GAI), powered by Large Language Models (LLMs), has revolutionized natural language processing, particularly in multilingual translation, semantic reasoning, and domain-specific knowledge organization. Brown et al. (2020) demonstrated that models like GPT-3 excel in few-shot learning, enabling task-specific adaptation without extensive training. These advancements provide a foundation for integrating GAI into Knowledge Organization Systems (KOS), particularly in thesaurus construction, where synonym identification and scope note drafting demand semantic precision and contextual awareness.
Existing research has explored LLM applications across diverse fields. Jauhiainen and Guerra (2024) examined LLM performance in semantic recognition and multilingual translation, emphasizing their capacity to handle linguistic and cultural diversity. Similarly, Ziems et al. (2024) assessed LLMs in computational social sciences, combining automated metrics with expert evaluations to measure relevance, fluency, and coherence in generated content. This study extends these studies insights by applying to KOS tasks, addressing challenges of multilingual and culturally nuanced vocabulary development.
LLMs are widely recognized for their text classification and generation capabilities, making them valuable in social sciences and digital humanities (Ziems et al, 2024). Their ability to analyze textual structures and uncover semantic patterns has facilitated research in history, linguistics, literature, psychology and sociology.
This study focuses on two core thesaurus construction tasks:
(1) Vocabulary relationship analysis
(2) Scope note drafting
These tasks align closely with LLM competencies in text structuring and content summarization. Prior studies have demonstrated how models like ChatGPT assist in preliminary diagnoses from radiology reports, underscoring their value in domains requiring semantic precision (Hu et al, 2024; Jauhiainen and Guerra, 2024; Ziems et al, 2024). LLMs have also been effective in semantic recognition, translation, linguistic analysis, and language prediction, supporting both vocabulary development and scope note generation (Chang et al, 2024; Jauhiainen and Guerra, 2024).
Despite these advancements, LLMs still face challenges in deep semantic analysis and cultural interpretation, reinforcing the need for human expertise in AI-assisted knowledge organization. Research suggests that human-AI collaboration enhances efficiency and reliability in text analysis, yet optimizing this synergy remains an open research question (Ziems et al, 2024). This study explores strategies for leveraging LLMs in thesaurus construction, focusing on vocabulary relationship analysis and scope note drafting.
Prompt engineering has emerged as a key methodology for optimizing the LLM performance in semantic reasoning, text generation, and multilingual applications. By bridging the gap between user intent and model output, structured prompts enable LLMs to generate precise and contextually relevant results, particularly in tasks requiring cultural and linguistic sensitivity (Brown et al, 2020; Marvin et al, 2024).
Recent study highlights the critical role of prompt design in improving accuracy and contextual alignment of AI-generated outputs. Sahoo et al. (2024) categorize prompt engineering techniques into zero-shot, few-shot, and chain-of-thought approaches, demonstrating how structured prompts—incorporating task objectives, semantic frameworks, and contextual examples—significantly enhance task performance. These insights provide a theoretical foundation for this study’s exploration of synonym identification and scope note drafting in thesaurus construction.
Building on this framework, the study integrates:
Building on this framework, the study integrates domain-specific instructions, contextual examples, and structured output formatting to enable LLMs to effectively handle nuanced cultural and semantic relationships. For example, chain-of-thought techniques applied in scope note drafting enhance the model’s ability to generate accurate and comprehensive content aligned with professional standards.
This iterative refinement process advocated by Sahoo et al. (2024) ensures continuous prompt optimization based on performance metrics and expert feedback, addressing the complexities of thesaurus construction.
Further, Meskó (2023) emphasize essential prompt components, including:
Ekin (2023) reinforces the importance of domain-specific knowledge, cultural nuances, and task customization for optimizing LLM-generated outputs in specialized fields. These insights directly inform this study’s approach to leveraging GAI for culturally nuanced thesaurus development.
Assessing the quality of LLM-generated content involves two primary methodologies:
(1) Automated evaluation metrics, such as BLEU, ROUGE-L, and METEOR, which measure form-based matching but often fail to capture semantic depth and contextual relevance.
(2) Human evaluation, which provide qualitative insights into practical usability and linguistic quality (Chang et al, 2024; Schuff et al, 2023; Ziems et al, 2024).
Chang et al. (2024) propose a systematic framework for evaluating LLMs, focusing on what to evaluate, where to evaluate, and how to evaluate. Building on the 3H principles (Helpfulness, Honesty, Harmlessness), they define six key evaluation dimensions: accuracy, relevance, fluency, transparency, safety, and human alignment. Ziems et al. (2024) further apply these evaluation criteria to assess 13 LLMs across 25 representative tasks in computational social science, highlighting the importance of metrics such as relevance, fluency, faithfulness, and coherence in evaluating generative tasks. The AAT Editorial Guidelines (Getty Research Institute, 2024) establish key criteria for scope note drafting, emphasizing clarity, simplicity, brevity, objectivity, and logical topic order. These guidelines serve as a foundational reference in thesaurus construction, ensuring consistency and usability in knowledge organization systems.
These guidelines inform the evaluation framework adopted in this research, integrates correctness, completeness, conciseness, fluency, and coherence as core evaluation metrics (see Table 1).
| Evaluation standard | Definition | References |
| Correctness | Accuracy and factual consistency, ensuring alignment with original sources and avoiding errors. | Accuracy (Chang et al, 2024); Consistency, Faithfulness (Ziems et al, 2024); Correctness (Hu et al, 2024); Clarifying Meaning (Getty Research Institute, 2024) |
| Completeness | Coverage of essential features, ensuring relevance and applicability. | Relevance (Chang et al, 2024; Ziems et al, 2024); Completeness (Hu et al, 2024); Additional Topics (Getty Research Institute, 2024) |
| Conciseness | Clarity and brevity, distinguishing the concept from similar terms. | Conciseness (Hu et al, 2024); Brevity (Getty Research Institute, 2024) |
| Fluency | Grammatical accuracy and readability. | Fluency (Chang et al, 2024; Ziems et al, 2024); Verisimilitude (Hu et al, 2024); Simplicity and Clarity (Getty Research Institute, 2024) |
| Coherence | Logical structure and thematic consistency. | Coherence (Ziems et al, 2024); Order of Topics (Getty Research Institute, 2024) |
While LLMs demonstrate proficiency in semantic analysis, their performance remains constrained by limitations in historical and cultural comprehension. For example, Ziems et al. (2024) highlight LLMs’ difficulty in capturing domain-specific subtleties without extensive contextual training. Similarly, Hu et al. (2024) emphasize challenges in synthesizing accurate content across diverse and complex datasets.
In thesaurus construction, these limitations are particularly evident in tasks requiring cultural judgments and semantic refinement. AI-generated outputs often require expert review to ensure accuracy and appropriateness. This study seeks to optimize human-AI collaboration, leveraging LLMs’ computational efficiency while maintaining the interpretive depth provided by human expertise.
This study employed the ChatGPT-4o model (version gpt-4o-2024-08-06) via OpenAI’s paid API platform. No fine-tuning or model retraining was conducted. All interactions relied on prompt engineering strategies, without additional corpus uploads or Retrieval-Augmented Generation (RAG) integration. While ChatGPT-4o demonstrates strong contextual generation capacity, its status as a proprietary, non-open-source model entails limitations on transparency and reproducibility. Usage was subject to token limits and availability restrictions of the API service.
