












 , Adil Kabbaj 1
, Adil Kabbaj 11 Research Laboratory in Information Systems, Intelligent Systems, and Mathematical Modeling (SI2M) Laboratory, National Institute of Statistics and Applied Economics (INSEA), B.P. 6217, 10112 Rabat, Morocco
Abstract
This paper presents a Knowledge-Based Ontology (K-BO) model, demonstrated through a case study. Unlike traditional ontology models, the K-BO model is rich in knowledge and incorporates various knowledge types, such as typical situations, conceptual constraints, and rules. We compare K-BO to the model of the Web Ontology Language (OWL). Our case study focuses on creating an ontology for a pedagogical dictionary that provides not only the definition of a word but also some of its typical uses, which are difficult or even most of the time impossible to model using OWL.
Keywords
- ontology model
- ontology language
- knowledge-based ontology
- conceptual graphs
- amine platform
- educational dictionary
Ensuring quality education for all children is a significant challenge in the 21st century (Malik, 2018), requiring the analysis of diverse information from multiple sources to develop effective strategies and actionable solutions. To this end, educational dictionaries can be valuable tools for language learning and understanding complex concepts. Among these dictionaries, “My First Incredible Amazing Dictionary” (Dorling Kindersley Publishing Staff, 1994) has attracted our attention due to its rich knowledge content and its widespread utilization in various scholarly projects intended for children. Since its establishment in 1995, it has earned a place on the Association for Library Service to Children (ALSC)’s (https://www.ala.org/alsc/aboutalsc) Notable Computer Software for Children list. This distinction marked the beginning of its journey to becoming a valuable resource in education. Remarkably, even in the current academic year of 2024–2025, it continues to be a prominent resource in the syllabi of English classes (https://cmseducation.cmsitportal.org/syllabus/pdf/class_1_NonAlfa.pdf). This presence underscores its sustained relevance and utility in the field of education. Considering these motivations, we have undertaken a project to develop an ontology derived from its contents. The dictionary and its ontology can be used in natural language processing tasks like Question/Answering.
The initial motivation for this study was to develop a Question/Answering application dedicated to education, aimed at evaluating its utility in helping students learn. However, challenges in modeling the ontology at the very outset highlighted the need to address these foundational issues first. Sharing these preliminary findings with the academic community lays the groundwork for future research and development in educational applications.
In our endeavor to develop the ontology, we encountered the challenge of significant loss of data when employing predominant ontology models such as the Web Ontology Language (OWL). This is a common problem reported by practitioners, particularly in the business sector, who have worked extensively with OWL (Semantic Arts, 2023), due to the fact that OWL often fails to capture and represent the typical knowledge found in a given domain.
In fact, humans use not only a taxonomy of categories with their definitions, but also other kinds of knowledge like typical situations, conceptual constraints and rules. This is illustrated by the pedagogical dictionary “My First Incredible Amazing Dictionary” for children, which provides both definition and typical use of words and concepts (See Fig. 1). However, the predominant ontology language, OWL, doesn’t consider typical situations and other knowledge structures like conceptual constraints and rules.
 Fig. 1.
Fig. 1.
Set of examples from “My First Incredible Amazing Dictionary” (The latter part of the definition of the concept Eat was added by the authors to illustrate the need for a conceptual structure that expresses necessary conditions for the use of a concept).
The novelty of our approach is not solely determined by the quantity of new references but especially lies in addressing a crucial issue that has long been present in the field yet neglected, as ontologists using OWL were embedding typical knowledge within annotations without fully appreciating its significance. Only recently has this issue begun to receive limited recognition.
Indeed, until recently, the ontology model behind OWL was considered an orthodoxy. However, many researchers within OWL and the Semantic Web community, particularly the Gist (https://www.semanticarts.com/gist/) community, are starting to recognize the need for a knowledge-rich ontology model and are actively working on how to effectively represent and process knowledge about typical situations (A YouTube video (Semantic Arts, 2023) capturing these discussions has been published. In this video, D. McComb presented a talk titled ‘Knowledge Ontology’, where he discusses, using several examples from various domains, typical knowledge that cannot be accommodated within OWL).
The primary research questions guiding this study are: How can we create an ontology for the educational dictionary without losing knowledge? How can typical knowledge, which cannot be easily integrated into the definition of a concept, be modeled?
A Knowledge-Based Ontology (K-BO) is characterized by its richness in conceptual structures, enabling, in addition to definitions, the incorporation of typical knowledge, constraints, and rules. This enhances the ontology’s utility and expressive power.
A K-BO can model typical knowledge encountered during the modeling phase, that cannot be represented using current ontology models. It helps build an ontology that retains the specialized information typically gained through years of experience within a domain, ensuring that this valuable knowledge is preserved and not lost in the way it is often with traditional approaches.
Amine (Kabbaj, 2009) is an artificial intelligence platform dedicated to the development of intelligent systems. It incorporates a K-BO model that provides various knowledge structures to represent different kinds of knowledge about concepts, relations, and individuals: definitions of concepts and relations, typical situations or schemata, conceptual constraints or canons, rules, as well as the descriptions of individuals.
This paper uses Amine’s K-BO model to illustrate the usefulness of K-BO.
The rest of the paper is structured as follows: Section 2 describes the two ontology models being compared and explains the criteria used for comparison and the adopted method of analysis. Section 3 presents the findings of the comparison based on each model, interprets them, addresses the identified needs, and explains how our K-BO model effectively meets those requirements. Finally, Section 4 summarizes our research findings, discusses their implications, provides suggestions for future research, and highlights the significance of our study in the field of ontology engineering.
The dictionary utilized in this research contains 1000 entries, each rich in information. An illustrative entry is presented in Fig. 2. When we extract information from an entry, we obtain a set of sentences, each conveying details about taxonomy, definitions, and occasionally typical knowledge related to the concept. For instance, the entry for “pelican” provides the definition of a pelican (the first sentence) and typical knowledge about the pelican (the second sentence).
 Fig. 2.
Fig. 2.
Example of entry from the dictionary.
For the purposes of this study, the dataset presented in this paper was selectively narrowed to four representative statements (See Fig. 1). This reduction was necessary because the entries are uniformly similar, making it redundant to present more entries from this document. These selected statements (Later in this paper, we will extend this subset and present examples that are inspired by the format of these examples) were specifically chosen to demonstrate how the two models under comparison—OWL and our proposed K-BO—differentially represent and interpret the various informational aspects contained within the statements. We will evaluate and compare the effectiveness and expressivity of each model at different levels, which will be outlined in the criteria section (See subsection 2.4).
OWL has become one of the most widely utilized and esteemed languages for ontology representation since its release in 2004. Supported by a vast and thriving community of developers, researchers, and users, OWL is an open standard based on Description Logic (DL) (Baader et al, 2005; Baader et al, 2003). It has two versions: OWL (SHOIN(D)) and OWL2 (SROIQ(D)), both of which have been W3C recommendations since 2004 and 2009, respectively (Welty et al, 2004; Motik et al, 2009b). OWL’s structure, which consists of different profiles, places it somewhere between First-Order Logic (FOL) and simple concept hierarchies (Troxel et al, 1994). For the purposes of this paper, our focus will be on OWL2 DL, the most expressive form of OWL, thanks to its foundation in DL, which is computable and decidable.
An OWL ontology is a sequence of logical and non-logical axioms, and possibly references to other ontologies (imports) that are considered included in the ontology. It provides a variety of constructs for representing classes, properties, individuals, which are organized into four main components: concepts, object properties, datatype properties, and individuals (Osman et al, 2021). From another perspective, OWL consists of various components, often referred to as “boxes”, each serving a specific purpose. The primary boxes in OWL are: TBox (Terminological Box), which defines the classes, their relationships, and the constraints on these relationships; and ABox (Assertion Box), which contains individuals or instances of classes and describes the specific instances and their relationships within the ontology.
OWL enables the definition of relationships between classes (union, intersection, disjointness, equivalence, subsumption, etc.), cardinality constraints for property values (minimum, maximum, or exact number), special relations for properties (transitive, symmetric, functional, inverse, reflexive, etc.), and restrictions on the domain and range of properties.
