
 , Atefeh Sharif 1,*
, Atefeh Sharif 1,* , Fatemeh Zandian 1
, Fatemeh Zandian 11 Department of Knowledge & Information Science, Faculty of Management and Economics, Tarbiat Modares University, 14115-111 Tehran, Iran
Abstract
This paper examines the rate of linkage between Persian Subject Headings (PSH) and comparable datasets, including subject heading services and other topical datasets, and identifies the barriers to linking datasets. Using Linked Data methodologies, the study applies data cleaning and Resource Description Framework (RDF) conversion, employing both direct and indirect linking approaches. Under the direct method, PSH terms were matched against external topical datasets, achieving a linkage rate of 50%. The indirect method, which utilized the Library of Congress Subject Headings (LCSH) as an intermediary, achieved a lower success rate of 32.14%. Analysis of obstacles in the direct method showed that most of the unlinked subject headings contained geographical subdivisions, cataloger-generated subdivisions, or culturally specific concepts related to Iranian or Islamic customs. Under the indirect method, technical issues—such as software errors and punctuation inconsistencies—further hindered successful alignment. While the indirect method is generally easier to implement, its inability to link cultural and religious terms underscores the continued necessity of direct linking. Expanding coverage to include datasets specifically focused on cultural and religious concepts could further enrich the overall dataset.
Keywords
- Semantic Web
- Persian Subject Headings (PSH)
- linked data
- subject headings
With the emergence of the web, the world has transformed into an interconnected environment. Cultural institutions, such as libraries, need to adapt to these changes to satisfy the needs of library users and maintain their roles as information hubs in the modern era (Wójcik, 2015). Web 2.0 allows users to communicate, interact, and share information (Boateng and Quan Liu, 2014). In response to the rise of Web 2.0, libraries have developed their own Web 2.0 services like Really Simple Syndication (RSS) feeds, Wikis, weblogs, social tagging, and instant messaging (Byrne, 2008).
The web has now entered the third phase, known as web 3.0. characterized by Semantic Web technology, web 3.0, aimed at organizing information to improve users accessibility and discoverability (Warrier et al, 2015). Web 3.0 has evolved many library functions, including cataloging, reference services, and acquisition processes. To keep pace with the advancements of the web, linked data as a technology of web 3.0 has emerged. Linked Open Data (LOD) is a technology that tries to establish a relationship with data from different sources. To do so, LOD assigns unique identifiers to entities—such as names, locations, and connection types—facilitating their linkage through Resource Description Framework (RDF) triples (Mak et al, 2020). Linked data publishes data in a machine-readable and structured format like RDF, which improves data interoperability and integrity. The aggregation of library data enables a shared hub linking datasets like authority controls, subject headings, and bibliographic records (Byrne and Goddard, 2010). Linked Data helps libraries to enrich their data.
Linked Data offers several key benefits for improving data management and interoperability. It integrates diverse data models, enabling cross-dataset linking and querying through technologies like Web Ontology Language (OWL) (Beetz and Borrmann, 2018). As it’s designed to operate at web scale, Linked Data supports open, connected systems that enhance accessibility and reuse (Alemu et al, 2012). It enhances data precision via Uniform Resource Identifiers (URIs) while facilitating external source integration (Southwick et al, 2015). Additionally, it empowers smaller institutions to lead to metadata transformation due to their close connection with local data (Southwick et al, 2015). These capabilities make Linked Data powerful for developing connected, user-friendly information systems which enhance search experiences (Akullo and Nsibirwa, 2024).
Within the Semantic Web environment, integrating and enriching data with external datasets enhances visibility, library data discoverability, and overall user experiences (Kamdar and Musen, 2021). Data enrichment involves identifying relationships and alternatives within similar datasets, thereby increasing data visibility and interoperability.
Linking Persian Subject Headings (PSH) with other available data on the web is also important for Data enrichment. Converting PSH to Linked Data (LD) improves its technical and cultural utility. Currently, English-language datasets dominate LOD cloud (Ehrmann et al, 2014). This imbalance limits the visibility and integration of non-Western knowledge systems, including those rooted in Persian language, history, and cultural frameworks.
Publishing PSH as Linked Data allows Persian cultural and intellectual contributions to be more discoverable and accessible. It enables libraries, scholars, and digital platforms to reuse Persian concepts in a standardized, machine-readable format. This facilitates cross-cultural research and enhances multilingual information retrieval. Moreover, linking PSH to existing LOD datasets (e.g., Wikidata, Bibliothèque nationale de France (BnF), Integrated Authority File (GND)) facilitates semantic alignment between Persian terms and their equivalents in other languages. However, since linking data is a relatively new concept—especially when it involves Persian language and cultural context—the process of data linking may face certain challenges.
Libraries have adopted LD to enhance the accessibility, interoperability, and visibility of their resources on the web. As Miller and Westfall (2011) highlighted, libraries have long-standing expertise in organizing, curating, and preserving data, making them well-positioned to lead LD initiatives. By transitioning traditional cataloging systems to LD formats, libraries enable seamless integration with global data networks. This shift allows libraries to move beyond isolated catalogs and contribute to the universal data space, where information is interlinked and easily discoverable. Given Linked Data’s growing importance, recent studies explore its benefits and applications. For example, Heng et al. (2022) examined the effectiveness of using Virtual International Authority File (VIAF) Linked Open Data for name authority reconciliation. Their study revealed that LOD can significantly improve name reconciliation processes by enhancing interoperability and disambiguating names via linked connections. Similarly, Chen (2023) investigated the advantages of using Linked Data in library catalogues. His findings suggest LD-enhanced catalogs improve browsing by enabling resource discovery and creating virtual union catalogs. Examining the transformation of institutional and collection metadata into Linked Data, Bahnemann et al. (2021) illustrate the practical benefits in a pilot project. This project demonstrated that converting metadata into Linked Data not only enhances contextual richness but also creates a stronger meaningful network and integrates information into a broader web of knowledge. The project showed Linked Data can support both developers and researchers.
In addition to these technical and functional perspectives, other studies have explored professional and institutional views on the use of Linked Data in libraries. Rasmussen Pennington and Cagnazzo (2019) investigated the perceptions of information professionals working in European national libraries. Their findings indicated that Linked Data enhances discoverability, reusability, and data quality. Furthermore, it facilitates multilingual data handling, supports existing information reuse, and reduces catalogers’ workload. While Rasmussen Pennington and Cagnazzo (2019) examined the perceptions of information professionals in European national libraries, McKenna et al.’s (2018) study similarly investigates the perspectives of information professionals working across libraries, archives, and museums, offering a broader view of the opportunities and challenges posed by Linked Data in cultural heritage institutions. The research identifies key benefits: enhanced discoverability, improved accessibility, better authority control, metadata enrichment, and more efficient cataloging and data sharing. However, the study also highlights notable challenges, particularly technical barriers related to integrating datasets, mapping traditional metadata to LD models, aligning controlled vocabularies, and selecting appropriate link types. Additional obstacles include limited functionality of existing LD tools, lack of high-quality resources, and constraints in time and funding. Other studies examine Linked Data implementation barriers. Warraich et al. (2022) conducted a qualitative study on the adoption of LD technologies in Pakistani libraries. They interviewed senior library and information science professionals and found that, despite recognizing benefits like increased online visibility of library resources, several challenges existed. These included Machine-Readable Cataloging (MARC) standard limitations, staff skill gaps, privacy issues, and time constraints. Singer (2009) also discussed the limitations of current library data systems. He highlighted inefficiencies and inadequate structures, arguing that LOD could improve data reuse, structuring, and web integration. However, it underscored technical and organizational barriers requiring resolution for successful implementation.
While implementing Linked Data in libraries can be challenging, many researchers and institutions have explored effective methods for converting library data into RDF and Linked Open Data formats. Senso and Arroyo Machado (2018) proposed a comprehensive six-step methodology to convert the bibliographic records into Linked Data. Their approach noted the importance of data integration and high-quality data for publishing Linked Data. Similarly, Kar and Das (2021) presented a methodology for converting MARC 21-based personal name authority data into RDF triple format and publishing it as LOD.
Several studies have documented conversion efforts within digital collections, demonstrating how specific datasets can be linked to external web resources. Ryan et al. (2015) highlighted linking and publishing digital collection data. They described linking the Logainm dataset (containing Irish and English place names), converting it from Extensible Markup Language (XML) to RDF, and connecting it to other geographical datasets. Their efforts involved converting the dataset from XML to RDF format and establishing linkages with datasets such as DBpedia, LinkedGeoData, and Geonames, resulting in the creation of a comprehensive RDF dataset containing 1.3 million triples. Similarly, Hanson (2014) outlines Linked Data project stages using North Carolina State University (NCSU) Libraries’ Organization Name Linked Data (ONLD) project as an example. Tian et al. (2021) discuss LOD service integration through Emblematica Online, using VIAF and Library of Congress (LC) Application Programming Interface (API)’s to reconcile names/subject headings and improve digital collection discovery.