This study examines 21 musical instrument concept terms used in the Confucius Ceremony at the Taipei Confucius Temple. Selection was guided by the principles of “literary warrant” and “cultural warrant” (Barité, 2018). Literary warrant ensures that terms are supported by historical and bibliographic evidence, while cultural warrant emphasizes their enduring significance within confucian ceremonial traditions. As an annual ritual with a 2500-year history, the Confucius Ceremony represents a cornerstone of Confucian cultural heritage, integrating tangible and intangible elements, such as musical instruments, ritual vessels, architectural spaces, and ceremonial practices. Consequently, the selected instruments represent both a specific classification within Confucian rituals and broader cultural and epistemological significance in musicology and heritage studies.
These instruments exemplify the traditional Chinese “Pa Yin” (Eight Sounds) classification system, reflecting their cultural specificity (Thrasher, 2000). Additionally, their alignment with the Hornbostel-Sachs Classification (H-S Classification) (Lee, 2020) and Western music classifications illustrates their cross-cultural relevance in global musicological frameworks (see Table 2). This dual validation—both cultural and scholarly—reinforces their role in multilingual and comparative knowledge organization. Despite their historical grounding, these terms have undergone semantic shifts and polysemic variations due to cultural transmission and evolving contexts. Some instruments are known by multiple names across different texts and traditions, complicating semantic analysis and vocabulary standardization, particularly in generative AI (GAI) applications. This study provides an empirical case to assess how GAI can address semantic variability and polysemy while upholding literary and cultural warrants principles.
| No. | Instrument Name | Pa Yin Classification (by material) | Hornbostel–Sachs Classification (by sound production) | Traditional Western Classification (by performance method) |
| 1 | Jin Gu (晉鼓, Large Barrel Drum) | Leather/Hide | Membranophone | Percussion |
| 2 | Jian Gu (建鼓, Central-Pillar Drum) | |||
| 3 | Ying Gu (應鼓, Small Central-Pillar Drum) | |||
| 4 | Bo Fu (搏拊, Barrel Drum,) | |||
| 5 | Tao Gu (鼗鼓, Rattle Drum) | |||
| 6 | Yong Zhong (鏞鐘, Grand Ritual Bell) | Metal | Idiophone | |
| 7 | Bo Zhong (鎛鐘, Tuned Ritual Bell) | |||
| 8 | Bianzhong (編鐘, Chime Bells) | |||
| 9 | Bian Qing (編磬, Chime Stones) | Stone | ||
| 10 | Te Qing (特磬, Single V-Shaped Stone Chime) | |||
| 11 | Zhu (柷, Ceremonial Sounding Box) | Wood | ||
| 12 | Yu (敔, Wooden Tiger) | |||
| 13 | Paiban (拍板, Clappers) | |||
| 14 | Qing (琴, Long Zithers with 7 Strings) | Silk | Chordophone | String |
| 15 | Se (瑟, Long Zithers with 25 Strings) | |||
| 16 | Dongxiao (洞簫, Vertical Bamboo Flute) | Bamboo | Aaerophone | Wind |
| 17 | Feng Xiao (鳳蕭, Phoenix Flute) | |||
| 18 | Dragon Blute (龍笛, Bamboo Transverse Flute) | |||
| 19 | Chi (篪, Bamboo Transverse Flute with Closed Ends) | |||
| 20 | Sheng (笙, Mouth Organ,) | Gourd | ||
| 21 | Xun (塤, Clay Ocarina) | Clay |
This study employs an iterative experimental design, focusing on synonym selection and scope note composition through human and Generative AI (GAI) collaboration. A structured 12-step framework guides the research process (see Fig. 1).
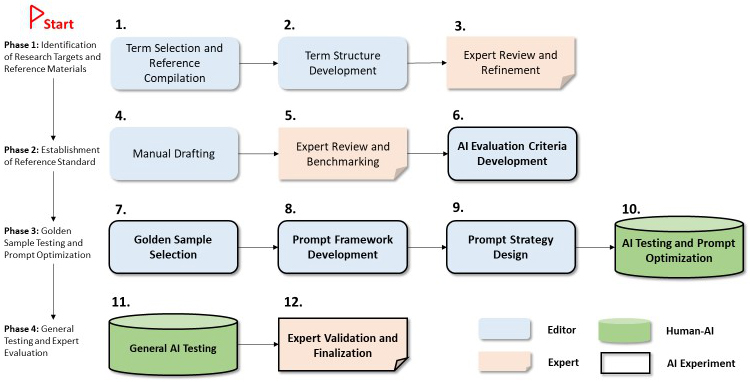 Fig. 1.
Fig. 1.
Workflow diagram for Artificial Intelligence (AI) experimental research.
The methodology consists of four stages:
(1) Target Identification & Reference Collection—Identifying research targets and compiling reference materials.
(2) Standard Development—Establishing reference standards for consistency.
(3) Gold Sample Testing & Prompt Optimization—Refining AI-generated content through benchmarking and iterative adjustments.
(4) General Testing & Expert Evaluation—Conducting large-scale validation and expert review to ensure accuracy.
The editorial team curates the reference materials, drafts content, and designs prompts, while domain experts review and refine scope notes to enhance precision. AI-assisted content generation supplements human expertise, optimizing efficiency while maintaining interpretive depth. Fig. 1 outlines the research framework, detailing the collaborative human-AI workflow across the four stages.
Step 1. Term Selection and Reference Compilation—Define research objectives and curate authoritative sources to establish a foundational term list.
Step 2. Term Structure Development—Construct a hierarchical framework to define term relationships and scope note parameters.
Step 3. Expert Review and Refinement—Domain Experts assess term structures, refine boundaries, and provide supplementary recommendations.
Step 4. Manual Drafting—Develop preliminary scope notes and identify synonyms for all 21 terms, based on authoritative references and editorial standards. This stage ensures that AI-generated content is benchmarked against expert-curated linguistic and conceptual definitions.
Step 5. Expert Review and Benchmarking—Experts evaluate and refine manually drafted scope notes and synonym lists, establishing gold standard reference benchmarks for AI-generated outputs.
Step 6. AI Evaluation Criteria Development—Define quantitative and qualitative (e.g., recall) and qualitative (e.g., correctness, fluency, coherence) assessment metrics to evaluate AI performance in synonym identification and scope note composition.
Step 7. Gold Sample Selection—Identify three representative musical instrument terms, ensuring diversity in type, hierarchy, and conceptual complexity for preliminary testing.
Step 8. Prompt Framework Development—Construct a structured six-element prompt framework to enhance content consistency and accuracy.
Step 9. Prompt Strategy Design—Develop various prompt strategies for synonym identification and scope note composition.
Step 10. AI Testing and Prompt Optimization—Conduct iterative testing to refine prompts, optimizing generation quality and identifying the most effective initial prompts.
Step 11. General AI Testing—Apply optimized prompts to the remaining 18 terms, assessing adaptability and refining them based on results.
Step 12. Expert Validation and Finalization—Experts review AI-generated outputs, providing feedback to confirm applicability and finalize the optimal prompts.
This structured methodological approach ensures a rigorous and systematic evaluation of AI’s role in thesaurus construction, balancing computational efficiency with expert validation to enhance multilingual knowledge organization.