Amine Platform (https://amine-platform.sourceforge.net) is a multi-layer platform, designed for the development of intelligent and multi-agent systems (Kabbaj, 2009). It consists of several layers that work together to enable the creation, editing, querying, and processing of ontologies and knowledge-bases (KB), as well as inference and development of applications that leverage ontology and knowledge bases. This section focuses on its knowledge-based ontology model (Kabbaj et al, 2006), which is based on Conceptual Graph (CG) theory (Sowa, 1984; Sowa, 2000).
CG formalism is well-suited for representing knowledge on the semantic web (Berners-Lee, 2001; Martin and Eklund, 1999) through a direct mapping to and from natural language and a graphic notation designed for human readability (Kabbaj et al, 2006). CG enables the representation of knowledge in a way that is both machine-processable and human-readable; it has been recognized as a powerful formalism, offering the ability to effectively represent and structure knowledge. It is recognized as a powerful formalism for effectively structuring and representing knowledge (Gerbé and Mineau, 2002). A large community of researchers, developers, and users has emerged to advance and apply CG theory in many domains and directions (Sowa, 2000; Hitzler and Scharfe, 2009; Schärfe et al, 2006).
Amine’s K-BO model is based on the use of various conceptual structures provided by CG theory to formulate different kinds of knowledge about concept types, relation types, and individuals. These conceptual structures (CS) are:
• Definition: This CS specifies the necessary and sufficient conditions that define a concept or relation type. It explains how the type is related to its direct superType T, as well as how it differs from the other direct subTypes of T.
Example: Definition for Cactus is
“A cactus is a prickly plant that grows in deserts.”
[Plant : super]-
-attr->[Prickly],
<-pat-[Grow]-loc->[Desert]
(‘attr’ stands for ‘attribute’, ‘pat’ stands for ‘patient of’, ‘loc’ stands for ‘location’. Please refer to CG theory (Sowa, 1984) for a comprehensive understanding of these and other abbreviations used within the conceptual structures.)
• Canon: This CS specifies the necessary constraints for the correct use of a concept type or a relation type.
Canon for concept type Feel is:
“The agent of Feel should be an animal and its object a feeling.”
[Animal]<-agnt-[Feel]-obj->[Feeling]
Canon for relation type Agnt is:
“The relation agnt should relate an Action to an Agent.”
[Action]-agnt->[Agent]
• Situation (Schema): This CS specifies a typical use of a concept type. This is important because for some types, we have a clear and precise definition that clearly defines the type, while in other cases, we simply have a set of typical uses of the concept expressed as typical situations or schemas (Kabbaj et al, 2006; Sowa, 1984; McVee et al, 2005).
Situation for Cactus:
“Most cactuses store water in their stems.”
[Cactus : C]<-pat-[Store]-
-obj->[Water],
-loc->[Stem]<-poss-[Cactus:C]
• CSRule: This CS is presented in the form “if antecedent, then consequence” and is useful for performing inference.
Rule associated to Cactus:
“If a cactus has spiky needles on its surface,
then it is protected from potential herbivores.”
[Cactus:C]-poss->[Needle]-
-QtityOf->[Quantity: many],
-belongTo->[Cactus: C]
-attr->[Spiky]
=>
[Cactus:C]<-pat-[Protected]-from->[Herbivore]-attr->[Potential]
• Individual: This CS provides the description of an individual.
Individual Saguaro2 is :
[Cactus: Saguaro2]-
<-pat-[Grow]-loc->[Desert: Sonoran],
-attr->[Prickly]
Moreover, an ontology in Amine can be connected to multiple lexicons, allowing for the representation of the same conceptual content in various languages. This enables more efficient knowledge sharing and communication across different linguistic and cultural boundaries.
Fig. 3 provides a snapshot of our ontology, showcasing various knowledge structures.
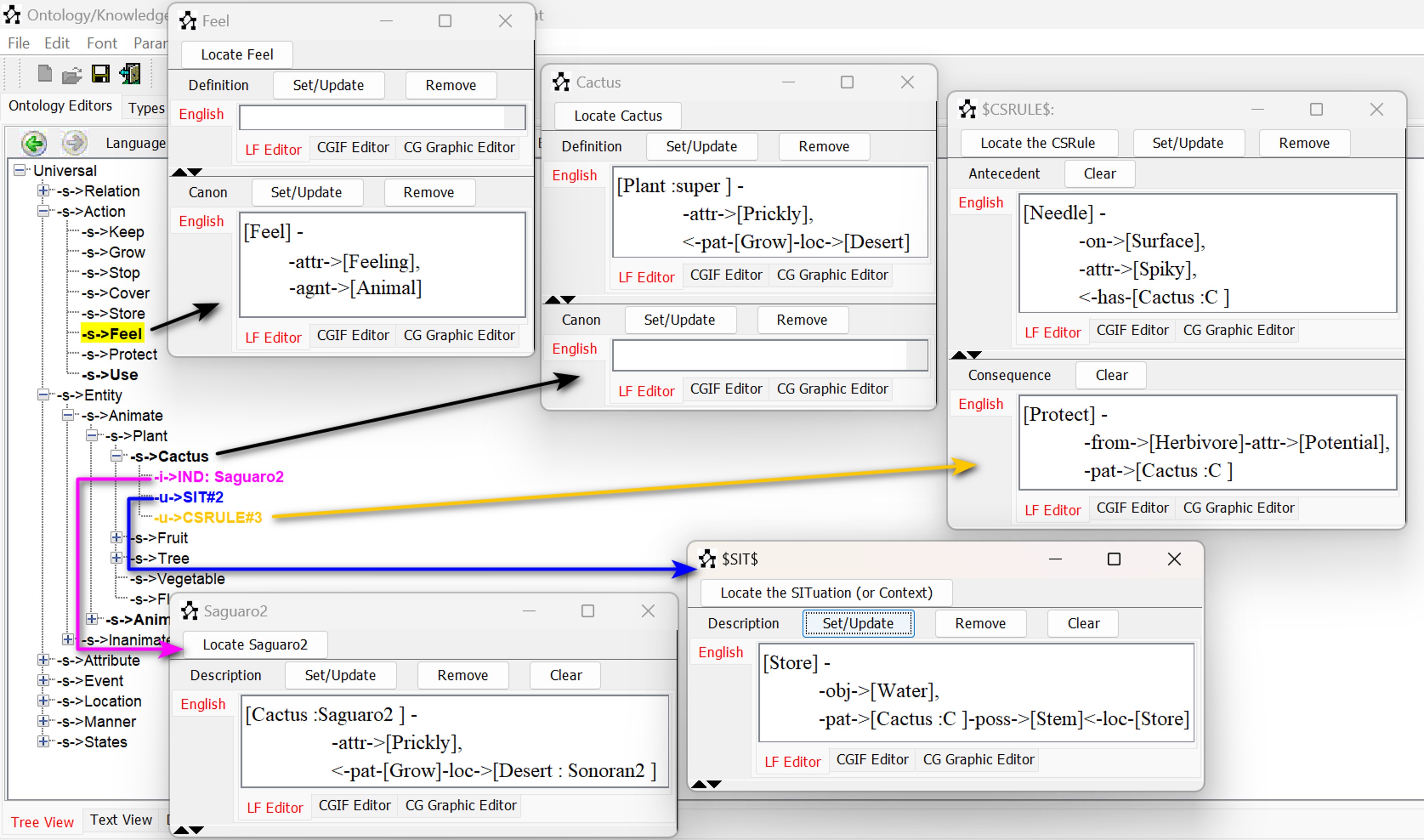 Fig. 3.
Fig. 3.
Example of Conceptual Structures (CS) within an Amine Ontology.