At the national and institutional levels, several projects have developed detailed workflows for converting large-scale library data into LOD. Vila-Suero and Gómez-Pérez (2013) described their work with the Spanish National Library’s MARC records, which were transformed into RDF using a process that included specification, modeling, linking, and publication. The tool MARiMbA was employed in this effort to produce the datos.bne.es dataset. Similarly, Apenīte and Bojārs (2021) converted the National Library of Latvia’s subject headings into Simple Knowledge Organization System (SKOS) format using the mc2skos tool and published the dataset via Skosmos to facilitate user-friendly browsing. Parker and Gray (2019) detailed the University of Maryland’s efforts to convert its authority file into Linked Data using OpenRefine, aiming to enhance the interoperability of archival collections. They noted that while OpenRefine worked well for smaller datasets, more scalable tools like Python were needed for efficient automation. Rodríguez Calvo (2023) developed a methodological model for transforming descriptive metadata from the National Library of Costa Rica into LOD. The project emphasized relationship visualization through graphical representations and used OpenRefine for data transformation. Other studies investigating Linked Data implementation in libraries include the National Library of France (Agnès, 2014), the German National Library (Deutsche nationalbibliothek, 2022), he Swedish Union Catalogue’s RDF conversion for Semantic Web integration (Malmsten, 2008), and Linked Data implementation in Library of Congress Subject Headings (Summers et al, 2008). These studies underscore Linked Data’s growing importance for enriching library resources and promoting interoperability in the global library community.
Linked Data has been a topic of considerable discussion within the local context of Iran. Various studies examined the application of LD in different domains. Behkamal et al. (2011) proposed a framework for converting Ferdowsi University of Mashhad’s Persian data into Linked Data. Other studies include pharmaceutical information conversion to Linked Data (Sekhavati et al, 2011) and a web object linking framework (Hosseini, 2019). These studies suggest that LD can improve semantic retrieval in different contexts.
In the library field, several initiatives have attempted to implement or conceptualize LD practices in Iran. The first attempt to publish library data in Iran was initiated by Eslami and Vaghefzadeh (2013) aiming to publish the data of the National Library and Archives of Iran (NLAI) in the form of Linked Data. Using Functional Requirements for Bibliographic Records (FRBR), they defined a model to create a Linked Data version of the National Library authority files. For this purpose, a small subset of the names authority file available in the Rasa database was selected and based on expert-created mappings, was converted and stored as RDF. However, their research has yet to be implemented in a web environment. Sekhavati (2011) also provided a framework for publishing library information based on the principles of Linked Data. A Java program was developed for converting data into RDF. After converting to RDF, the data were stored in the Sesame RDF repository. The study examined the conditions for linking datasets and identified data samples that could be connected. Fathian Dastgerdi et al. (2022) examined the components needed to implement the Linked Data method in library systems and proposed a model based on their findings. Their research highlighted the absence of links in records displayed in Universal MARC /XML (UNIMARC XML) format. It emphasized the potential impact of adopting Linked Data on how bibliographic metadata is presented in library systems. Additionally, Akbaridaryan et al. (2017) conducted a study to make the trilingual cultural thesauri of the NLAI available in Linked Data and SKOS formats. For this purpose, a mapping was developed to convert MARC records to SKOS; URIs were assigned to the records, and the conversion was carried out using JavaScript.
According to the papers reviewed, it seems that LD has attracted scholarly attention in Iran, particularly in the context of libraries. While several papers have explored publishing library data—especially subject headings—as Linked Data (Akbaridaryan et al, 2017; Eslami and Vaghefzadeh, 2013; Sekhavati, 2011), little research has focused on linking PSH to external datasets.
As evidenced by current practice, major libraries — including the Library of Congress, British Library, BnF, Biblioteca Nacional de España, US National Library of Medicine, and US National Agricultural Library—have implemented Linked Data publishing for bibliographic and authority records (Bushman et al, 2015; Hallo et al, 2014). Recently, Iranian library and information institutions have also begun taking steps toward implementing Linked Data, particularly through the semantic structuring of thesauri. In 2019, the Iranian Research Institute for Information Science and Technology (IRANDOC) initiated the integration of its thesauri into the Semantic Web environment. Over 100,000 terms were published with semantic relationships, and in a subsequent phase, the thesauri were made publicly accessible using the open-source Skosmos platform. Currently, 15 thesauri are available in RDF on IRANDOC’s website (Iranian Research Institute for Information Science and Technology, n.d.). Similar developments have taken place at the NLAI, which has published Iranian Cultural Thesaurus (ASFA)—using Skosmos platform and SKOS/RDF. The thesaurus was originally compiled in 1993 at the Islamic Revolution Document Center. The NLAI developed and maintained subsequent editions, incorporating the data into Iranian MARC and Online public access catalog (OPAC) systems since 2006. Currently, ASFA is publicly available on Skosmos platform in accordance with Semantic Web standards.
In 2020, the NLAI further expanded its efforts by developing and semantically publishing the Iranian General Administrative Thesaurus. Ongoing projects include the semantic publication of a medical thesaurus and the interlinking of ASFA terms with the UNESCO Thesaurus, both under the supervision of the NLAI (National Library and Archives of Iran, n.d.).
Although significant efforts have been made, key challenges remain for the NLAI and IRANDOC’s Linked data initiatives:
• Lack of URIs: Terms within the IRANDOC and NLAI thesaurus lack unique resource identifiers (URIs), which are essential for Linked Data applications. URIs provide unique identification for each concept, including person or thing. They facilitate linkage across collections (Southwick et al, 2015), without URIs, terms cannot be properly referenced, linked, or reused.
• Lack of Interlinking with Other Datasets: Although thesaurus data from IRANDOC and NLAI are semantically structured and available in SKOS/RDF, they have not been linked to equivalent concepts in other Persian or international datasets. Consequently, enhanced discoverability, semantic enrichment, and interoperability cannot be fully achieved.
While some steps have been taken in Iran to adopt Linked Data practices, it appears that no practical actions have been implemented to publish the Persian Subject Headings as Linked Data. Linking the data from the NLAI with datasets from other libraries is an effort that could help improve the retrieval and visibility of PSH on the web. To fill this gap, the current paper seeks to link the PSH with similar datasets, providing insights into the extent of linking within this context. By evaluating matching rates and identifying obstacles, this study aims to investigate how cultural and structural differences impact interoperability. In a previous study (Sabbaghi Bidgoli et al, 2023), a framework was developed for converting and publishing Persian Subject Headings as Linked Data. Building upon that work, we investigate the matching rates between these subject headings and other datasets that have already been published as Linked Data. The aim is to enrich Persian Subject Headings with LOD sources and identify key challenges in linking PSH. To assess the linking potential of PSH, datasets representing different ways of organizing subject information were selected including controlled vocabularies (like Library of Congress Subject Headings (LCSH) and Faceted Application of Subject Terminology (FAST)), general ontologies like Yleinen suomalainen ontologia (YSO), multilingual knowledge graphs (like Wikidata), and national library datasets (like BnF and GND). This variety helps identify both the general challenges of linking PSH and the specific challenges related only to Persian terms such as Islamic religious terms or Persian geographic divisions. This diversity contributes to the paper’s main goal of identifying effective methods for integrating non-Western knowledge systems into LOD space.
Consequently, this study endeavors to publish a part of PSH and evaluate the extent to which they are linked with other datasets. Additionally, given the potential challenges associated with publishing and integrating Linked Data, this study will also examine the obstacles encountered during the linking process. Accordingly, two research questions are posed:
(1) To what extent are the data in the subject headings database of the PSH linked to similar datasets?
(2) What are the barriers to publishing and linking the PSH with other datasets?