Steps 6–11 constitute the core of the AI experimental framework, integrating structured prompt engineering with comprehensive evaluation metrics. Table 3 provides an overview of the AI research design.
| AI experimental steps (6–11) | Synonym identification | Scope note composition |
| Step 6. AI Evaluation Criteria Development | Establishes recall metrics to assess AI performance in identifying synonyms. | Defines five evaluation criteria: accuracy, completeness, conciseness, fluency, and coherence. |
| Step 7. Gold Sample Selection | Selects representative terms: Jian Gu (Centra-Pillar Drum), Paiban (Clapper), Dragon flute (Bamboo Transverse Flute). | Selects representative terms: Jin Gu (Large Barrel Drum), Bian Zhong (Chime Bells), Bian Qing (Chime Stones). |
| Step 8. Prompt Framework Development | Constructs a six-element structured prompt framework to enhance consistency and accuracy. | |
| Step 9. Prompt Strategy Optimization | Develops three optimized prompt strategies. | Develops five optimized prompt strategies. |
| Step 10. AI Testing and Iterative Refinement | Evaluates AI performance on gold samples using qualitative analysis and quantitative scoring, followed by iterative refinements. | |
| Step 11. General AI Testing | Applies optimized prompts to the remaining 18 terms to assess scalability and generalizability. | |
| Steps 12. Expert Evaluation and Suggestions | Domain experts assess AI-generated outputs, provide refinement feedback, and validate applicability. | |
Step 8 introduces a six-element prompt framework designed to mitigate issues such as randomness and hallucination in AI-generated outputs, thereby enhancing accuracy and consistency. This framework undergoes iterative refinement to achieve optimal performance (See Table 4). To ensure task specificity and synonym extraction consistency, each preferred term was explicitly embedded into the prompt as the central target of analysis. Rather than allowing the AI to infer targets implicitly, all 21 instrument terms were pre-defined as “Preferred Terms” based on expert-curated term lists and manually drafted scope notes (see Section 3.2.2). These terms were inserted into the “Instrument Term” variable in the prompt template, thereby anchoring the AI’s synonym identification process to a controlled vocabulary framework.
| Dimension | Component | Description |
| Task Design | Task Role | Assigns AI a specialized role to enhance task-specific focus, e.g., “You are an expert in the history of Chinese musical instruments used in the Confucius Ceremony.” |
| Task Context | Provides relevant background, e.g., “We need your assistance in developing the Chinese version of the AAT (Art & Architecture Thesaurus).” | |
| Task Goal | Defines the explicit objective, e.g., “Please review the following content and identify all synonyms for {instrument terms}.” | |
| Guidance Design | Instruction Rules | Specifies analytical methods, e.g., “Use the SPO (Subject-Predicate-Object) structure to identify synonyms.” |
| Instruction Examples | Provides structured examples of expected outputs, e.g., “The structure should follow: Instrument Term – Key Phrase used to identify synonym – Synonym of Instrument Term.” | |
| Instruction Format | Standardizes output presentation format, e.g., “Present results in a table with columns: ‘Instrument Term’, ‘Key Phrase for Synonym Identification’, ‘Synonym’ and ‘Original Sentence’.” |
A total of 21 terms were selected for this study, encompassing key musical instruments used in the Confucius Ceremony (see Table 2). Among them, three representative terms were used for gold sample testing to support prompt framework development and optimization. The remaining 18 terms were used in the general testing phase to evaluate the scalability and adaptability of the optimized strategies (see Table 3).
Building on the six-element prompt framework (Section 3.3.1), Prompt Strategy Optimization (Step 9) integrates three prompt strategies for synonym identification and five prompt strategies for scope note composition. These strategies provide a systematic framework for assessing AI performance in task execution, semantic accuracy, and output quality.
The Instruction Rules (see Table 4) serve as the foundation for these strategies, explicitly defining AI task execution procedures to enhance content accuracy, coherence, and contextual precision. The conceptual principles and technical features of each strategy are outlined below.
3.3.2.1 Synonyms Identification: Three Prompt Strategies
(1) Direct Synonym Identification (Zero-shot prompting)
(2) AAT-Assisted Synonym Identification (Context-aware prompting)
(3) SPO-Structured Synonym Identification (Extraction prompting)
3.3.2.2 Scope Notes Composition: Five Prompt Strategies
(1) Direct AI-Generated Scope Note Writing (Zero-shot prompting)
(2) AAT-Guided Scope Note Writing (In-context learning)
(3) Cluster-Based Scope Note Writing (One-shot prompting)
(4) AAT-Guided Scope Note Writing Based on Pustejovsky’s Qualia Structure (Stepwise Chain-of-thought Prompting)
(5) Cluster-Based AAT-Guided Scope Note Writing (Without Fixed Clustering Rules) (Hybrid approach)
To enhance reproducibility and transparency, this study includes two representative prompt examples that illustrate the practical application of the six-element prompt framework (see Table 4a and Table 4b). These examples correspond to the two most effective strategies identified during gold sample testing: (1) the SPO-Structured Synonym Identification Strategy, and (2) the AAT-Guided Scope Note Writing Strategy.
| Prompt component | Content |
| Task role | You are an expert in Chinese music history, specializing in instruments used in the Confucius Ceremony contexts. |
| Task context | You are assisting in constructing entries for the Art & Architecture Thesaurus (AAT). |
| Task goal | Please read the following text and identify all valid synonyms of the term Paiban. |
| Instruction rules | Instructions: |
| (1) Identify synonyms using the SPO structure. Each entry should follow the format: Instrument Term – Key Phrase used to identify synonym – Synonym. | |
| (2) For each synonym, specify the original sentence from the source text where the synonym was identified. | |
| Instruction example | Example Output: |
| Paiban – abbreviated as – Ban (板) | |
| Original sentence: “Paiban, abbreviated as Ban, is…” | |
| Output Format | Summarize the results in a table written in Traditional Chinese with the following columns: “Instrument Term”, “Key Phrase for Synonym Identification”, “Synonym”, and “Original Sentence”. |
SPO, Subject–Predicate–Object.
| Prompt component | Content |
| Task role | You are an expert in Chinese music history, specializing in instruments used in the Confucius Ceremony contexts. |
| Task context | You are contributing to the AAT and need to generate a culturally and historically accurate scope note. |
| Task goal | After reading the provided text, write a scope note in Traditional Chinese for the term Bianzhong, following the scope note rules listed below. |
| Instruction rules | Scope Note Rules: |
| Instruction example | (1) Correctness: Avoid overgeneralizations. Clarify the meaning by specifying historical periods and usage contexts. Indicate changes in meaning over time when relevant, and exclude uncertain or conflicting claims. Maintain a neutral and objective tone. |
| (2) Completeness: Describe the instrument’s distinguishing features, including form, material, and function. When applicable, suggest related or contrasting terms to guide users. | |
| Output format | The final scope note should be written in Traditional Chinese and limited to 150 characters. |
AAT, Art & Architecture Thesaurus.
To assess AI-generated results, manual evaluation is employed in Step 6. The evaluation team consists of two editorial experts specializing in library and information science and Chinese Literature, alongside a domain expert in Confucian ritual music. Compared to automated evaluation methods, manual assessment provides greater contextual sensitivity, particularly for text generation tasks, by offering nuanced and qualitative feedback (Chang et al, 2024; Ziems et al, 2024). The evaluation framework comprises two primary components:
(1) Recall-based evaluation for synonym identification.
(2) Qualitative assessment of scope notes composition.
3.3.3.1 Synonym Identification
The study evaluates AI’s accuracy in identifying core synonyms using a confusion matrix, with recall as the primary metric:
Where:
(1) TP (True Positive): Number of correctly identified synonyms.
(2) FN (False Negative): Number of core synonyms not identified by AI.
This quantitative metric ensures a systematic assessment of AI performance, focusing on completeness in synonym recognition while identifying areas requiring further refinement.