In order to compare the two ontology models based on their usefulness and suitability for the construction and use of a knowledge-based ontology, we used a set of criteria relevant to this research, which were adapted from (Kalibatienė and Vasilecas, 2011). To further reinforce this evaluation, we also considered well-established dimensions from the ontology evaluation literature, particularly the framework proposed by Vrandecic (2009), which has been widely adopted in ontology engineering. These additional quality dimensions—Accuracy, Clarity, Completeness, Adaptability, Consistency, Conciseness, Computational Efficiency, and Organizational Fitness—were used not as standalone criteria but to enrich and justify our chosen framework. In what follows, we outline our criteria and show how each relates to these foundational quality aspects:
• A criterion for semantic and knowledge level: This criterion refers to the ability of an ontology model to represent rich and complex knowledge. We assess the richness of OWL and Amine’s K-BO model in terms of their ability to represent concepts, semantic constraints and any additional knowledge needed in an ontology, and the level of expressivity they provide. This criterion aligns with the dimensions of accuracy (representation of real-world knowledge), completeness (coverage of relevant concepts and relationships), and clarity (communication of intended meaning).
• A criterion for representation level: This criterion refers to the formalism used to represent ontologies and the syntax used to create ontology statements. This involves investigating the OWL syntax variants and CG syntax. It is associated with the dimensions of clarity (readability and interpretability) and conciseness (avoidance of redundancy and minimal ontological commitment).
• A criterion for inference level: This criterion refers to the ability of an ontology model to support automated reasoning and inference. We evaluate the inference capabilities of OWL and Amine, including their support for rule-based reasoning and query answering. This relates to the dimensions of computational efficiency (performance of reasoning tasks) and consistency (absence of contradictions within axioms and between formal and informal components).
• A criterion for automatic ontology construction and knowledge reformulation level: This criterion assesses the ability of an ontology model and associated tools to facilitate the automatic construction of an ontology and support knowledge reformulation. This corresponds to Adaptability (ease of extension and maintenance) and Expandability, ensuring that conceptual structures can be restructured without loss of integrity.
• A criterion for usability level: This criterion evaluates the ease of use of ontology processes and tools, with a focus on the ontology merging process as the example under investigation. This connects with organizational fitness (ease of deployment and integration), and indirectly supports accessibility, stakeholder sharing, and legal/operational compliance.
In this section, we present the results of the comparison between the two ontology models in terms of their ability to represent and reason about knowledge-based ontologies, and discuss these results.
Let us discuss the representation of statements (1, 2 and 4) presented in Fig. 1 in OWL:
- Statement 1: “An ant is a tiny insect. Ants live in large groups in nests made of dirt”.
Class: Ant
SubClassOf: Insect
DatatypeProperty: hasAttribute
Ant: hasAttribute “Tiny”
Annotations:
rdfs:label “Ant”
rdfs:comment “Ants live in large groups in nests made of dirt.”
The first part of statement 1 represents a definition that can be expressed using OWL constructs. For this purpose, two classes are introduced, Ant and Insect, with the Ant class being a subclass of the Insect class. In addition, a datatype property hasAttribute is defined to associate Ant instances with the specific attribute Tiny.
The second part of the statement represents a typical situation for Ant. While OWL provides the means to define the class Ant, it doesn’t provide the means to describe the typical situation. This kind of knowledge can only be included as a comment or annotation, which cannot be used in reasoning or other processing.
- Statement 2: “A ball is used to play many games and sports. Most balls are round”.
This entry does not offer a detailed definition of what a ball is, but it provides insight into how the concept is commonly used and understood. This cannot be represented using OWL constructs.
- Statement 4: “To Eat is to put food into your mouth, chew it, and swallow it. Animals can only eat something that is consumable”.
The first part of this statement represents a definition and can be represented in OWL. The second part specifies universal conceptual constraints on the concept “Eat” “Eat”. In order to represent this knowledge in OWL, one option is to model “Eat” as a relation with constraints on its domain and range. However, this option alters alters the meaning of the concept “Eat”, which is an action, not a relation. If “Eat” is considered an action, the only possibility to represent the above knowledge in OWL is to add it as a comment annotation. Please note that even if the first option is taken into account—considering “Eat” as a relation—the constraints on its domain and range do not impose strict restrictions on the use of the “Eat” relation. Violating a domain or range constraint does not necessarily indicate an inconsistency or an error in the ontology. Users may choose not to adhere to these constraints, and such deviations are tolerated (Rector et al, 2004). To meaningfully enforce constraints on the use of the relation, Shapes Constraint Language (SHACL) should be used (Knublauch and Kontokostas, 2017).
These examples illustrate the case where an ontology should contain knowledge that specifies schemas and canons in addition to definitions. As noted earlier, members of the OWL community recognize this need and are aware that the currently adopted approach of adding them as comments (annotations) is not enough. Indeed, there is a need to use this knowledge in a way that a computer can understand and process, not just rely on annotations meant for human interpretation. This is necessary for both human and software agent use.
Contrary to OWL, Amine’s K-BO model provides various knowledge structures (definition, individual, canon, schema or typical situation, and rule) to express different kinds of ontological knowledge.
Let us consider the formulation of the above statements in Amine’s K-BO model:
- Statement 1: Amine’s K-BO model can offer both a definition and a typical use of the concept Ant, which are respectively presented with the following two conceptual structures:
Definition for Ant is:
[Insect: super]-attr->[Tiny]
A typical situation or schema for Ant is:
[Ant]<-agnt-[Live]-
-partOf->[Group]-attr->[Large],
-loc->[Nest]-madeOf->[Dirt]
- Statement 2: Thanks to the conceptual structure Situation (or Schema), the kind of knowledge in the concept “Ball” can be represented as a situation where the ball is the instrument used in play, and the game is the object of the action:
[Ball]<-instr-[Play]-obj->[Game]
Additionally, the second part of the statement, which contains general information about balls being round, can be expressed using another situation as follows:
[Ball]-attr->[Round]
- Statement 4: For the concept Eat, its definition can be expressed using a CG, and a canon is specified for Eat to state semantic constraints that denote that the agent who performs the action must be an animal (and not something else), and also that the things to be eaten must be food:
[Animal]<-agnt-[Eat]-obj->[Food]
Statements like “Chair eats an apple” or “Human eats metal” are not tolerated in this case.
This conceptual structure adds semantic constraints on the use of a concept or a relation type. There is also a mechanism called CG Canonicity, embedded in the Amine Platform, that checks if the canon of a concept type and a relation type is respected while using them in any CG. This mechanism uses the operation subsume to check that canons of concepts and relations used in a CG g are subsumed by g (For further details, please refer to the documentation on the official website https://amine-platform.sourceforge.net/).
Using OWL, in order to use the statements provided in the mentioned educational dictionary, the most feasible approach would be to incorporate them as annotation properties using the existing rdfs:comment property. In contrast, the Amine K-BO model allows this knowledge to be represented in a machine-understandable format using diverse conceptual structures, significantly increasing its value for use in processes and inference tools supported by the Amine platform.
In OWL, various notations have been proposed and adopted: Functional-syntax (Motik et al, 2009b), RDF/XML syntax (Beckett and McBride, 2004a), Turtle language (Beckett, 2004b), Manchester-syntax (Horridge et al, 2006) and OWL/XML syntax (Motik et al, 2009a). Thus, OWL has different syntax variants and each variant has its own strengths and weaknesses (Horridge, 2010). While some users may find certain syntaxes easier or more intuitive than others, learning and writing complex knowledge bases in OWL can be challenging (Warren et al, 2019).
Let us illustrate this criterion with the expression of Statement 3 in OWL and then in Amine’s K-BO model:
- Statement 3: “Banana: A banana is a kind of fruit. Banana plants grow in hot countries”.
Here is its expression using Turtle syntax, since it is one of the most commonly used syntaxes.
@prefix ex: <http://example.com/>.
ex:Banana a owl:Class;
rdfs:subClassOf ex:Fruit;
rdfs:subClassOf [ a owl:Restriction;
owl:onProperty ex:growsIn;
owl:someValuesFrom [ a owl:Class;
owl:intersectionOf (
ex:Country ex:Hot ) ] ].
ex:Fruit a owl:Class.
ex:Country a owl:Class.
ex:Hot a owl:Class.