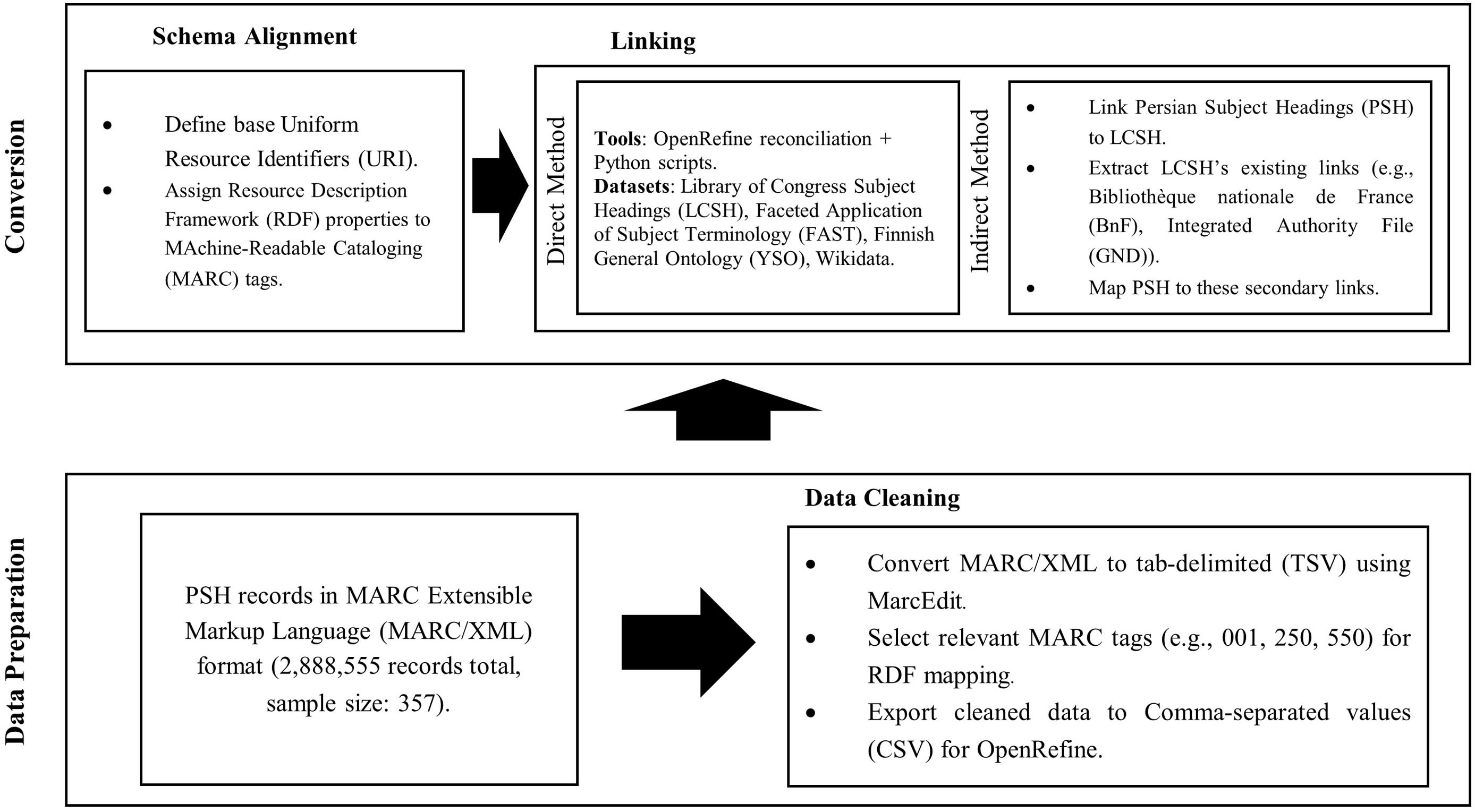
The purpose of this paper is to first determine the matching rates of PSH with other datasets. Based on related studies, the library method was employed to implement Linked Data in subject headings and evaluate the linking rates. The population of the study consisted of the PSH records from the NLAI. As of the time of writing, a total of 2,888,555 PSH records had been documented. Due to limitations in accessing all subject heading files, 50,000 subject heading records were obtained. Based on Morgan’s table, the sample size was determined to be 357. Therefore, the first 357 records were selected using non-random sampling. Fig. 1 illustrates the key steps followed in this study.
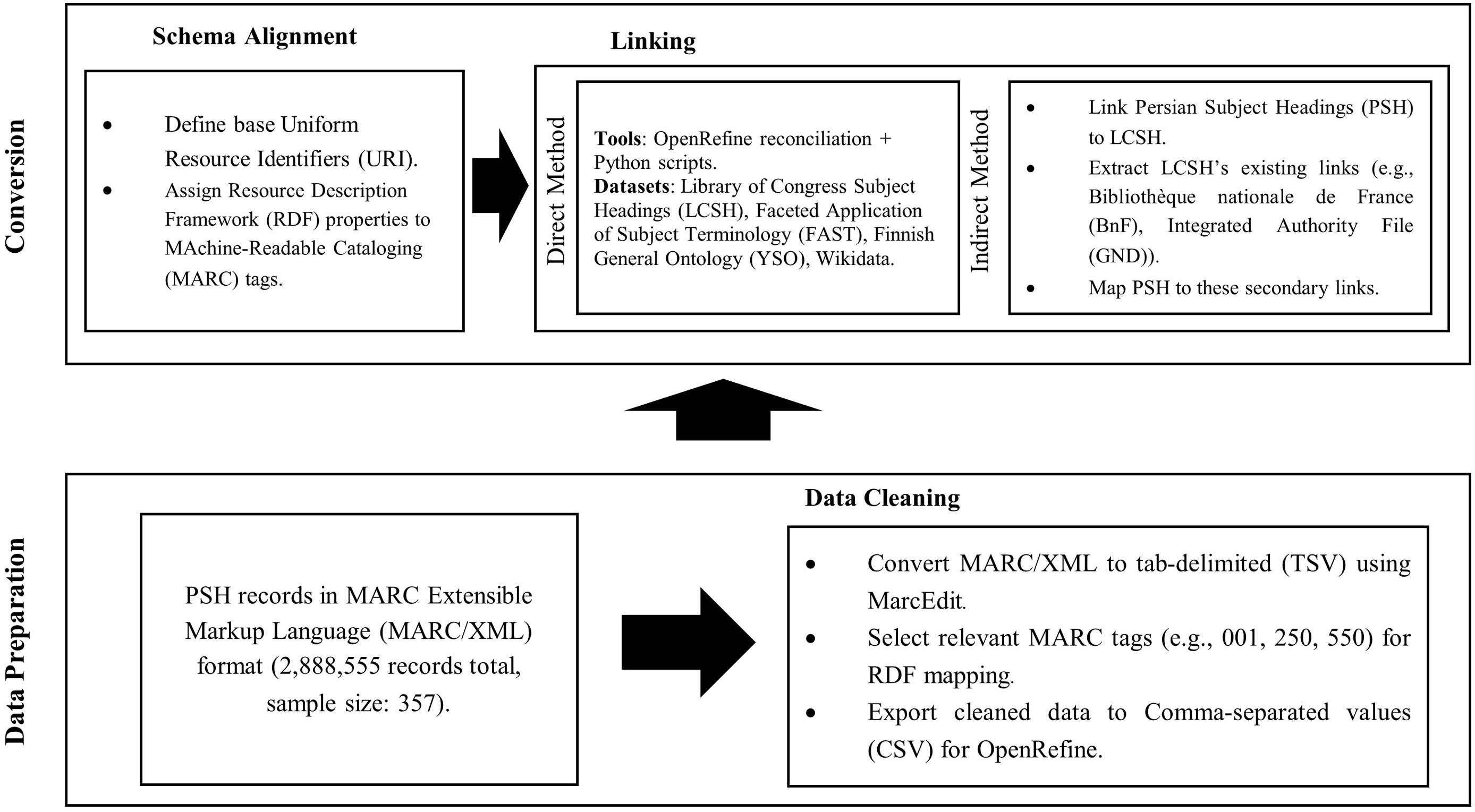 Fig. 1.
Fig. 1.
Workflow of schema alignment and linking methods for Persian Subject Headings (PSH).
To convert the data into Linked Data format, it is first necessary to ensure that the data is consistent and accurate. Next, it is necessary to correct any possible errors in the data, because if errors exist, the conversion process may fail, and some data might not link to external sources. Initially, the PSH records were obtained in MARC/XML format and converted into a tab-delimited (TSV) file using MarcEdit Version 7.1 (for Windows) developed by Terry Reese. The MARC tags that can be used for linking the data were selected based on previous studies (Akbaridaryan et al, 2017; Kar and Das, 2021; Summers et al, 2008). The Record Identifier tag (001), General Processing Data tag (100), Authorized Access Point – Topical Subject (250), General Explanatory Reference Note (320), General Scope Note (330), Variant Access Point (450), Related Access Point (550), Source Data Found (810), Source Data Not Found (815) and General Cataloguer’s Note (830) tags were selected for mapping into RDF. After removing unnecessary tags, the data were exported as a Comma-separated values (CSV) file and prepared for import into OpenRefine to transform into RDF.