3.3.3.2 Scope Note Writing
To evaluate AI-generated scope notes, this study adopts five key evaluation criteria, drawn from prior studies (Chang et al, 2024; Hu et al, 2024; Ziems et al, 2024) and the AAT Editorial Guidelines (Getty Research Institute, 2024). A five-point Likert scale is applied, with the evaluation framework detailed in Table 5.
| Evaluation criteria | Guidelines |
| Correctness | Assesses whether the content accurately defines the term’s meaning, usage, and cultural/historical context. |
| Completeness | Evaluates coverage of key attributes, hierarchical relationships, and distinguishing characteristics. |
| Conciseness | Measures clarity and brevity (e.g., Chinese scope notes ideally within 150 characters), ensuring precision without excessive explanation. |
| Fluency | Examines grammatical accuracy and readability, avoiding technical jargon or self-referential definitions. |
| Coherence | Ensures logical structure, prioritizing general categories before specific attributes, usage, or historical relevance. |
This structured evaluation approach ensures AI-generated outputs align with professional standards, providing a robust framework for expert-informed refinements and enhancing thesaurus development.
The evaluation of AI-generated scope notes was carried out by a panel of three reviewers with expertise in thesaurus editing, multilingual terminology development, and cultural heritage documentation. The evaluation team consisted of the author and two members from the AAT-Taiwan editorial group. Each reviewer independently rated the AI-generated scope notes according to five criteria—accuracy, coverage, clarity, AAT editorial style alignment, and indexing usefulness—using a five-point Likert scale. Scores were aggregated to produce strategy-level means. Discrepancies among ratings were resolved through averaging, and the evaluation focused on identifying both strengths and areas for improvement in each prompt strategy.
The identification of equivalence relationships, particularly synonyms, is a fundamental aspect of thesaurus construction, ensuring semantic interoperability across linguistic and cultural contexts (ISO, 2011). In this study, AI’s role in synonym identification was assessed to determine its effectiveness in processing semantic nuances, a task traditionally dependent on human expertise.
To evaluate AI’s capacity for synonym identification, this study tested three prompting strategies, with results summarized in Table 6. The SPO-Structured Synonym Identification Strategy outperformed the other methods, achieving a 100% recall rate across all 21 target terms. For instance, AI accurately identified the semantic equivalence between Jian Gu (Central-Pillar Drum) and Ying Gu (Central-Pillar Drum, 楹鼓) by leveraging textual context to establish synonymy.
| Strategy | (1) Direct Synonym Identification | (2) AAT-Assisted Synonym Identification | (3) SPO-Structured Synonym Identification |
| Prompting technique | Zero-shot Prompting | Context-Aware Prompting | Extraction Prompting |
| Issue type | Core Synonyms Omission | Core Synonyms Omission | None |
| Recall score | (96/100) | (98.6/100) | ★ (100/100) |
Note: Recall values are calculated as TP/(TP+FN). TP, True Positive; FN, False Negative. ★ indicates the best-performing strategy with perfect recall (100%).
• Core Synonyms: Validated by domain experts.
• AAT-Assisted Synonym Definition: Relies on contextual information derived from AAT editorial guidelines to define synonym relationships (Getty Research Institute, 2024).
The high recall rate demonstrates AI’s potential in reducing omissions of core synonyms, making it a valuable tool for thesaurus construction.
These results highlight AI’s potential to reduce omissions in core synonym identification, enhancing thesaurus construction workflows. However, precision remains a challenge, as AI-generated outputs occasionally overgeneralized relationships, leading to false positives. This limitation aligns with broader challenges in semantic web theory, where AI tends to prioritize connectivity over precision in lexical relationships (Amini et al, 2024; Pinter and Eisenstein, 2018).
4.1.1.1 Performance Comparison of Synonym Identification Strategies
Table 6 summarizes the performance of three prompt strategies in identifying core synonyms across all 21 terms. A total of 100 core synonyms were validated by domain experts as the benchmark set. For each strategy, the AI-generated synonyms were compared against this reference list to determine true positives (TP) and false negatives (FN). Strategy 1 (Direct Synonym Identification) correctly identified 96 synonyms (TP = 96, FN = 4), yielding a recall score of 96.0%. Strategy 2 (AAT-Assisted Synonym Identification) achieved a recall of 98.6% (TP = 98.6, FN = 1.4) based on proportional evaluation across all test cases. Strategy 3 (SPO-Structured Synonym Identification) retrieved all 100 core synonyms (TP = 100, FN = 0), resulting in a perfect recall of 100%.
These recall values were calculated using the formula:
As this study focuses on synonym coverage, precision was not calculated due to the lack of systematically validated negative cases (see Section 4.1.1.3 for rationale).
Although the remaining 18 terms were reserved for general testing after the prompt optimization phase, recall was ultimately assessed across all 21 terms—including the 3 gold sample terms. This inclusive evaluation ensured consistency in comparing the performance of all prompt strategies, especially since the gold sample terms were also subjected to each strategy as part of benchmark analysis. Thus, the reported recall values in Table 6 reflect the aggregated results across the entire set of 21 terms.
The Direct Synonym Identification and AAT-Assisted Synonym Identification strategies exhibited omissions of core synonyms, while the SPO-Structured Synonym Identification method successfully retrieved all validated synonyms without omission.
4.1.1.2 Effectiveness of the SPO-Structured Synonym Identification Strategy
The SPO-Structured Synonym Identification Strategy demonstrated the highest effectiveness, capturing both direct equivalences and nuanced semantic relationships. Table 7 presents a practical example showcasing AI’s performance in identifying synonyms for Paiban (Clappers).
| Term | AI-identified synonyms | Core synonyms identified by domain experts | Recall (%) |
| Paiban (clappers) | Paiban (variant form) |
||
| Pai (abbreviation, 拍) |
|||
| Ban (abbreviation) |
|||
| Tanban (Sandalwood Clappers, 檀板) |
|||
| Chuo Ban (Clapper of Huang Fanchuo, 綽板) |
|||
| Du (Precursor to the Paiban, 牘) |
|||
| Chong Du (Ground-hit Du, 舂牘) |
|||
| Chalaqi (different linguistic origin, 察拉齊) – | – | ||
| Overall Recall | 100 | ||
Note: Recall calculation is based only on core synonyms.
– = Non-synonym (not considered in recall score).
The SPO framework significantly enhanced AI’s ability to capture hierarchical relationships, accurately mapping abbreviations, functional variations, and historical synonyms while avoiding excessive misclassifications. This structured approach demonstrates strong applicability in synonym detection, reinforcing AI’s role as a scalable tool for thesaurus construction.
4.1.1.3 Structured Synonym Extraction Using the SPO Framework
To enhance synonym identification accuracy and minimize omissions, this study applied the Subject-Predicate-Object (SPO) framework as a structured approach for AI-driven synonym extraction. The SPO framework provides a systematic method for guiding AI in detecting and mapping semantic relationships with high precision. By structuring synonym extraction into a fixed Term-Key Phrase-Synonym format, this method ensures consistency and reduces ambiguities in AI-generated outputs.
Table 8 presents an example of how the SPO framework facilitated structured synonym identification, demonstrating AI’s ability to accurately extract semantic equivalences.
| Term | Key phrase | Synonym | Original sentence |
| Paiban (Clappers) | abbreviated as, referred to as | Ban, Tanban (sandalwood clappers) | “Paiban, abbreviated as Ban, is commonly made of sandalwood and is also referred to as Tanban.” |
By explicitly defining subject-verb-object relationships, the SPO framework enhances semantic extraction by enabling AI to:
4.1.1.4 Key Findings
The SPO-Structured Synonym Identification strategy demonstrated superior performance, achieving perfect recall (100%) with precise and semantic consistency. Compared to other prompting techniques, this structured approach provides a scalable and reliable solution for synonym identification in thesauri development.