In the Amine ontology model, Statement 3 can be represented as follows: The first part of the statement is specified in the taxonomy. The second part, “A banana grows in a hot country”, is specified as a typical situation of the concept Banana:
[Banana]<-pat-[Grow]-loc->[Country]-attr->[Hot]
This conceptual graph states that Banana is the patient of the action Grow, which is taking place in a Country that has the attribute of being Hot. The above notation is compact and readable by both humans and machines.
The above example demonstrates how CG syntax enables both humans and machines to read, understand, and interpret knowledge easily.
The research conducted on reasoning in OWL since its release is widely acknowledged for its quantity and quality (List of OWL Reasoners, 2020; Parsia et al, 2017). Concerning the Amine K-BO model, typical situations or schemas can be represented either as a declarative statement (a CG), as previously observed in subsection 3.1, or as implications represented as rules. Amine’s ontology model incorporates universal and/or commonsense rules within the ontology. Amine’s inference engine uses these rules to perform different kinds of reasoning: deductive, abductive, and analogical. This kind of reasoning is not provided by OWL.
To illustrate this point, let’s extend our set of examples and consider the context of autonomous cars and knowledge related to a driver’s background knowledge. This knowledge corresponds to typical situations that should be expressed as rules, and the target application should be able to account for this additional knowledge, such as traffic jams during workdays or slowing down near schools during weekdays. These types of implicit rules are not represented in OWL using axioms, while they can be expressed in Amine’s ontology model using rules that are integrated into the ontology.
Here is an example of such rules represented in Amine’s K-BO model:
• If a pedestrian is waiting at a crosswalk, and there is no traffic signal present, then a car should stop and allow the pedestrian to cross.
[Pedestrian:p]<-agnt-[Wait]-loc->[Crosswalk]-without-> [TrafficSignal]
=>
[Car]<-agnt-[Stop]-allows->[Cross]-agnt->[Pedestrian: p]
The inference approaches implemented in the Amine platform, such as deductive, abductive, and analogical inferences, are specifically designed for the purpose of reasoning over these rules. They take a new description as input, and based on the knowledge (rules) stored in the ontology, provide a suitable inference result.
By introducing a single fact or description within a specific context, users can trigger the activation of multiple rules. Fig. 4 demonstrates how the activation of rules in a specific order forms a chain of deductive reasoning.
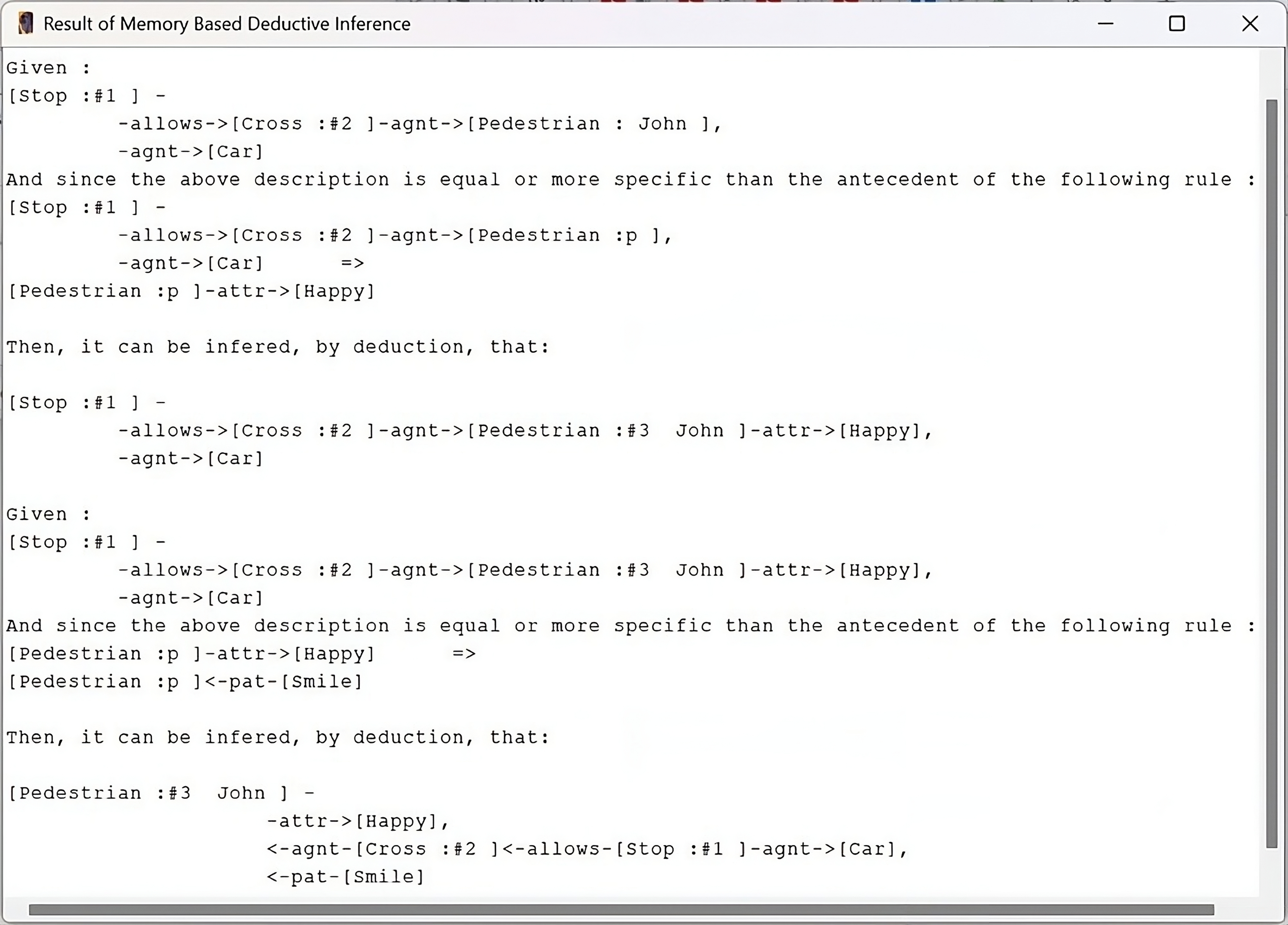 Fig. 4.
Fig. 4.
Deductive reasoning using rules integrated in the ontology.
In our ontology, we have established two rules within the concept “Pedestrian”.
Rule 1: If a car stops and allows a pedestrian to cross,
then the pedestrian feels happy
[Car]<-agnt-[Stop]-allows->[Cross]-agnt->[Pedestrian: p]
=> [Pedestrian: p]<-agnt-[Feel]-attr->[Happy]
Rule 2: If a pedestrian feels happy, then the pedestrian smiles
[Pedestrian: p]<-agnt-[Feel]-attr->[Happy]
=> [Pedestrian: p]<-pat-[Smile]
When the following fact is given to Amine:
Fact: A car stops and allows the pedestrian John to cross
[Car]<-agnt-[Stop]-allows->[Cross]-agnt->[Pedestrian: John]
The deductive chain is activated, allowing for the execution of Rule 1. As a result, Amine deduces that the pedestrian John is happy. This, in turn, activates Rule 2, leading to the deduction that he is not only happy but also smiling.
This chain enables users to extract valuable insights and make informed decisions by progressively building upon the initial fact or description.
While both Amine and OWL have different approaches to inference and reasoning, they each offer distinct strengths and can be beneficial for different purposes.
Instead of manual construction, there may be a need for automatic and incremental construction of an ontology.
To illustrate this point, let us consider the following scenario: there is an existing taxonomic ontology, and the user intends to incorporate three new types along with their corresponding definitions:
• Pelican is a bird with a big beak that eats fish.
• AnimalScientist is a scientist who studies bird with a big beak that eats fish.
• HardAnimalScientist is a scientist who studies bird with a big beak that eats fish in a rigorous manner.
The subsequent analysis will focus on the automatic integration, specifically the classification, of these new definitions into the preexisting ontologies of OWL and Amine.