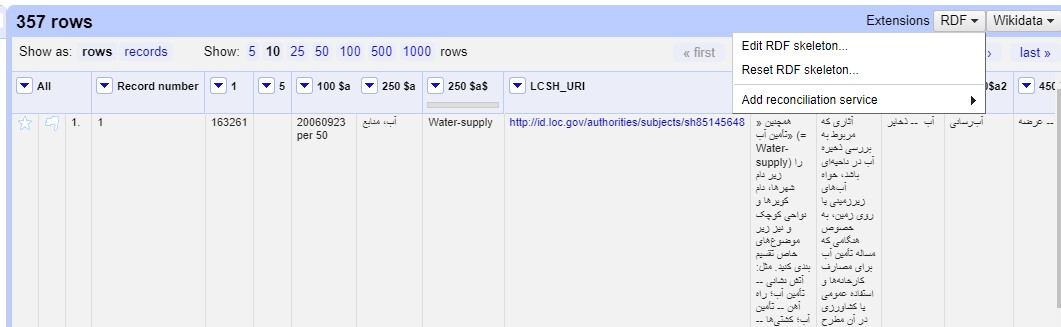
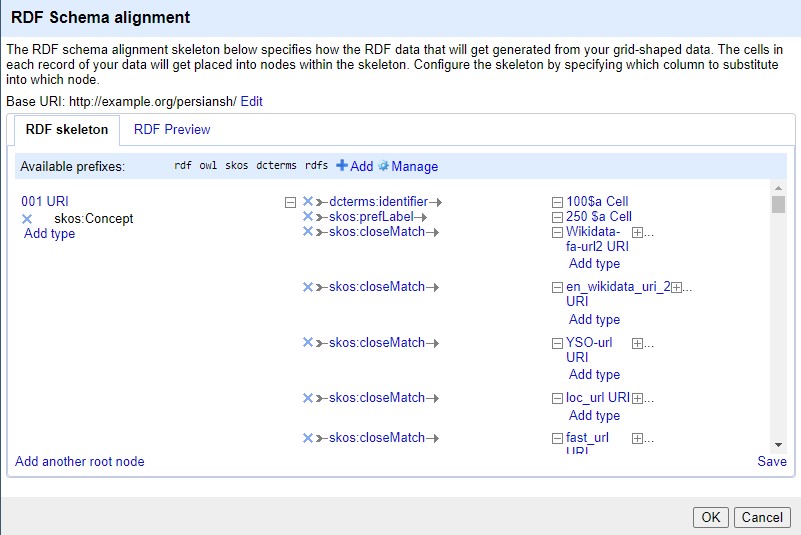
When importing data into OpenRefine, no semantic relationships existed among PSH records. The “Edit RDF Skeleton” option was used to link the related records and join them semantically (Fig. 2).
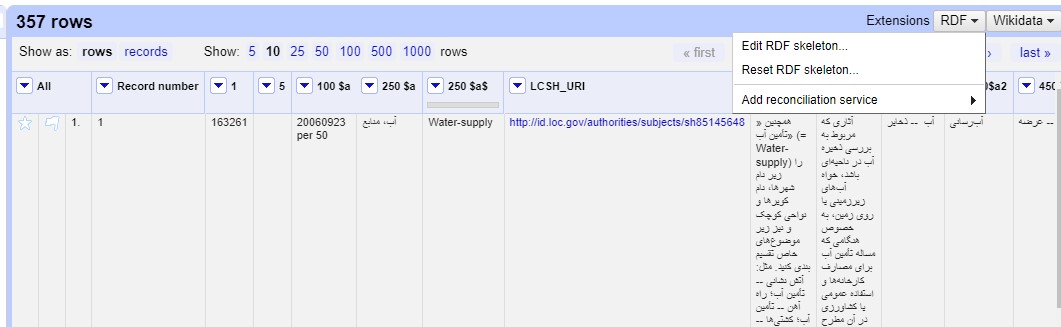 Fig. 2.
Fig. 2.
Edit Resource Description Framework (RDF) Skeleton in OpenRefine.
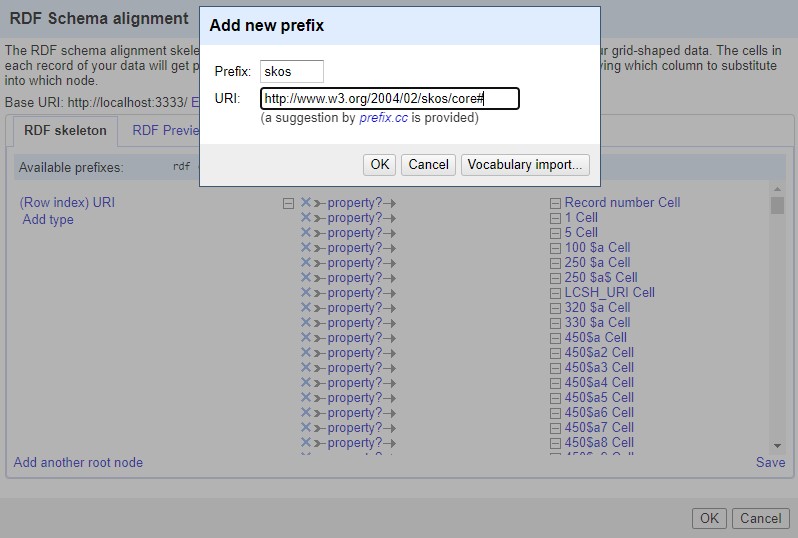
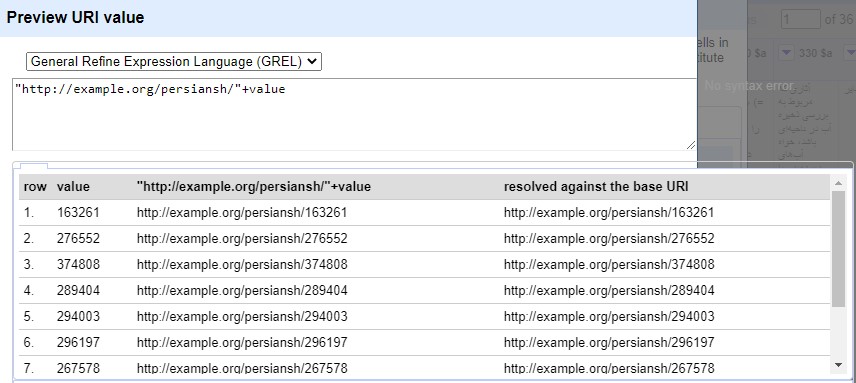
Defining a URI for the imported records was the first step in transforming them into RDF. Example.org/persiansh was used as the base URI. Dublin Core terms (DCTERMS) and SKOS namespaces were used to transform the records into the RDF standard (Fig. 3). Based on these namespaces, properties were assigned to the selected MARC tags. Record identifier field (001) was selected as the root node. Using Google Refine Expression Language (GREL), the record identifier value was added to the base URI (Fig. 4).
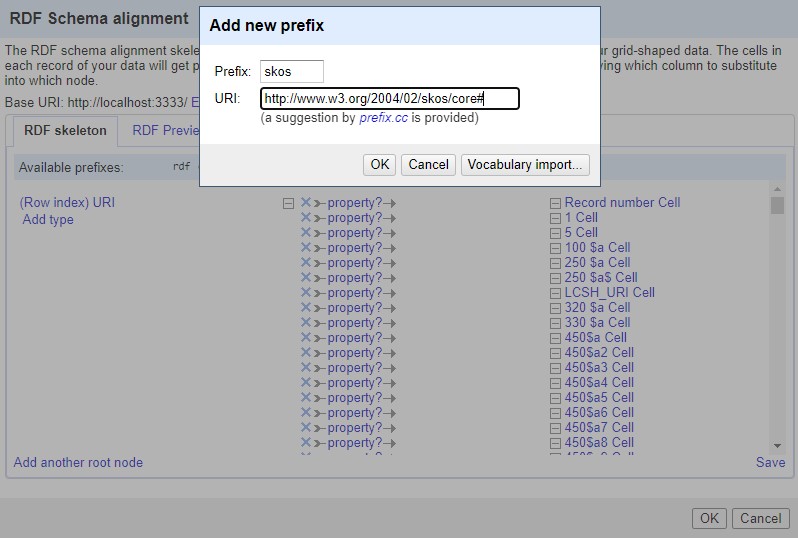 Fig. 3.
Fig. 3.
Adding Simple Knowledge Organization System (SKOS) namespace.
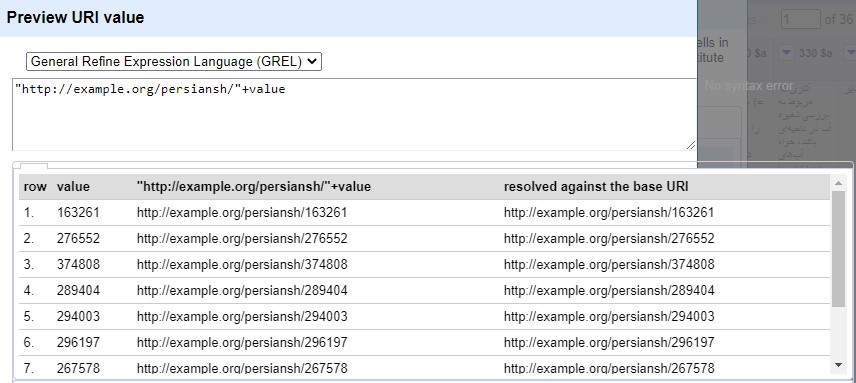 Fig. 4.