Key advantages of the SPO framework include:
Given these strengths, the SPO approach presents significant potential for improving synonym identification in thesaurus construction, addressing key challenges related to lexical variability, historical terminology shifts, and concept mapping.
While recall was adopted as the primary metric for evaluating synonym identification in this study, precision was not calculated due to the lack of reliable ground truth data on false positives (i.e., non-synonymous terms incorrectly identified as synonyms by AI). Given the historical and culturally nuanced nature of the terminology, establishing a definitive set of non-synonyms proved challenging and potentially subjective. In such contexts, recall provides a more stable measure of the AI’s ability to identify expected core synonyms. Nevertheless, future research should incorporate precision and F1-score measures where annotated datasets allow for the systematic identification of false positives in lexicographic tasks. This limitation highlights the importance of future work in building more robust evaluation datasets tailored for culturally embedded and historically complex terminologies.
The results reported in Table 6 are based on an exhaustive evaluation of a fixed set of 100 expert-validated core synonyms and are not derived from probabilistic sampling. As such, no statistical significance testing was performed (e.g., p-values), since the comparison was descriptive in nature and included the entire dataset. Future research may apply inferential methods such as bootstrapping or cross-domain replication to examine the robustness and generalizability of prompt strategies.
AI demonstrated an advanced ability to identify potential synonyms that extend beyond those recognized by human editorial teams. Notably, the model identified “Du” as a synonym for “Paiban”, a relationship that was later validated by domain experts. This finding underscore AI’s potential in uncovering latent semantic relationships, thereby addressing key limitations in manual thesaurus construction, particularly in historical lexicons.
The AI’s semantic expansion capability is primarily driven by two key mechanisms within generative AI models:
(1) Contextual Embeddings
(2) Self-Attention Mechanism (Transformer Architecture)
(3) Probabilistic Modeling and Co-Occurrence Analysis
However, semantic expansion carries inherent risks, including overgeneralization and misinterpretation of culturally or historically specific terms. These challenges arise due to the lack of nuanced historical and cultural knowledge in AI’s training data. To mitigate these risks, expert validation remains indispensable. By integrating AI’s computational efficiency with expert-driven review and refinement, thesaurus construction can be enhanced to ensure semantic precision and cultural accuracy.
Scope notes play a crucial role in defining and contextualizing terms within thesauri, particularly when addressing localized vocabularies. They ensure semantic clarity, standardization, and cross-cultural consistency, making them highly beneficial for knowledge organization systems (KOS), particularly those requiring precise term definitions and contextual clarity. This study demonstrates that structured prompting strategies significantly enhance the quality of AI-generated scope notes, improving accuracy, depth, and coherence while aligning outputs with professional editorial standards.
The quality of AI-generated scope notes was assessed using five evaluation criteria: correctness, completeness, conciseness, fluency, and coherence, with a maximum score of 5 per criterion. The results underscore the critical role of prompt design in determining output quality (Table 9).
| Strategy number | 1 | 2 | 3 | 4 | 5 |
| Strategy name | Direct AI-Generated Scope Note Writing | AAT-Guided Scope Note Writing | Cluster-Based Scope Note Writing | AAT-Guided Scope Note Writing Based on Pustejovsky’s Qualia Structure | Cluster-Based AAT-Guided Scope Note Writing without Fixed Clustering Rules |
| Prompting techniques | Zero-Shot Prompting | In-Context Learning Prompting | One-Shot Prompting | Few-Shot Prompting + Chain of Thought (CoT) | One-Shot Prompting + Chain of Thought (CoT) |
| Issue type | Lack of Correctness and Completeness | None | Lack of Completeness and Fluency | None | Lack of Completeness |
| Rating | (20/25) | ★ (25/25) | (21.3/25) | ★ (25/25) | (23/25) |
Five-point Likert scale across five criteria: correctness, completeness, conciseness, fluency, and coherence; max score = 25.
Note: ★ indicates the best-performing strategies (both Strategy 2 and Strategy 4 achieved 25/25).
Scores are calculated on a five-point Likert scale across five criteria (correctness, completeness, conciseness, fluency, and coherence), with a maximum total of 25.
Among the five tested prompting strategies, Strategy 2 (AAT-Guided Scope Note Writing) and Strategy 4 (AAT-Guided Scope Note Writing Based on Pustejovsky’s Qualia Structure) achieved the highest performance, effectively capturing essential conceptual features while producing detailed, contextually rich scope notes.
Table 9a provides a detailed comparison of evaluation scores across five prompt strategies. Each AI-generated scope note was rated by three expert editors based on five criteria: (1) accuracy of definition, (2) coverage of semantic components, (3) clarity and readability, (4) alignment with AAT editorial style, and (5) usefulness for indexing. This breakdown enables cross-strategy comparison and highlights the relative strengths of each prompt design.
| Strategy Number and Prompt Strategy | Evaluation Criterion | |||||
| Correctness | Completeness | Conciseness | Fluency | Coherence | Total | |
| Strategy 1: Zero-Shot Prompting | 3.3 | 2.7 | 5 | 4 | 5 | 20 |
| Strategy 2: In-Context Learning Prompting | 5 | 5 | 5 | 5 | 5 | 25 |
| Strategy 3: One-Shot Prompting | 4.3 | 3.3 | 5 | 3.7 | 5 | 21.3 |
| Strategy 4: Few-Shot Prompting + Chain of Thought (CoT) | 5 | 5 | 5 | 5 | 5 | 25 |
| Strategy 5: One-Shot Prompting + Chain of Thought (CoT) | 5 | 3.7 | 5 | 4.3 | 5 | 23 |
Five-point Likert scale; n = [number of terms]
4.2.1.1 Strategy 2 AAT-Guided Scope Note Writing
To illustrate the effectiveness of AAT-Guided Scope Note Writing (Strategy 2), this study examined AI-generated descriptions for Bianzhong (Chime Bells), an ancient Chinese musical instrument. The initial AI-generated scope note lacked essential details, failing to capture the instrument’s material composition, structural arrangement, ritual function, and historical significance.
However, when AAT editorial guidelines were integrated into AI prompting, the scope note significantly improved. The AI correctly identified that Bianzhong (Chime Bells) is:
Conversely, Strategy 1 (Direct AI-Generated Scope Note Writing) performed poorly due to the absence of contextual support, resulting in deficiencies in correctness and completeness. While Strategies 3 and 5 showed moderate improvement, they still exhibited issues with completeness and fluency (see Table 10).
 |
| Note. From Pyeonjong by ChaiCat, 2015, Wikimedia Commons. CC BY-SA 4.0. |
| The “bianzhong” is an ancient Chinese bronze percussion instrument, first appearing in the Shang Dynasty and reaching its peak during the Western Zhou and the Spring and Autumn Warring States periods. It consists of multiple bells of varying shapes and sizes, each producing a specific pitch. A typical set includes 16 bells. The bianzhong was primarily used in court music, symbolizing the ruler’s authority and status, and it was played during rituals, banquets, and significant ceremonies. Its design evolved over time, from flat and oval shapes to round ones, and featured different decorative patterns. In Confucian Ceremony, the bianzhong was struck at the beginning of each musical phrase to lead the orchestra in unison. (This scope note was originally written in Chinese and has been translated into English for publication.) |
Note: This scope note was originally generated in Chinese by ChatGPT-4o using Strategy 2 (AAT-Guided Scope Note Writing) and has been translated into English by the author for publication. The accompanying image is sourced from Wikimedia Commons and is credited accordingly.