In OWL, the reasoner can be used to automatically infer new knowledge based on the existing concepts and relationships in the ontology. The classification process starts with the reasoner analyzing the TBox, which contains the axioms and definitions of the ontology, and then inferring the classes and relationships between them. The reasoner uses the TBox to create a classification hierarchy, where each class is a subset of its parent class. Next, it analyzes the ABox, which contains the assertions about individual instances of concepts in the ontology, to classify these instances. Properties and relationships defined in the TBox are also used to determine the class membership of each instance.
To add the previously introduced definitions using classification in OWL, we should first provide the appropriate axioms for our classes and then run a reasoner:
# Pelican is
Class: Pelican
EquivalentTo: (eats some Fish)
and (hasPart exactly 1 Beak
and (hasSize value “Big”))
SubClassOf: Bird
# AnimalScientist is
Class: AnimalScientist
EquivalentTo: studies some (Bird and (eats some Fish)
and (hasPart exactly 1 Beak
and (hasSize value “Big”)))
SubClassOf: Scientist
# HardAnimalScientist is
Class: HardAnimalScientist
EquivalentTo: (studies some (Bird and (eats some Fish)
and (hasPart exactly 1 Beak
and (hasSize value “Big”)))
and (hasManner value “Hard”))
SubClassOf: Scientist
The reasoner, when given the above axioms, will be able to infer the classification hierarchy for the ontology based on the concepts and relationships defined in the TBox. Specifically, the reasoner will be able to infer that HardAnimalScientist is a subclass of AnimalScientist because they share a common part of the definition.
While the reasoner can make numerous inferences based on the axioms and relationships defined in the ontology, it does not reformulate definitions to facilitate user understanding. For instance, within the most utilized ontology editor, Protégé (Version 5.6.4. Developed by the Stanford Center for Biomedical Informatics Research, Stanford University School of Medicine, USA) (http://protege.stanford.edu), the reasoner works by first taking an existing ontology and then rearranging (or classifying) it according to the axioms it contains, producing a new inferred ontology hierarchy.
Amine, however, provides support for an automatic and incremental construction of an ontology, accompanied by the reformulation of the knowledge, using the classification or generalization processes.
Let us illustrate the classification-based integration process in Amine with the same example as before, and formulate the earlier definitions according to Amine:
“Pelican is a bird that has a big beak and eats fish.”
[Bird:super]-
<-agnt-[Eat]-obj->[Fish],
-poss->[Beak]-attr->[Size = big]
“AnimalScientist is a scientist who studies birds that have a big beak and eats fish.”
[Scientist :super]<-agnt-[Study]-obj->[Bird]-
<-agnt-[Eat]-obj->[Fish],
-poss->[Beak]-attr->[Size = big]
“HardAnimalScientist which refers to a scientist who studies birds that have a big beak and eats fish in a rigorous manner.”
[Scientist:super]-
<-agnt-[Study]-obj->[Bird]-
<-agnt-[Eat]-obj->[Fish],
-poss->[Beak]-attr->[Size = big];
<-agnt-[Work]-manr->[Hard]
Amine starts by integrating the concept Pelican with its definition in the ontology.
The classification of the concept type AnimalScientist requires the identification of the relevant concepts within its definition. Scientist and Bird are the pertinent concept types. As a result of the classification, its definition is automatically reformulated:
AnimalScientist is:
[Scientist: super]<-agnt->[Study]-obj->[Pelican]
The classification process recognizes that the definition of AnimalScientist contains the definition of Pelican. This definition is then simplified by replacing the full definition of Pelican with the concept Pelican itself. This is a case of knowledge reformulation during classification. The user may infer that this AnimalScientist is effectively a PelicanScientist and may choose to add that as a synonym. This type of knowledge reformulation is not provided by OWL and its reasoners.
Similarly, integrating the concept HardAnimalScientist with its definition leads to its reformulation and the discovery that it is a subclass of AnimalScientist:
HardAnimalScientist is:
[AnimalScientist:super]<-agnt-[Work]-manr->[Hard]
Regarding the generalization-based integration process, available exclusively in the Amine ontology model, there is the ability to discover a new category by identifying commonalities between multiple situations or definitions. For instance, starting with specific concepts like Car, Truck, and Airplane, the generalization-based integration process can lead to the identification of the more general category they belong to, which is ‘Vehicle’. To illustrate this possibility, let us consider a taxonomic ontology and the integration of three definitions, as follows:
Definition for Car is
[Human]<-agnt-[Drive]-obj->[Machine:super]-loc->[Road]
Definition for Truck is
[Human]<-agnt-[Drive]-obj->[Machine:super]-att->[Size: Big]
Definition for Airplane is
[Human]<-agnt-[Drive]-obj->[Machine:super]-loc->[Sky]
Fig. 5a shows the result of the integration of the concept Truck. The automatic integration of the concept Car leads to the recognition of a common pattern: humans drive a particular subset of machines (See Fig. 5b).
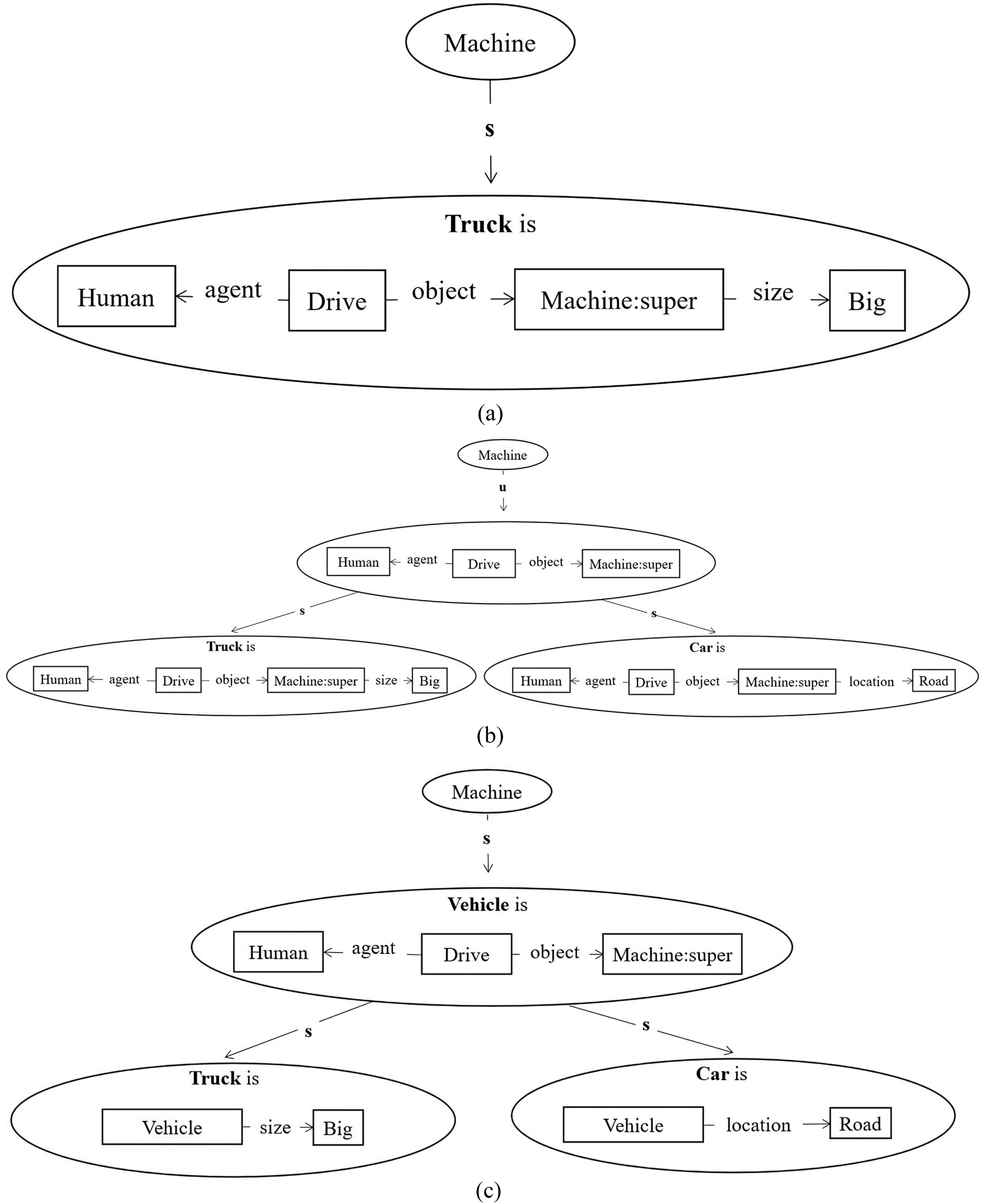 Fig. 5.