Fig. 4.
Adding a Uniform Resource Identifiers (URI) to Base URI.
The 250 tag, which refers to the preferred topical term in both English and Persian, was inserted into the RDF schema. Table 1 shows the MARC tags and the RDF properties assigned to each.
| Iran MARC tag | Property | Mapping condition |
| 250$a | skos:preflabellang="fa" | if $7="" |
| 250$a | skos:preflabellang="en" | if $7="ba" |
| 450$a | skos:altlabel | |
| 330$a | skos:scopenote | |
| 550 | skos:broader | if $5=g |
| 550 | skos:narrower | if $5=h |
| 550 | skos:related | if $5=9 |
| 320$a | skos:definition | |
| 830 | skos:note | |
| 815 | skos:editorialnote | |
| 001 | skos:concept | |
| 810 | dcterms:source | |
| 100 | dcterms:identfier |
Empty cells indicate tags without conditional mappings (e.g., skos: narrower applies only when subfield $5 is h). RDF, Resource Description Framework.
Based on Table 1, the properties corresponding to the selected MARC tags were defined and integrated into the RDF. The alignment with the RDF schema is illustrated in Fig. 5.
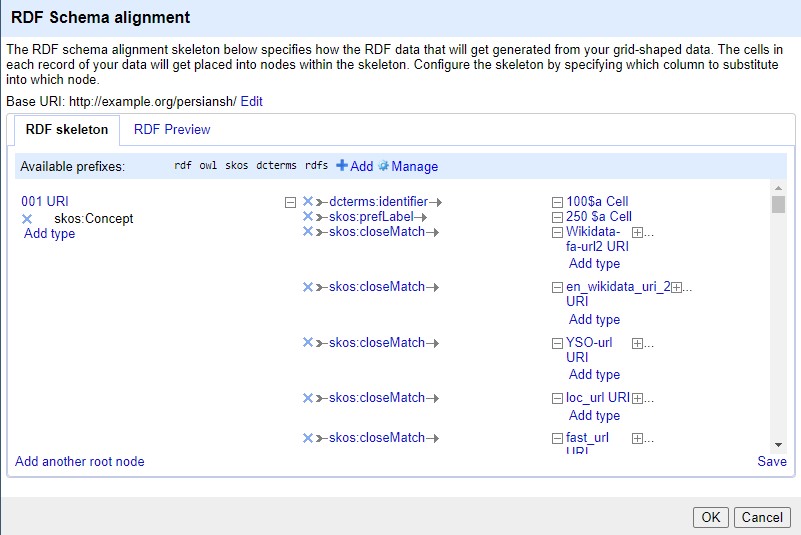 Fig. 5.
Fig. 5.
RDF Schema alignment after assigning namespaces and entities.
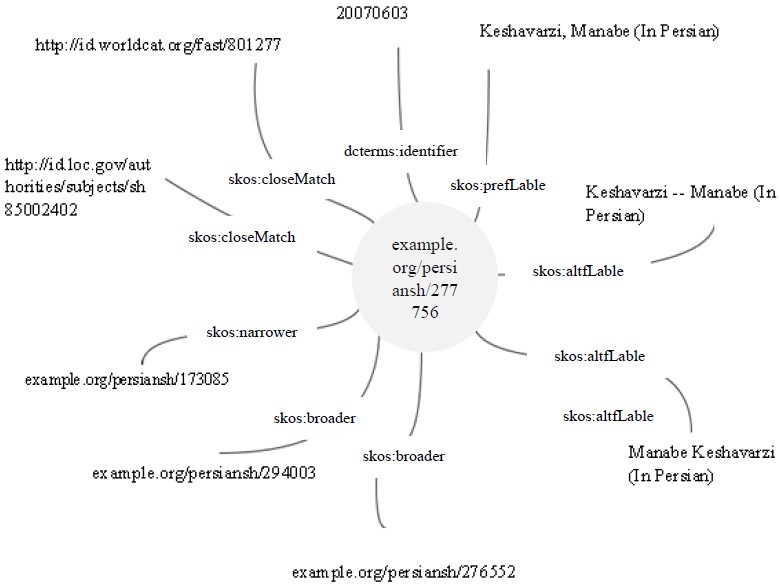
The process of assigning URIs and establishing a semantic relationship between the entities within each record is illustrated in Fig. 6.
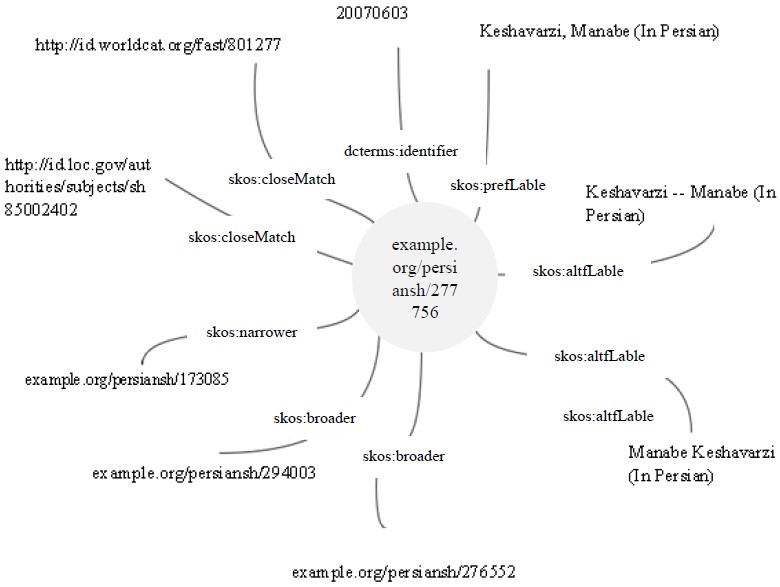 Fig. 6.
Fig. 6.
Graph representing a persian subject heading and its links to external datasets.
Linking the existing subject headings with external data enriches them. Therefore, it is necessary to identify similar datasets and establish links with them. Datasets concerning topical terms can be linked with the dataset used in this study (i.e., Persian Subject Headings). To demonstrate a broad lexical range and maximize data enrichment, diverse datasets were selected—including the LCSH, the FAST thesaurus, the YSO, and Wikidata—to link with the NLAI’s data. Despite differences in purpose and cultural scope among the selected databases, integrating PSH with terms from these datasets enables testing interoperability across models and evaluating cultural biases in published datasets.
Linking was performed using both direct and indirect methods. In the direct method, datasets concerning topical terms were separately linked with PSH records using a Python script and OpenRefine reconciliation services. The LCSH, FAST, YSO, and Wikidata were selected for integration in the direct method. To identify possible equivalents between PSH and LCSH, the Reconcile option in OpenRefine was used. After integration and alignment, URIs from LCSH and Wikidata were embedded as hyperlinks in the 250 field. This means that all PSH terms successfully matched with their equivalents in LCSH or Wikidata became clickable links. Using GREL, the links of the selected PSH terms in this study were linked to the corresponding entries in the Library of Congress Subject Headings and Wikidata.
“cell.recon.match.id”
To enrich data with FAST and YSO, the RDF/XML format of FAST records and the JSON format of YSO records were first obtained. Using GREL, URIs were extracted and linked to corresponding PSH records. The following GREL expressions were used for data retrieval and linking:
“http://id.worldcat.org/fast/search?query=oclc.heading+exact+%22"+value.replace(/(\s)/,'%20')+"%22&httpAccept-application/rdf%2bxml”
“http://id.worldcat.org/fast/"+value.parseHtml().select ('dct identifier')[0].htmlText()”
https://api.finto.fi/rest/v1/search?query="+value.replace("","%20")+"&vocab=yso"
value.parseJson().results[0].uri
Conversely, in the indirect method, the LCSH dataset was first selected for linking with PSH. Using GREL embedded in OpenRefine, topical terms that were already linked to LCSH were extracted from the RDF version of the LCSH records. In the second step, these extracted terms were matched and linked to their equivalents in PSH.
Direct and indirect methods were used to link PSH with external datasets. In the direct method, data linked to LCSH were also linked to PSH. For more precise linking, manual methods were also required (Marjit et al, 2013). In the indirect method, we linked available datasets to our study dataset using reconciliation services. The following section reports matching rates for both methods.