4.2.1.2 Findings and Implications
The AAT-Guided Scope Note Writing strategy proved highly effective for professional thesaurus applications. By integrating structured prompts with AAT editorial guidelines, AI-generated scope notes provided comprehensive coverage of materials, usage, and historical evolution.
For instance, this strategy enabled AI to describe the transformation of Bianzhong (Chime Bells) from flat to round shapes over time, offering users a cohesive historical overview. These findings underscore the importance of structured prompts in enhancing AI-generated scope notes, making them more contextually accurate and semantically rich for knowledge organization and thesauri development.
Strategy 4 (Pustejovsky-Guided Strategy) further enriched scope notes by incorporating Pustejovsky’s Qualia Structure framework alongside Chain of Thought (CoT) prompting. The Qualia Structure categorizes an entity’s attributes into four foundational roles:
(1) Form (Formal Role): Defines an object’s intrinsic properties.
(2) Constitution (Constitutive Role): Specifies materials and physical composition.
(3) Agentive (Causal Origin): Explains how an object was created.
(4) Telic (Purpose or Function): Describes its intended use or practical function.
This structured approach enabled AI to systematically analyze and describe objects, producing cohesive and semantically rich scope notes that balances theoretical rigor and practical application. For instance, when describing Bianzhong (Chime Bells), this strategy emphasized intricate details such as the double dragon handle and cloud-dragon pattern, enriching the scope note with cultural and visual depth. The attribute-based organization allowed the AI to systematically group related details, resulting in scope notes that are particularly suited for visualization and interpretive needs.
These findings align with Frame Semantics (Fillmore and Baker, 2009; Fillmore, 2006) demonstrating that AI can utilize structured conceptual frameworks to generate semantically complex content. The attribute-based grouping further enhances the systematic presentation of scope note details, making this approach ideal for contexts that prioritize visual and interpretative depth.
In summary, AAT-Guided Scope Note Writing is well-suited for professional reference and systematic applications, while the Pustejovsky-Guided Strategy excels in educational and interpretive scenarios. Future applications should adapt these strategies based on the specific requirements of the use case, combining prompt design with expert review to optimize the practical utility of AI-generated scope notes.
4.2.3.1 Use Cases for Two Key Prompt Strategies
Findings indicate that Strategy 2 (AAT-Guided Scope Note Writing) and Strategy 4 (Pustejovsky-Guided Scope Note Writing) offer distinct advantages, each tailored to different application contexts.
By applying these strategies in domain-specific contexts, AI-generated scope notes can be adapted to meet varied user needs, ensuring both semantic precision and interpretive richness in thesaurus development.
4.2.3.2 Challenges of Accuracy and Completeness
Despite notable advancements, accuracy and completeness remain persistent challenges in AI-generated scope notes. These limitations primarily stem from:
These challenges underscore AI’s limitations in contextual interpretation and recognizing cultural nuances in thesaurus construction.
Accuracy Challenges
AI often struggles with historical contexts recognition, leading to misinterpretations in scope notes. For example, when describing the Bianzhong (Chime Bells) instrument, AI oversimplified scholarly debate by exclusively attributing its origin to the Western Zhou Dynasty, failing to acknowledge alternative historical interpretations. This lack of contextual sensitivity highlights AI’s limitations in navigating complex historical narratives and scholarly discourse.
Completeness Challenges
AI frequently omitted key attributes, resulting in incomplete outputs. For instance, its initial description of Bianqing (Chime Stones) failed to include information on its material composition, a crucial detail for understanding the artifact. Such omissions reflect AI’s difficulty in capturing the multidimensional characteristics of cultural objects. As illustrated in Table 10, the scope note generated by Strategy 2 demonstrates basic structural coherence but also reveals issues such as incomplete contextual anchoring and semantic overgeneralization, particularly in expressing the ritual function of the instrument.
These findings reveal AI’s dependency on prompt design and the data quality of underlying data. Despite iterative refinements, AI remains limited by dataset insufficiencies and lacks the contextual reasoning necessary for historical and cross-cultural knowledge representation. Expert review is therefore indispensable in bridging these gaps and ensuring AI-generated content meets professional standards. Future research should focus on integrating contextual and cultural frameworks into AI models to improve the accuracy and relevance of scope notes, ensuring AI can better handle historical and domain-specific complexities.
4.2.3.3 Prompt Design as a Mitigation Strategy
To address accuracy and completeness issues, this study incorporated AAT guidelines into prompt design, establishing explicit rules to enhance AI-generated outputs. Key measures included:
• Accuracy: avoid overgeneralization, specify the temporal and functional context of terms, and exclude ambiguous or conflicting information.
• Completeness: critical attributes (e.g., material, appearance, function) are included while guiding users to related terms when necessary.
By embedding these rules into prompt design, the study achieved notable improvements in both accuracy and completeness. The structured framework not only enhanced the quality of the AI-generated scope notes but also ensured alignment with professional standards, effectively addressing the challenges observed during experimentation.
4.2.3.4 Definition Misalignment With Scope Note Standards
While the AI-generated scope notes generally followed the prompt instructions based on AAT editorial guidelines, they may not fully conform to the formal definition of Scope Notes in ISO 25964 or the Getty editorial framework. In several cases, the generated outputs resembled descriptive entries or encyclopedic definitions rather than precise thesaurus notes. These outputs often lacked disambiguation cues, boundaries of use, or term usage guidance—elements essential to thesaurus editorial control. This limitation highlights the challenge of translating implicit editorial judgment into AI prompting strategies. Future iterations of the workflow may incorporate annotated training examples, expert-in-the-loop feedback, or prompt chaining techniques to ensure that outputs better meet thesaurus-level standards.
AI demonstrates limitations in handling cultural and historical contexts in scope notes generation. For instance, in its initial description of the Bianqing (Chime Stones) instrument, the AI omitted critical details such as material and appearance. However, after expert review and prompt optimization, the quality of the generated content improved significantly. These findings reaffirm the indispensable role of expert knowledge in enhancing the accuracy and depth of AI-generated scope notes, particularly when addressing tasks involving cultural and historical intricacies.
This study demonstrates that Generative AI, guided by structured prompts and expert collaboration, can effectively identify equivalence relationships and generate high-quality scope notes. AI enhances editorial efficiency by uncovering latent semantic relationships and producing knowledge representations that align with professional frameworks. However, AI’s precision in addressing cultural and contextual nuances still requires expert review and validation. Future research should explore automated evaluation methods and expand Generative AI’s applicability across interdisciplinary and multilingual domains to enhance scalability and accuracy.
This section examines the comparative performance of AI and editorial teams in synonym identification, emphasizing AI’s complementary role in supporting human editors and its potential in semantic expansion.
To assess the accuracy and relevance of AI-generated results, this study established three comparative benchmarks:
(1) AI- Identified Synonyms: Synonyms generated by AI based on its internal semantic models.
(2) Core Synonyms Confirmed by the Editorial Team: Synonyms validated against existing literature and editorial expertise.
(3) Synonyms Verified Through Domain Experts Review: Synonyms confirmed by domain experts as definitive references.
Findings indicate that AI can reliably identify core synonyms while also uncovering additional latent synonyms not initially recognized through manual editorial processes. For instance, AI identified Du (Precursor to the Paiban) as a synonym for Paiban (Clappers) revealing its capacity to detect broad semantic relationships. These results suggest that AI’s internal semantic modelling can uncover meaningful connections that merit further expert validation, providing new avenues for refining editorial workflows and advancing semantic expansion research.