Fig. 5.
Generalization process in Amine Platform. (a) The integration of the concept Truck. (b) Generalization process in Amine Platform. (c) The potential creation of the new type Vehicle with knowledge reformulation.
Upon the integration of the definition of Airplane, Amine identifies that the situation “Human Drive Machine” is common to all three classes, and it is possible to consider a scenario where it suggests treating it as a definition of a new concept. If the user responds affirmatively—accepting the shared generalization as the basis for a new concept definition, such as Vehicle (See Fig. 5c)—then knowledge reformulation will occur. If this is indeed the case, the generalization (treated as a formal situation) is reformulated as a definition, which leads automatically to a reformulation of the three nodes. For instance, the definition of Car will be reformulated as follows:
[Vehicle:super]-loc->[Road]
Usability encompasses various processes and tools provided for managing ontologies, among which ontology merging is particularly significant. Ontology merging is a critical issue that has been at the forefront of concerns for researchers in the field of semantic web. As the amount of data available online continues to grow, the need for efficient merging of ontologies becomes increasingly important. Fortunately, there has been a surge in research efforts devoted to tackling this problem (Euzenat et al, 2011), with many promising solutions currently under development.
For OWL ontology, especially regarding the well-known tool Protégé (Musen, 2015), several plugins were available in the past to facilitate ontology merging. However, many of these plugins have become deprecated over time, e.g., SMART (Noy and Musen, 1999), AnchorPROMPT (Noy and Musen, 2001) and PROMPT (Noy and Musen, 2000).
Currently, Protégé offers a basic integrated merging option that combines a pair of ontologies, resulting in a merged ontology containing all concepts present in both ontologies. The user can then apply a reasoner to resolve inconsistencies. This option is specifically designed to merge two separate ontologies while maintaining the distinctiveness and individuality of the original ontologies. This means that, for instance, if we have two ontologies, A and B, and both ontologies have a distinct concept of “FamilyCar” (See Fig. 6), the resulting merged ontology will still contain both individual members, namely A.FamilyCar and B.FamilyCar (See Fig. 7).
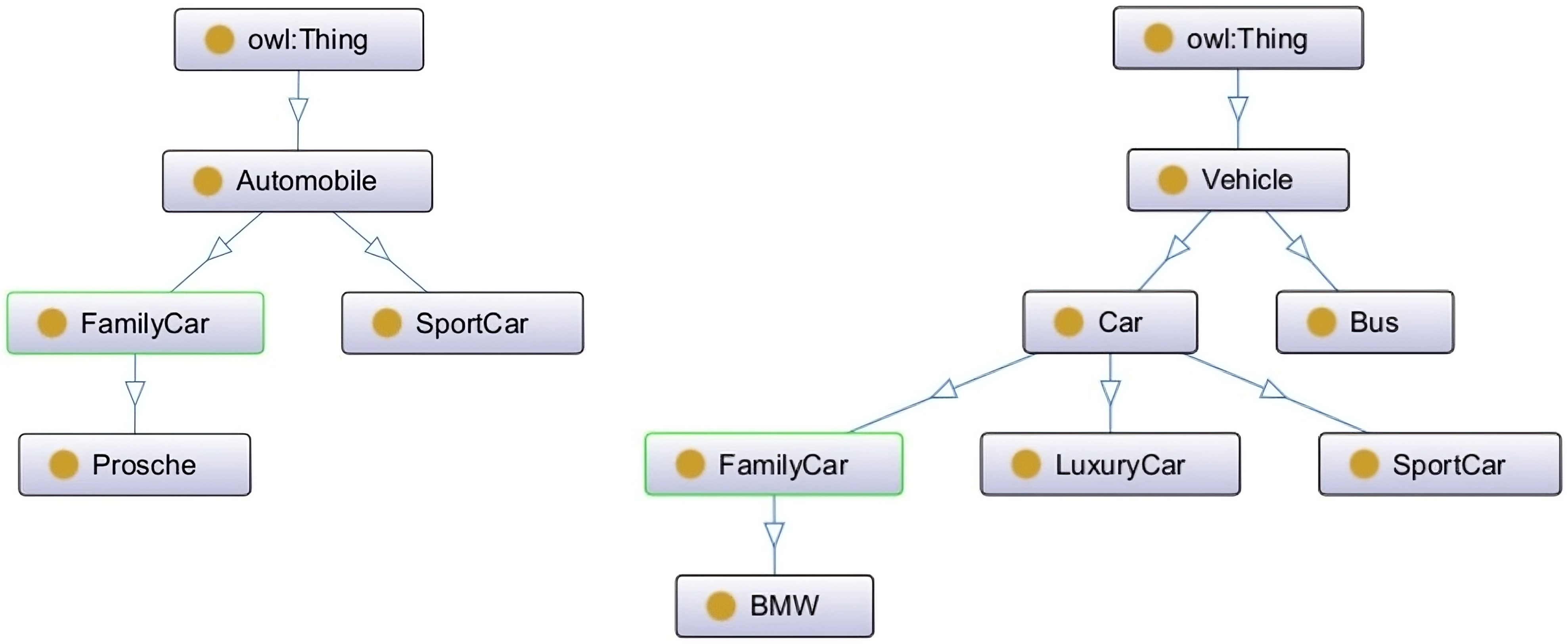 Fig. 6.
Fig. 6.
Source ontologies.
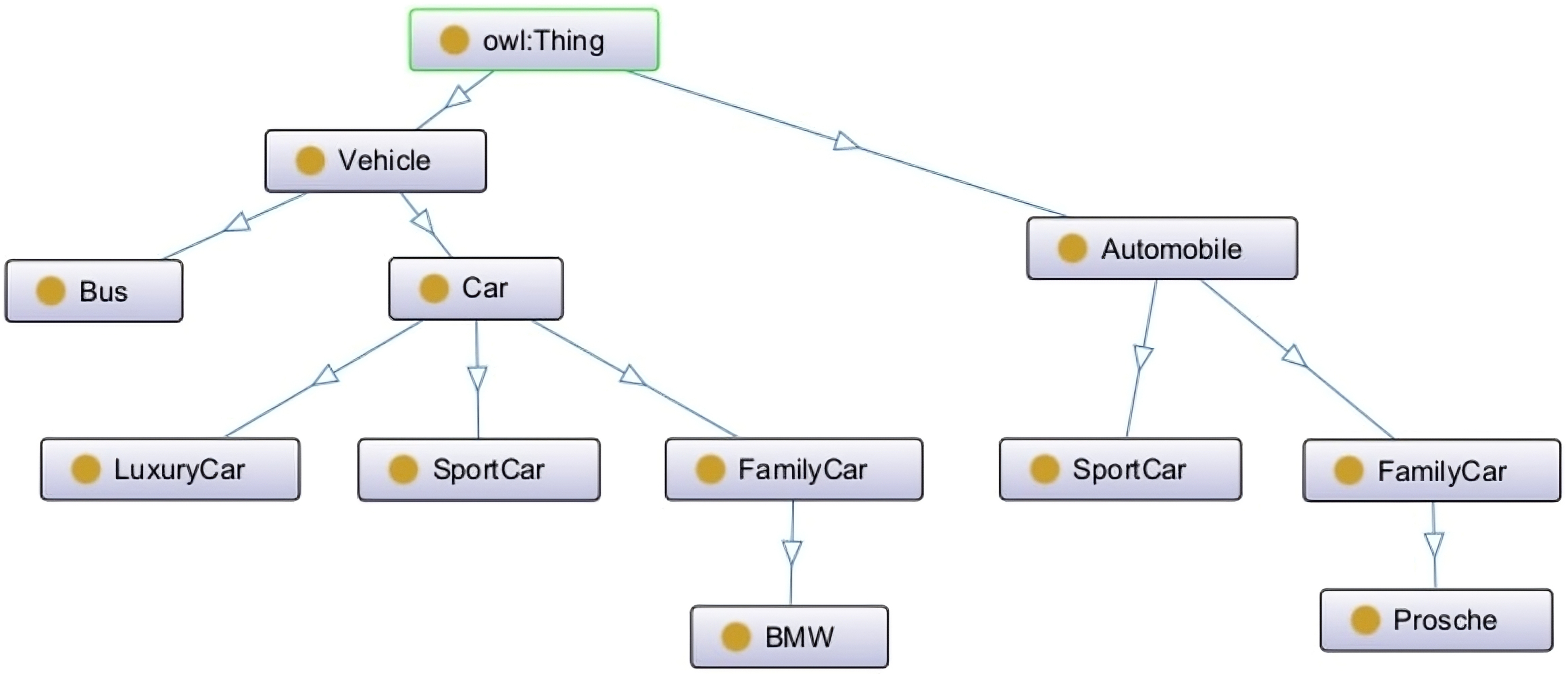 Fig. 7.