After fetching URIs, 241 of 357 subject headings (68%) were automatically linked to LCSH. 116 topical terms could not be automatically linked to the Library of Congress. Therefore, unlinked terms were manually searched in the Library of Congress Linked Data service (https://id.loc.gov/). From manual searching, 50 subject headings found alternative links (43%). However, 66 subject headings had no links to LCSH. Ultimately, 291 Persian topical terms (82%) were linked to LCSH through both methods.
293 Persian topical terms were linked to FAST (82%). However, 64 subject headings had no automatic links (18%). These 64 subject headings were manually searched. Manual searching found identical FAST matches for four terms (6%), while 60 terms (94%) found no matches. Overall, 297 PSH terms were linked to FAST (83%), while 60 terms remained unlinked. Among these, 59 terms (98%) also had no LCSH links. Thus, 98% of unlinked terms matched those without LCSH links.
In the initial YSO linking attempt, 57 of 357 Persian topical terms (16%) were linked, while 300 terms (84%) found no matches. The unlinked terms were then manually searched in the YSO. Of these 300 terms, two (1%) were linked to YSO, while 298 (83%) remained unlinked. Overall, 60 of 357 PSH terms (17%) matched YSO terms through automatic/semiautomatic methods, while 297 (83%) had no YSO matches.
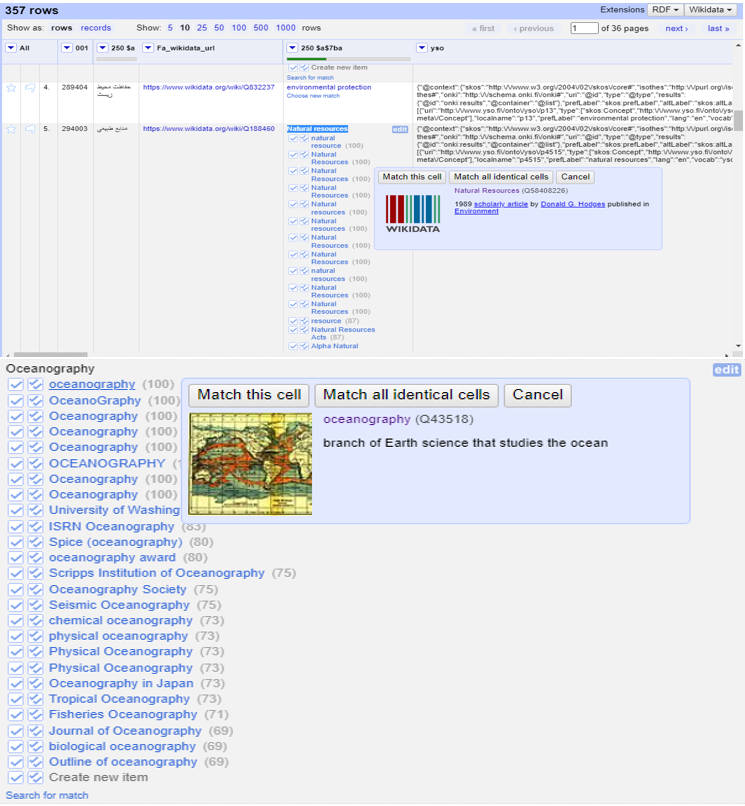
In the first reconciliation phase, 115 PSH terms (32%) matched Wikidata entries, while 242 terms (68%) had no exact matches. Because OpenRefine’s Wikidata API reconciliation service displays multiple data types, automatic exact matching was impossible, requiring manual verification. For example, OpenRefine returned 11 matches for “natural resource”. The first match represented the literal meaning (naturally occurring resources), while the second match referenced a music album. Manual confirmation was therefore required (Fig. 7).
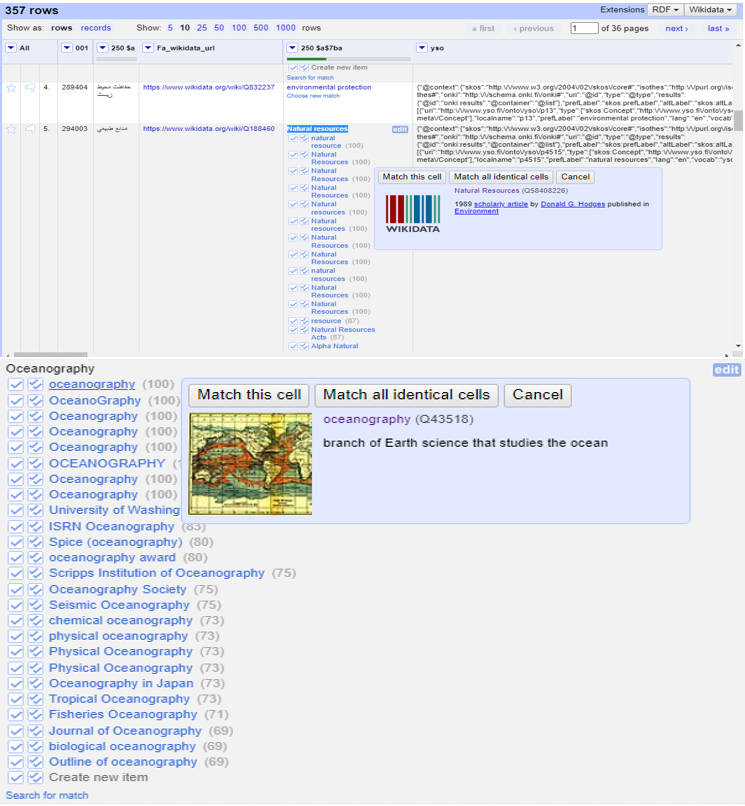 Fig. 7.
Fig. 7.
Manual confirmation of Wikidata terms in OpenRefine.
The search for identical Wikidata matches continued semi-automatically, confirming 23 of 115 unlinked terms (19%). Combining manual and automatic matching, 138 Persian terms (39%) matched Wikidata, while 219 (61%) remained unmatched. The process was also performed for Persian Wikidata. 110 terms automatically matched Persian Wikidata entries (31%), while the remaining 247 terms (69%) either had no matches or required manual confirmation. Only two terms were semi-automatically matched to Persian Wikidata, while 245 had no links. Overall, 112 terms (31%) were linked to Persian Wikidata through both methods, while 245 received no links. The 31% linking rate for Persian Wikidata was 8% lower than for English Wikidata.
In the indirect method, PSH terms first received links to LCSH. To obtain LCSH links, RDF/XML records were retrieved through OpenRefine queries. The RDF/XML blocks were then placed in separate columns. Since LCSH already links to external datasets, these links exist within their RDF/XML blocks. To link PSH to existing LCSH connections: (1) links were extracted from RDF/XML via queries, then (2) Persian terms were connected using OpenRefine’s Edit Skeleton feature. Thus, the indirect method only matches PSH terms that already have LCSH links.
Among the 357 studied terms, 291 matched LCSH. The indirect method was applied to these 291 headings, linking 63 (21%) to YSO. Compared to the direct method’s 60 matches, no significant difference exists between YSO linking approaches. Overall, 81% of terms received identical YSO links through both methods, with indirect linking covering 4% more terms.
Of the 291 subject headings linked via the indirect method, 271 (91%) were connected to PSH. The study used 357 PSH terms. Since the indirect method utilized LCSH links, the FAST matching rate was 76% of total terms. In the direct method, 205 terms matched FAST. All 205 terms matched in the direct method were also linked via the indirect method.
The GND, provided by the German National Library, facilitates controlled vocabulary use in web environments. Like subject headings, it includes personal names, corporate names, geographic names, conferences, events, and topical terms (Deutsche nationalbibliothek, 2022). 107 terms linked to GND (37%). While 107 terms linked to GND, they generated 154 links, indicating multiple links for some terms. The proportion of linking GND files (107 terms) to PSH (357 terms) was 30 percent which means that out of 375 PSH examined in this study, 30% were linked to GND.
The BnF project advances Semantic Web implementation. This project integrates cataloguing data, archival records, and digital documents. This project is also relied on authority data (Wenz, 2013) and links to LCSH. In this study, 195 BnF terms (67%) linked to LCSH. The total number of unique links were 293 meaning that some terms have more than one links to BnF. Overall, 55% of PSH linked to BnF.
Of the 291 terms common to both LCSH and PSH, only 97 (33%) linked to Wikidata. Compared to all 357 PSH terms, the linking ratio was 27%, lower than the direct method’s percentage. 93 terms of these 97 links were similar to links received in direct methods. Notably, 96% of Wikidata links from LCSH matched direct linking results. However, 4 links (4%) represented similar (but not identical) LCSH terms. In summary, direct linking achieved 12% higher coverage with PSH.