Based on expert evaluations, the AI-identified synonyms were categorized into
four distinct types (See Table 11). Symbols used in Table 11 include:
| Term | AI-identified synonyms | Core synonyms identified by the editorial team | Core synonyms identified by the domain expert | AI-identified potential synonyms (confirmed by experts) |
| Paiban (clappers) | Paiban (variant form) | ○ | ||
| Pai (abbreviation) | ○ | |||
| Ban (abbreviation) | ○ | |||
| Tanban (sandalwood clappers) | ○ | |||
| Chuo Ban (clapper of Huang Fanchuo) | ○ | |||
| Du (Precursor to the Paiban) | ○ | Du (Precursor to the Paiban) | ||
| Chong Du (ground-hit Du) | Chong Du (ground-hit Du) | |||
| Chalaqi (different linguistic origin) | ○ | – | ||
| Dongxiao (vertical bamboo flute) | Chiba (尺八, Precursor to the Dongxiao) | ○ | ||
| Xiao (簫, abbreviation) | Xiao (abbreviation,) | |||
| Di (transverse flute) | – | |||
| Di (篴, variant form of 笛) | – |
Note:
(1) All AI-Identified Synonyms: Encompasses all potential synonyms generated by AI, reflecting its broad semantic interpretation capabilities.
(2) Editorially Confirmed Synonyms: Synonyms validated by the editorial team based on established standards and literature.
(3) Expert-Verified Synonyms: Synonyms confirmed through domain expert review, serving as a definitive benchmark.
(4) Latent Synonyms Identified by AI (Validated by Experts): Synonyms initially flagged by AI but uncertain for editorial teams, later confirmed as valid through expert review.
The comparative analysis in Table 11 provides critical insights into AI’s role in synonym identification, highlighting both its capabilities and limitations.
(1) Semantic Breadth
AI demonstrated a robust ability to identify semantically related terms, in some cases detecting a broader range of potential synonyms than those traditionally recognized by human editors. This underscores AI’s potential to extend beyond conventional lexicons, offering an expansive semantic interpretation. However, AI’ limitations in contextual comprehension, sensitivity to historical-cultural nuances, and precision in managing subtle semantic distinctions frequently lead to misinterpretations or semantic ambiguity.
(2) Uncovering Potential Overlooked Synonyms
AI successfully identified potential synonyms that were later validated by domain experts, as indicated in the “AI-Identified Potential Synonyms” column in Table 11. This ability to surface latent semantic relationships highlights AI’s utility in enriching synonym databases, particularly in specialized knowledge domain where manual identification may be constrained by cognitive or editorial biases.
(3) Human-AI Collaborative Model for Synonym Expansion
AI’s capacity to uncover latent semantic relationships that may not be immediately evident to human editors presents a significant advantage. However, expert validation remains indispensable for ensuring linguistic precision, historical integrity, and cultural relevance. This synergy between AI’s computational efficiency and human expertise offers a promising framework for refining synonym identification. By integrating automated discovery with expert oversight, this human-AI collaborative model balances scalability and accuracy, effectively addressing the limitations of both AI and manual editorial processes when used in isolation.
While AI-generated outputs provide valuable contributions to editorial workflows, expert review remains essential to refining results, resolving contextual inconsistencies, and ensuring semantic rigor. This collaborative approach not only enhances the reliability of synonym identification but also broadens the scope of AI applications in Knowledge organization systems. Future research should further explore how AI-driven synonym discovery can be systematically integrated into editorial processes to enhance efficiency while maintaining the highest standards of scholarly accuracy.
While AI demonstrates significant potential for semantic discovery, particularly in synonym identification, it faces notable challenges in handling historical contexts, domain-specific terminology, and nuanced semantic distinctions. This section categorizes the primary challenges (summarized in Table 12) and proposes corresponding mitigation strategies to improve AI’s performance in synonym identification.
| Category | Description | Example |
| A. Conceptual Confusion | AI conflates functionally distinct terms as synonyms. | Jin Gu (large barrel drum) – Jian Gu (central-pillar drum) |
| B. Semantic Ambiguities | AI overgeneralizes related hierarchical terms. | Sheng (mouth organ) – Chao Sheng, He Sheng |
| C. Rare Terms | AI lacks sufficient data for obscure terminology. | Paiban (clappers) – Chalaqi |
| D. Attribute Misreading | AI misinterprets attributes or pitch names as entire objects. | Bo Zhong (ritual bell) – Nan Lü (specific pitch) |
(A) Conceptual Confusion
AI occasionally misidentifies distinct concepts as synonymous, conflating terms that serve different functional or contextual roles.
• Example: Jin Gu (large barrel drum) and Jian Gu (central-pillar drum) were erroneously classified as synonyms despite their differing functions and structural designs.
• Cause: These misinterpretations often stem from conflicting historical documentation or misalignment between primary data sources and expert perspectives.
• Mitigation Strategy: expert review is essential to verify and correct misidentified synonyms, ensuring conceptual clarity and precision.
(B) Ambiguities in Semantic Hierarchies
AI often fails to distinguish between general categories, coordinate terms, and precise object references, leading to overgeneralized semantic interpretations.
• Example: Sheng (苼, Mouth Organ) was inaccurately generalized to include Chao Sheng (巢笙, Multi-Reed Sheng) and He Sheng (和苼, Single-Reed Sheng), despite their distinct forms, structures and acoustic properties.
• Cause: AI lacks robust hierarchical frameworks to differentiate related but non-equivalent terms.
• Mitigation Strategy: Integrating structured semantic hierarchies into AI prompt design, coupled with expert validation, can refine AI’s handling of taxonomic distinctions.
(C) Lack of Support for Rare or Obscure Terms
AI encounters difficulties in identifying rare or under-documented terms, leading to either omissions or incorrect synonym pairings.
• Example: AI paired of Paiban (Clappers) and Chalaqi (different linguistic origin), an obscure foreign term with insufficient historical documentation to confirm semantic similarity.
• Cause: Limited corpus diversity results in erroneous classifications for poorly documented terms.
• Mitigation Strategy: AI prompts should explicitly exclude poorly documented terms to minimize false positives, and specialized corpora should be integrated to support rare terminology identification.
(D) Misinterpretation of Nomenclature or Functional Components
AI occasionally misreads terminology referring to specific attributes (e.g., pitch, components) as full synonyms of the instruments.
• Example: Bo Zhong (Hollow Ritual Bell) was mistakenly associated with with Nan Lü (南呂鐘, a specific pitch position), a term referring only to a specific pitch in the Chinese Twelve-Lü Tuning System, not to a bell itself.
• Cause: AI lacks the ability to differentiate whole objects from their specific attributes, leading to misinterpretations in specialized domains.
• Mitigation Strategy: Linking AI models to domain-specific databases and ontologies can improve the precision of terminology recognition.
While AI demonstrates strong capabilities in synonym discovery, including identifying latent relationships and generating broad synonym suggestions, it struggles with context sensitivity, historical accuracy, and semantic granularity. To address these limitations, a hybrid human-AI model is essential:
(1) AI can efficiently detect potential synonym relationships at scale.
(2) Human experts must validate and refine AI-generated outputs to ensure linguistic, historical, and cultural precision.
(3) Integrating structured ontologies or other formalized knowledge organization systems (KOS)—such as faceted thesauri like the AAT—along with domain-specific corpora and expert-driven quality control mechanisms, will enhance AI’s ability to process domain-specific terminology accurately.
This synergistic approach—leveraging AI’s computational efficiency while maintaining expert oversight—offers a viable framework for thesaurus construction, ensuring both scalability and precision in knowledge organization.