Fig. 7.
Merged ontology resulted using Protégé.
On the other hand, the Amine platform has recently introduced an integrated tool for ontology merging called AmineMerger (Smaili, 2022). This tool performs consistent ontology merging, offering a user-friendly solution for those who prefer not to rely on additional tools such as a reasoner, as required in Protégé. It checks for similarities at multiple levels during the merging process to avoid inconsistencies. Additionally, it is enriched with parameters that enable users to identify their specific merging needs more precisely when working with different conceptual structures (See Fig. 8).
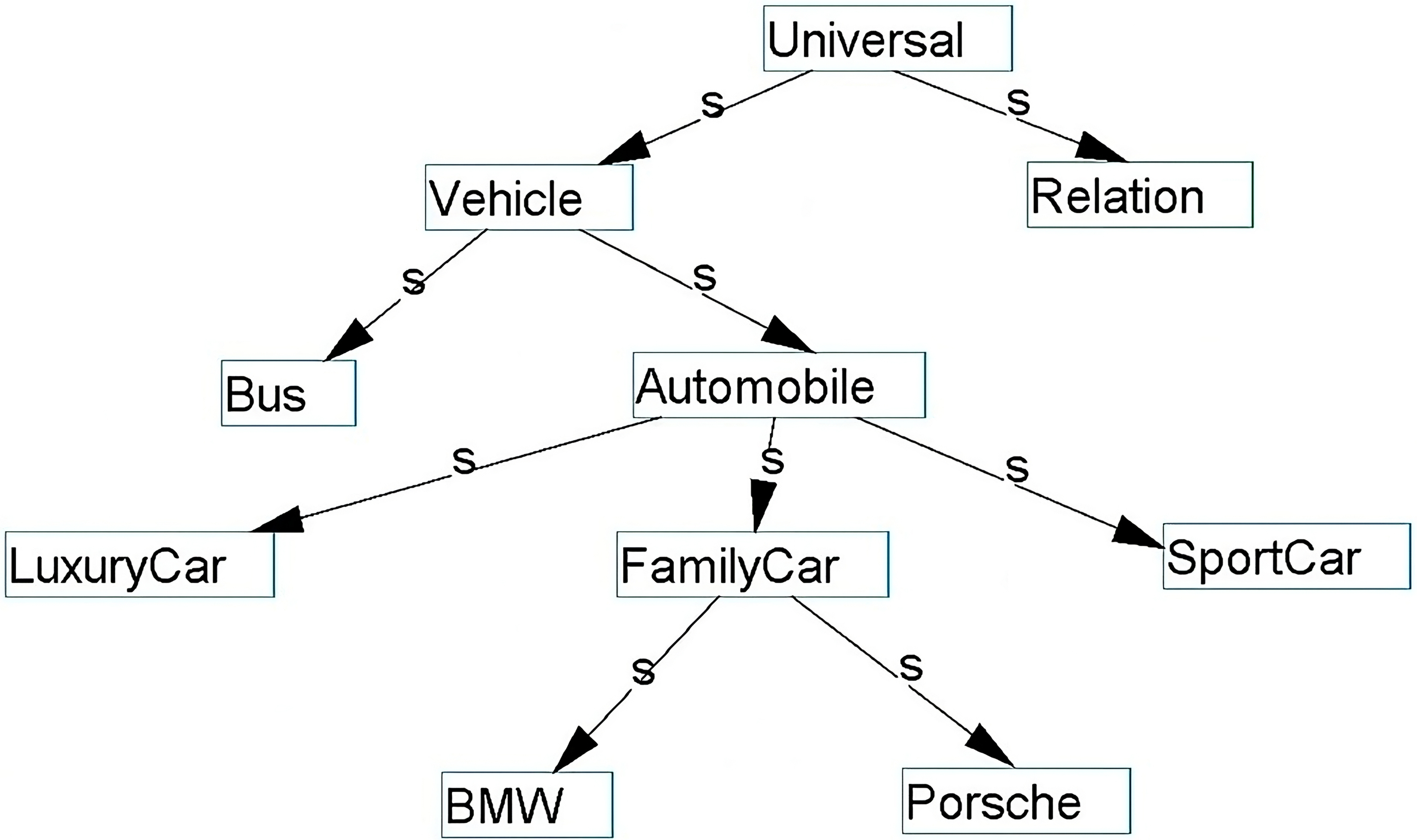 Fig. 8.
Fig. 8.
Merged ontology resulted using AmineMerger (Car is considered a synonym for Automobile).
While standalone ontology languages like OWL may require users to obtain and use separate tools, potentially reducing overall usability, the integration of tools in the Amine platform enhances the usability and efficiency of the processes, notably the ontology merging process.
Together, the Amine ontology model and platform provide a comprehensive solution for the development of knowledge-based ontologies that can be used as a base for many applications, all within one compatible platform.
To clearly demonstrate the practical benefits and enhanced expressiveness of the Amine ontology model, we provide a detailed overview of a prototype Question-Answering (QA) application. This subsection outlines each phase of the QA process, showcasing the expressive capabilities of the Amine platform and its contribution to real-world educational scenarios.
Fig. 9 depicts the current architecture of our QA application.
 Fig. 9.
Fig. 9.
Q/A current architecture.
• Description: We began by selecting a dataset comprising ontologies created by students at our institution. The broader dataset, referred to as Amazing, includes approximately 1000 entries derived from the dictionary My First Incredible Amazing Dictionary, each accompanied by a visual representation.
• Sample Creation: A curated sample of 89 entries (about 12% of the full dataset) was selected for this case study.
• Selection Criteria: These students underwent focused practical training in Amine ontology creation, ensuring semantic richness and clarity of their contributions.
• Description: We used the AmineMerger tool to merge the individual ontologies into a consistent and unified knowledge base, addressing semantic heterogeneity and enabling broader reasoning.
We developed natural language questions simulating real educational queries. These were manually translated into Conceptual Graphs (CGs) and then processed by Amine processes. Examples include:
• What animals eat grass and live on farms?
• Can a penguin fly?
Each query was:
(1) Expressed in natural language.
(2) Converted to CG format (ACE (Attempto Controlled English)-to-CG can automate this in the future).
(3) Processed using appropriate AMINE modules (search, inference, canon checking, etc.).