The NALT, developed by the USDA National Agricultural Library, covers agricultural, biological, and related topics. Since most of the PSH studied in this paper were related to agriculture, they linked to NALT. While 73 NALT links were identified, only 63 unique terms linked to NALT meaning that 10 subject heading received 2 NALT links on average. Overall, 18% of PSH terms matched NALT terms.
The Getty Vocabularies include art, culture, archival objects, and related terms. The Getty Vocabularies comprise four thesauri: the Art & Architecture Thesaurus (AAT), the Getty Thesaurus of Geographic Names (TGN), the Union List of Artist Names (ULAN), and the Cultural Objects Name Authority (CONA). Since most of the topical terms of the population in study were among agricultural topics, few were expected to link with art thesauri. However, some general terms linked to the Getty AAT. Of 291 subject headings, 6 terms (2%) matched the Getty Vocabulary. One term received two links from this dataset. Table 2 summarizes matching rates for both methods.
| Linking method | Dataset | Number of matched terms (Out of 357 terms) | Matching rate (Percent) | Non-matching rate (Percent) |
| Direct | LCSH | 291 | 82% | 18% |
| FAST | 297 | 83% | 17% | |
| YSO | 60 | 17% | 83% | |
| English Wikidata | 138 | 39% | 61% | |
| Persian Wikidata | 112 | 31% | 69% | |
| Indirect (through LCSH ) | FAST | 271 | 76% | 24% |
| YSO | 62 | 17% | 83% | |
| English Wikidata | 97 | 27% | 73% | |
| BnF | 195 | 55% | 45% | |
| GND | 107 | 30% | 70% | |
| NALT | 63 | 18% | 82% | |
| Getty Vocabulary | 6 | 2% | 98% |
LCSH, Library of Congress Subject Headings; FAST, Faceted Application of Subject Terminology; YSO, Yleinen suomalainen ontologia; GND, Integrated Authority File; BnF, Bibliothèque nationale de France; NALT, National Agricultural Library Thesaurus.
In the direct linking method, where the endpoints of similar datasets were used, the highest PSH matching rates with FAST (83%) and LCSH (82%) datasets. In contrast, the lowest PSH matching rate was with the General Finnish Ontology (17%). Persian and English Wikidata showed similar linkage rates (39% vs 31%, respectively), with an 8% difference. Among 357 subject headings, 51 received links to all five datasets, while 57 received none. Compared to the direct method, there were some limitations in the indirect linking method where only 297 subject headings which already had links with LCSH could receive links with other possible datasets. FAST showed the highest LCSH linkage rate (93%). BnF ranked second (67%), followed by GND (37%) and English Wikidata (33%). YSO and NALT showed equal linkage rates (21%). Getty showed the lowest linkage rate (2%). The term that received the most links to external dataset was ‘Agriculture’, which received 21 external links.
To identify the limitations of matching the PSH with terms of other datasets, the Persian topical terms which did not receive links were examined and the percentage of not matching was identified. 66 PSH terms didn’t match LCSH. Among these, 43 terms (64%) had geographical subdivisions which could not find exact topical term. For example, the preferred topical term “Land capability for agriculture—Iran—Darz (Larestan)” cannot not find a close match in LCSH. However, the lack of equivalents for subject headings with geographical divisions was not limited to the geographical divisions of Iran, but the geographical divisions of other countries were also not found in LCSH. For example, LCSH lacked equivalents for “Agriculture—Iraq—Babylonia” or “Water in agriculture—Pakistan”. Only subdivision terms that exactly matched LCSH translations were successfully linked, while terms containing subdivisions created by cataloguers could not find a close match with LCSH. For instance, the terms Agriculture—Management—Tests and Exercises (Higher Education) is a heading made by the NLAI cataloguers and could not be linked with LCSH. Some Iranian cultural/religious terms also lacked LCSH matches. For instance, Islamic Shiite term “Dahw al-Ard” and Zoroastrian term “sepantaM̄ainyu” had no equivalents (0.03%). Although some culture related headings did not find an LCSH match, some religious terms matched exactly. For example, “agriculture in Quran” and “Agricultural laws and legislation (Zoroastrianism)” topical terms exactly matched with LCSH. Thus, 3 of 5 Iranian culture/religion terms remained unlinked. The remaining terms that did not receive a link included more specialized words and phrases that were created by the catalogers of the National Library themselves and, consequently, did not have an equivalent in the Library of Congress.
The PSH which could not find links were, in 99% of cases, similar to the unlinked terms in the LCSH. In other words, as stated, 59 out of 60 terms that did not receive a link with FAST also failed to establish a link with the LCSH. Thus, the reasons mentioned for the lack of links with the LCSH also apply to the failure to establish links with the FAST terms. In general, out of the 60 terms that did not receive a link to FAST, 52 terms had subdivisions. Among these, 43 subdivisions had geographical divisions that also did not receive links LCSH. Like LCSH, FAST linking was hindered by national and religious terms. Thus, only 2 of 5 such terms linked successfully.
Matching rates between Persian topical terms and YSO were low. As the name of this ontology suggests, it mostly includes general terms. The sample used in this research included only 357 Persian terms, most of which were in the field of agriculture; therefore, they were not included in general terms and consequently received few links with the General Finnish Ontology. The 60 terms that successfully received links with YSO were more general subdivision-free. ‘Engineering’, ‘Agriculture’, ‘Geography’, ‘Pollution’, and ‘Maps’ are among the subject headings that linked to the General Finnish Ontology. Of 297 unlinked terms, 110 terms had subdivisions, and among these 110 terms, 43 headings had geographical subdivisions. However, the number of terms without a link to the General Finnish Ontology was 185, which was relatively higher than those with subdivision. No Iranian cultural/religious terms matched YSO. Limiting the sample of this paper to mostly agricultural terms can be considered as the obstacle for linking PSH with this ontology.
The non-matching rate with English Wikidata is similar to that of YSO. In fact, all terms that failed to match closely in Wikidata—except for two—also lacked links in YSO, also did not receive links with YSO. However, it is possible that these terms exist in Wikidata but refer to different concepts. For example, the term ‘farm management’, which in PSH refers to ‘running a farm’ in Wikidata refers to an academic field by that name. Therefore, it does not correspond to the intended term and does not receive a link. Like other datasets, subdivisions in Wikidata also created obstacles for establishing links. Out of the 219 terms without a link to Wikidata, 107 had geographical or non-geographical subdivisions. The remaining 112 terms had no subdivisions, and only 5 of these related to culture and religion. The remaining terms faced obstacles, including cases where similar matches in Wikidata referred to different concepts. For example, the term ‘Country Life’ existed in Wikidata but referred to unrelated entities such as a music album, a publication, a magazine, a company, or a film. Therefore, it did not receive a link to the corresponding PSH term.
Compared to English Wikidata, fewer PSH terms were linked to Persian Wikidata. The total number of terms that did not receive matches with Persian Wikidata was 245. Of these, 101 had subdivisions, and 43 had geographical subdivisions. The remaining unmatched terms were agricultural jargon such as ‘Terracing’, ‘Chemigation’, ‘Kriging’, ‘Spraying equipment’, etc. Although English Wikidata covers 7% more terms than Persian Wikidata, some terms received links in Persian Wikidata but not in English Wikidata. In other words, six terms were linked in Persian Wikidata but had no equivalents in English Wikidata. For example, the term “Dahw al-Ard” was found in the Persian Wikidata but did not have an equivalent in the English version. In fact, no English label is defined for this term in English Wikidata. For some proper nouns, the spelling of the English term in Wikidata differs from that used in PSH. For example, the term “سپنتا مینیو” which refers to a Zoroastrian deity, is written as “Spenta Mainyu” in the English Wikidata. However, its English equivalent in the PSH is written as “Sepantā Mainyu”. Therefore, the Persian term receives a link but encounters an obstacle in finding the English equivalent.
Two cultural and religious terms were linked with Persian Wikidata, which is equal to the number of terms matched with FAST and the Library of Congress Subject Headings. However, of the five cultural and religious terms, the two linked to Persian Wikidata were not linked to LCSH or FAST. Conversely, the two terms linked to LCSH and FAST were not linked in Persian Wikidata. In other words, although the number of matched and unmatched terms in the three datasets—LCSH, FAST, and Persian Wikidata—was the same, the actual terms differed in content.