This study focuses specifically on the methodological design and evaluation of generative AI for thesaurus-related tasks, particularly synonym identification and scope note composition. Broader social, ethical, or environmental implications of generative AI—such as bias, carbon footprint, or data privacy—are recognized as important but fall outside the scope of this research. These concerns merit future interdisciplinary exploration, particularly in relation to long-term infrastructure integration in cultural heritage and knowledge organization systems.
In addition to methodological and contextual limitations, the issue of cost-effectiveness also warrants further investigation. While generative AI tools may offer notable productivity gains, their effective use often requires human oversight, iterative prompt refinement, and editorial validation—all of which entail labor, time, and potential funding investment. For smaller projects with limited resources, the benefits of AI integration may not always outweigh these overheads. However, as prompting techniques and AI models become more user-friendly and domain-aligned, the balance between human effort and AI augmentation may shift toward greater efficiency. Evaluating cost-effectiveness across different project scales remains an important area for future applied research.
This study demonstrates that Generative AI (GAI), when guided by structured prompting and expert collaboration, can effectively identify core synonyms and generate high-quality scope notes, offering substantial potential for thesaurus construction. While GAI enhances editorial efficiency and scalability, contextual and cultural challenges persist, necessitating expert validation and refined prompt engineering to ensure semantic accuracy, historical relevance, and knowledge integrity.
(1) AI’s Synonym Identification Capabilities
AI can rapidly and accurately identify core synonyms and uncover latent semantic relationships beyond traditional manual editing. However, expert validation remains indispensable for ensuring historical accuracy, contextual appropriateness, and terminological precision, reinforcing the importance of a human-AI collaborative approach.
(2) AI’s Contribution to Scope Note Drafting
With structured prompting, AI can generate professionally structured scope notes aligned with domain-specific frameworks. The AAT-Guided approach excels in professional database-oriented applications, while the Pustejovsky-Guided method enhances interpretive and educational use cases.
(3) Challenges in Contextual and Cultural Understanding
AI struggles with historical languages, cultural nuances, and complex semantic hierarchies, limiting its ability to fully capture domain-specific contexts. These challenges highlight the need for comprehensive datasets, expert intervention, and refined prompting techniques to enhance accuracy and contextual depth.
(4) Importance of Structured Prompt Design
AI performance hinges on structured prompts that define task roles, contextual background, clear objectives, and explicit instruction rules. A well-defined prompt structure significantly improves accuracy, completeness, and consistency in AI-generated outputs.
Building on these findings, the next section outlines key areas for future research to enhance AI’s applicability across diverse domains and knowledge systems.
Future research should focus on enhancing AI’s applicability in multilingual, culturally nuanced, and domain-specific thesauri development. Five key areas warrant further investigation:
(1) Expanding AI’s Applicability in Historical and Multilingual Contexts
Refining workflows strategies for vocabulary translation and localization is essential, particularly for culturally embedded knowledge systems, such as Confucian ceremonial terminology. AI-driven methods must balance linguistic precision and cultural fidelity, ensuring that historical meanings are preserved while facilitating cross-linguistic knowledge representation.
Future research should also test AI’s adaptability in other historical lexicons, including:
These case studies will help determine AI’s effectiveness in handling historically and contextually grounded synonym identification.
(2) Enhancing Human-AI Collaboration in Knowledge Organization
Effective human-AI collaboration remains crucial in ensuring semantic precision, contextual appropriateness, and cross-cultural validity. Future research should focus on:
Investigating these methodologies will optimize AI’s role as an assistive tool, rather than a replacement for expert-driven lexicographic practices.
(3) Investigating AI’s Domain Adaptability and Generalizability
While this study focuses on Confucian ceremonial vocabulary, future research should assess whether AI-driven thesaurus construction models are transferable across disciplines. Comparative studies should explore AI’s performance in:
By conducting cross-domain evaluations, future studies can determine AI’s scalability, adaptability, and impact in diverse knowledge organization systems (KOS).
(4) Advancing Evaluation Metrics for AI-Generated Thesauri
Current evaluation frameworks rely heavily on expert review to validate AI-generated synonym identification and scope note generation. Future research should explore automated evaluation methodologies, such as machine learning-based consistency checks, knowledge graph embeddings, and explainable AI (XAI) techniques, to reduce reliance on manual assessments while maintaining scalability and interpretability.
(5) Comparative Analysis of Language Models in Thesaurus Construction
Investigating alternative AI models, such as Gemini, Claude, and Copilot, could provide insights into their effectiveness in synonym identification and scope note generation across varying linguistic and cultural settings. Future studies should conduct benchmarking experiments to assess which models best capture semantic nuance, hierarchical relationships, and domain-specific terminologies. Evaluate AI’s interpretability and explainability, ensuring greater alignment with thesaurus construction best practices. By addressing these research directions, AI-assisted thesaurus construction can evolve into a scalable, cross-disciplinary, and culturally inclusive approach to knowledge organization and multilingual lexicography.
This study focused on Confucian ceremonial instruments as a case study but did not explore the detailed mapping of Chinese-English terms within the AAT framework. This remains a promising avenue for future research, with the potential to optimize multilingual thesauri construction and further enhance AI’s role in knowledge organization.
While this study demonstrates the potential of Generative AI in thesaurus development, several ethical concerns must be addressed to ensure responsible AI integration in knowledge organization.
(1) Bias in AI-Generated Lexical Relationships
AI’s reliance on pre-trained language models introduces inherent biases. If historical terminology is underrepresented in training data, AI may favor modern language conventions, leading to semantic distortions. This raises ethical concerns regarding the fair representation of historically and culturally significant terminologies.
(2) Cultural Sensitivity and Knowledge Equity
The application of AI in Confucian ritual terminologies necessitates a culturally aware and historically precise approach. AI’s tendency to generalize across different temporal and linguistic contexts could lead to cultural appropriation or misrepresentation of ritual practices. Future work should explore incorporating ethically curated multilingual corpora to enhance cultural inclusivity.
(3) Transparency and Explainability in AI-Assisted Thesaurus Construction
In AI-assisted thesaurus development, transparency is essential to ensure expert validation and maintain scholarly rigor. Users and domain experts should be able to trace AI’s reasoning in synonym identification and scope note generation, allowing for systematic evaluation and refinement. Implementing explainable AI (XAI) mechanisms or structured logging of AI-generated suggestions would enhance expert oversight, facilitate interpretability, and support the iterative human-AI collaboration process (Ali et al, 2023; Kale et al, 2023).
(4) Human Oversight and Interpretive Authority
AI should complement, not replace, expert-driven lexicographic practices. This study reinforces the importance of human-AI collaboration as a safeguard against misinformation and semantic drift.
All essential data and materials supporting the conclusions of this paper will be made available by the corresponding author upon reasonable request. Some raw AI-generated outputs and intermediate files may be provided in part, depending on feasibility and data use restrictions.
SJC confirms sole responsibility for the conception and design of the study, data collection, analysis and interpretation, drafting and revising the manuscript, and approval of the final version. The author has read and approved the final manuscript and agrees to be accountable for all aspects of the work.
The author would like to thank Prof. Ping-heng Tsai for his helpful advice on the history of Chinese music in this paper, and Mr. Jeng-shiun Wang, Miss Yin-rong Wang, Miss Yi-yun Lee and Ms Hung-ying Chen for their assistance throughout the project.
The work was supported by the Academia Sinica Center for Digital Cultures (Grant No. ASCDC-1137-007), and the Ministry of Science and Technology (Grant No. NSTC 112-2410-H-001 -009 -MY2).
The author declares no conflict of interest.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.