Comparing matching rates across methods revealed several obstacles: A comparison of matching results using direct and indirect methods in YSO highlighted that the reason of not matching with the terms of YSO was due to the lack of close match links in LCSH or OpenRefine’s incorrect identification of subject heading types. By examining the differences between the links established with PSH in FAST database directly and indirectly, it was also determined that the absence of FAST links to Library of Congress records, OpenRefine’s misidentification of subject heading types, and errors in extracting RDF versions of these headings caused variation in the degree of linking to the FAST. The examination of links received and not received from Wikidata, both directly and indirectly, also indicated that there are various reasons for the absence of close and exact matches. As mentioned, in the indirect linking method, since links were extracted only from the 291 headings that had connections to the Library of Congress, the total number of links was naturally lower than the full set of 357 PSH records. Another reason for the absence of links was punctuation marks such as spaces. For example, in the term “Hydrology”, due to an extra space at the beginning of the word, it did not receive a link automatically in OpenRefine. Punctuation issues were identified as obstacles to linking, consistent with the findings of Tian et al. (2021). Additionally, the presence of terms related to culture and religion was also among the obstacles. Some Persian terms had equivalents in English Wikidata but were not listed in the Library of Congress Subject Headings. The frequency of unmatched terms is presented in Table 3, while the challenges and proposed solutions are outlined in Table 4.
| Dataset | Total number of terms not matched | Terms with subdivisions | Cultural or religious terms | Other | ||||||
| Geographical subdivision | Non-geographical subdivisions | |||||||||
| Frequency | Percentage | Frequency | Percentage | Frequency | Percentage | Frequency | Percentage | Frequency | Percentage | |
| LCSH | 66 | 57% | 43 | 74% | 15 | 26% | 3 | 1% | 5 | 1% |
| FAST | 60 | 17% | 43 | 83% | 9 | 17% | 3 | 1% | 5 | 1% |
| YSO | 297 | 83% | 43 | 39% | 67 | 61% | 5 | 1% | 182 | 51% |
| English Wikidata | 219 | 61% | 43 | 40% | 64 | 60% | 5 | 1% | 107 | 30% |
| Persian Wikidata | 245 | 69% | 43 | 43% | 58 | 57% | 3 | 0.002% | 141 | 38% |
| Challenge | Solution from literature | Success level in this study | References |
| Cultural/religious term mismatches | Develop local language datasets as complementary sources | Limited success (31% matching with Persian Wikidata) | (Munnelly et al, 2018; Mouromtsev et al, 2015) |
| Punctuation and formatting errors | Data Cleaning | Through data cleansing, the links were successfully established | (Tian et al, 2021) |
| Limited dataset coverage | Prioritize specialized vocabularies (e.g., LCSH/FAST) over general ontologies | Low success (YSO matching rate only 17%) | (Mouromtsev et al, 2015) |
In an overall comparison regarding the number of links by direct and indirect methods, it was found that the number of links received to Faceted Application of Subject Terminology (FAST) and English Wikidata in the direct method was higher than in the indirect method. However, the General Finnish Ontology (YSO) showed no linkage rate difference between methods. Overall, it can be stated that fifty percent of PSH terms had close/exact matches across all datasets, aligning with Tian et al.’s (2021) findings. However, the indirect method’s average linking rate (32.142%) was lower than the direct methods. It appears that LCSH’s linking patterns suggest the indirect method better enriches PSH. Despite its advantages, this method faced some limitations. One key issue is that LCSH, when used indirectly, lacks specialized cultural and religious terms. This means that linking to PSH solely through extraction from LCSH RDF data is insufficient and requires establishing direct links.
While the direct method provides higher linkage rates overall, particularly with structured vocabularies like FAST (83%) and LCSH (82%), it is more effective when clear lexical or semantic equivalents of the terms already exist. This method offers more control and better accuracy in matching exact terms. In contrast, the indirect method while having a lower average matching rate (32%) demonstrated a greater capacity in enriching the subject headings. By using LCSH as a mediating vocabulary, the indirect method provides links to related concepts that are not present in PSH directly. Nevertheless, the method’s effectiveness depends on the completeness and cultural inclusiveness of the intermediary dataset and perform weak in linking terms related to Iranian culture and religion.
Ultimately, each method contributes differently to the enrichment of PSH. The direct method offers precision, while the indirect method enhances conceptual breadth.
Analyzing the terms that did not establish links with the Library of Congress Subject Headings dataset, it was found that most of the subject headings which could not be linked with terms of other datasets had subdivisions. In addition, topical terms containing geographical subdivisions did not find equivalent terms in any of the datasets. As a result, 43 terms with geographical subdivisions remained unlinked in all datasets. One of the main challenges in reconciling PSH to other similar datasets is the lack of links to other dataset for topical headings with subdivisions. This issue left some subject headings unlinked. It can be stated that subdivided terms in this study posed the limitations in this study. Whereas other study showed that non-subdivided headings are more successfully linked to external datasets (Snyder et al, 2020).
Although the sample in this research included only a small number of subject headings related to culture or religion, even these faced obstacles in finding equivalents. In sum, terms that were exact translations of LCSH easily received links, whereas terms that were coined by catalogers or related to Iranian culture and religion, and had no equivalents in English, could not be matched with LCSH. The low matching rate of PSH with geographical and religious terms indicates that mapping cultural and domain-specific concepts across different datasets is challenging. Additionally, differences in granularity—such as FAST’s faceted structure versus PSH’s hierarchical structure—further complicate and destabilize the matching process. A significant limitation of this study—mirroring Apenīte and Bojārs (2021)—is the inability to link culturally specific terms (e.g., Iranian religious concepts), highlighting a systemic gap in multilingual LOD resources. Finding a fully compatible knowledge base to link with a newly developed dataset can be challenging. As a solution, new datasets may be developed in the initial phase, after which the relevant entities can be linked (Munnelly et al, 2018). However, this approach can be both difficult and time-consuming. Moreover, contextual information associated with entities must be considered. In this study OpenRefine as a context-sensitive tool is employed. However, due to the lack of relevant Persian databases, some entities requiring contextual understanding may remain unlinked—an inevitable limitation. Reviewing the terms that failed to link with other datasets revealed that library vocabularies such as LCSH and FAST performed better in linking specialized terms, while general ontologies like YSO showed weaker performance. It was also found that using various types of datasets is essential for more successful linking, as Wikidata’s multilingual coverage helped connect culturally specific topical terms.
To link the national and religious terms with external data, the Persian Wikidata can serve as a complement to other datasets. The type and scope of the datasets can significantly influence data enrichment. In the case of using Persian-language datasets for enrichment with PSH, a higher enrichment rate would likely be achieved. As a result, it can be inferred that if there were a database of Persian, national, and religious terms, it would be easier to link them to PSH. Additionally, it would improve retrieval and visibility on the web.
Converting authority data into LOD is a new and emerging phenomenon, which can be seen as a step forward, yet a challenging process. Studies done on LOD in libraries have confirmed their potential and capability to use Linked Data. Converting the PSH into LOD and enriching them with similar datasets can be considered initial steps for facilitating PSH’s web implementation. This study set out to answer two key research questions regarding the integration of PSH into the LOD. First, the extent to which PSH could be linked to similar datasets was examined. It was indicated that while general terms achieved matching rates as high as 83% with controlled vocabularies like FAST, culturally specific concepts (particularly those with geographical or religious context) showed significantly lower interoperability, with only 31% matching in Persian Wikidata. Second, the study examined the barriers. It was revealed that structural differences, cultural specificity, and vocabulary granularity accounted for most linking failures—challenges that persisted across both direct and indirect linking methods. It was found that non-subdivided headings were more successfully linked to external datasets. Although the sample in this study was enriched with some external datasets, the relatively low matching rates for Persian-specific terms emphasizes the importance of developing complementary linking strategies beyond Western-centric datasets. This can contribute to enriching this study collection.
While implementing PSH in LD initially requires substantial investment in tools, infrastructure, and staff training, in the long term it can save time, effort, and reduce cataloging costs. Successfully implementing PSH in LD and linking it with other knowledge bases enhances the global visibility of Persian resources. Socially, if PSH is well integrated with global data, it can enable more people to access Persian knowledge and culture. Most linked data knowledge bases are still in English or other Western languages. Therefore, it is essential for Iranian cultural heritage organizations and museums to publish their Persian collections as linked data. Over time, this can promote more equitable access to and visibility of non-English data.
Future works should focus on linking non-subdivided topical terms to better identify the potential problems in linking with external datasets. Additionally, given the vast availability of datasets related to topical terms in various languages on the web, future works should consider integrating these resources to enhance the comprehensiveness and richness of the PSH. Since in this paper, enriching specific terms like traditional or religious Iranian terms encountered some limitations and were rarely linked to external datasets, future works need to enrich the Persian data with other Iranian cultural, archival, or museum datasets.
Data generated or analyzed in this study are available from the corresponding author upon reasonable request.
ZS designed the methodology, performed data cleaning, and implemented the technical processes. AS provided the raw data and supervised the overall research framework. ZS and AS jointly conducted manuscript revisions. FZ led the validation procedures and performed critical editorial revisions. All authors contributed to manuscript restructuring, approved the final version after multiple iterative reviews, and take public responsibility for the research integrity.
Not applicable.
This research received no external funding.
The authors declare no conflict of interest.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.