Concrete demonstrations are provided in Table 1, which links each question to the applied Amine processes and their corresponding results.
| ID | Question | CG Representation | AMINE Processes |
| 1 | What animals eat grass and live on farms? | [Animal:?x]- <-agnt-[Eat]-obj-> [Grass], <-agnt-[Live]-loc-> [Farm] |
Search |
| Obtained Result: | 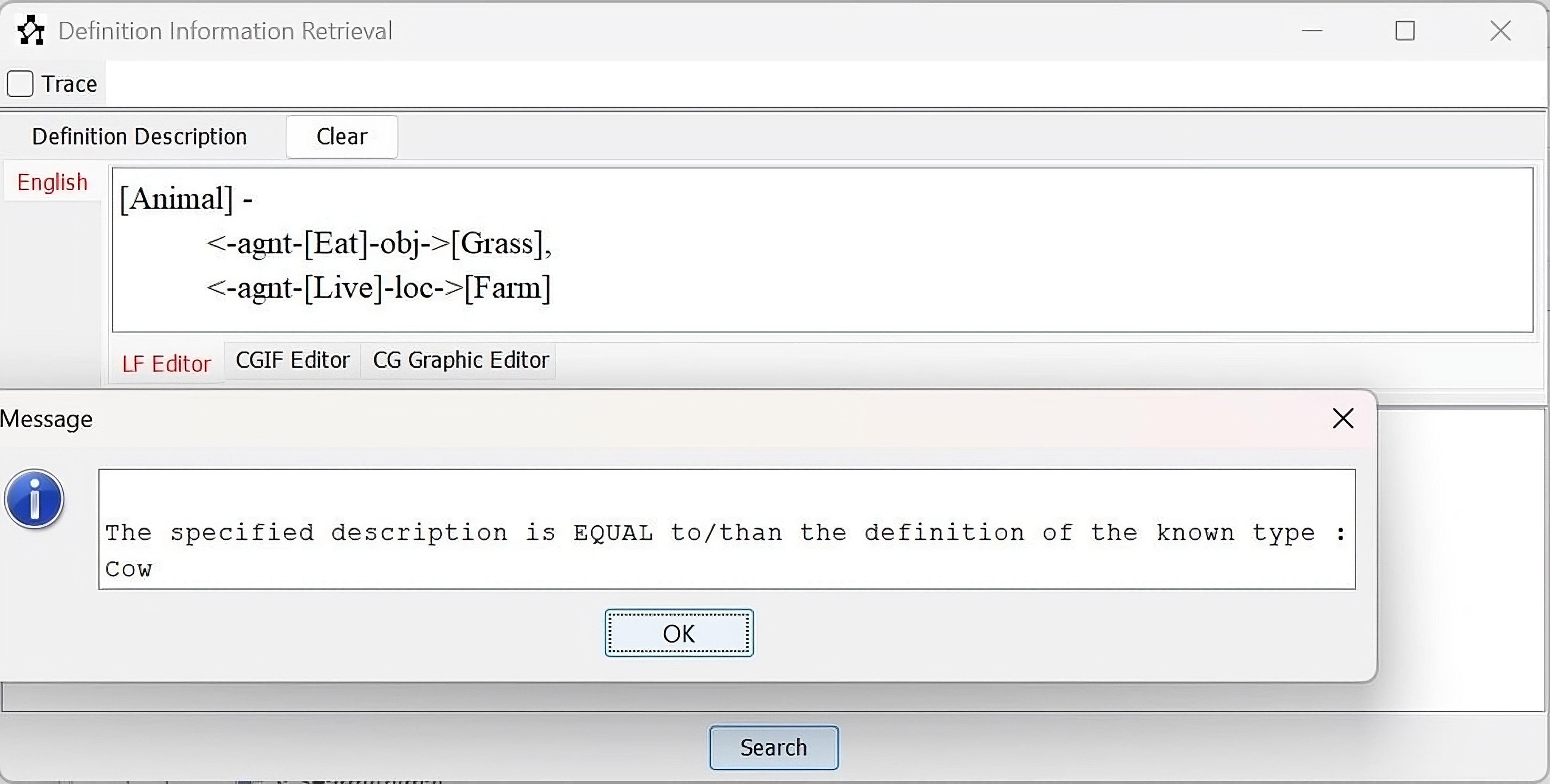 | ||
| 2 | Penguin flies. | [Penguin] -ability-> [Fly] | Canon Check |
| Obtained Result: | 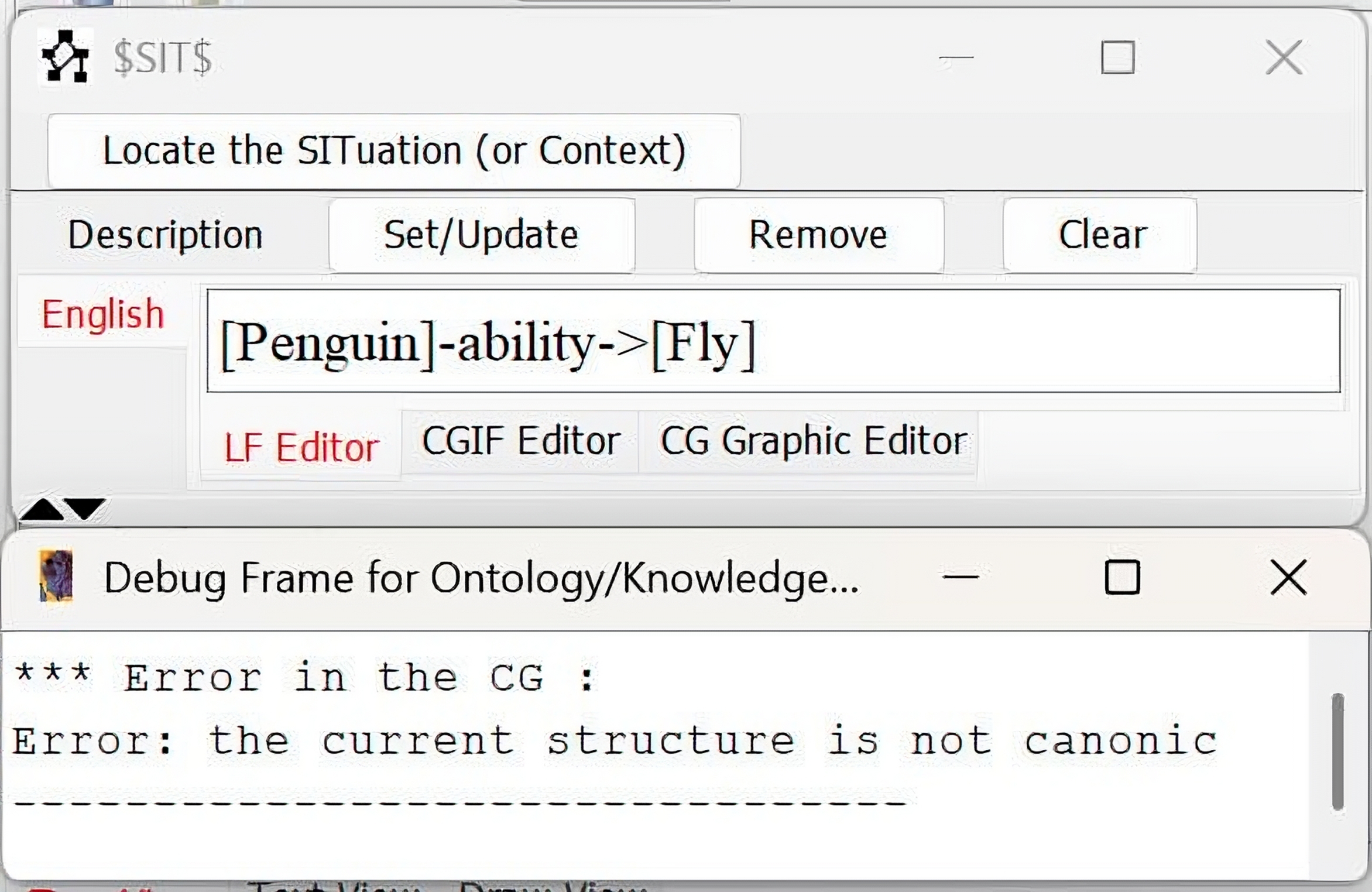 | ||
| Note: Here, the user (child) states that a penguin flies. AMINE checks this assertion against the ontology, and since a canonical constraint indicates otherwise, it returns a semantic inconsistency. | |||
| 3 | Tell me more (Elaborate) about the cow that lives on the farm. | [Cow]- <-agnt-[Live]-loc->[Farm] | Elaboration |
| Obtained Result: | 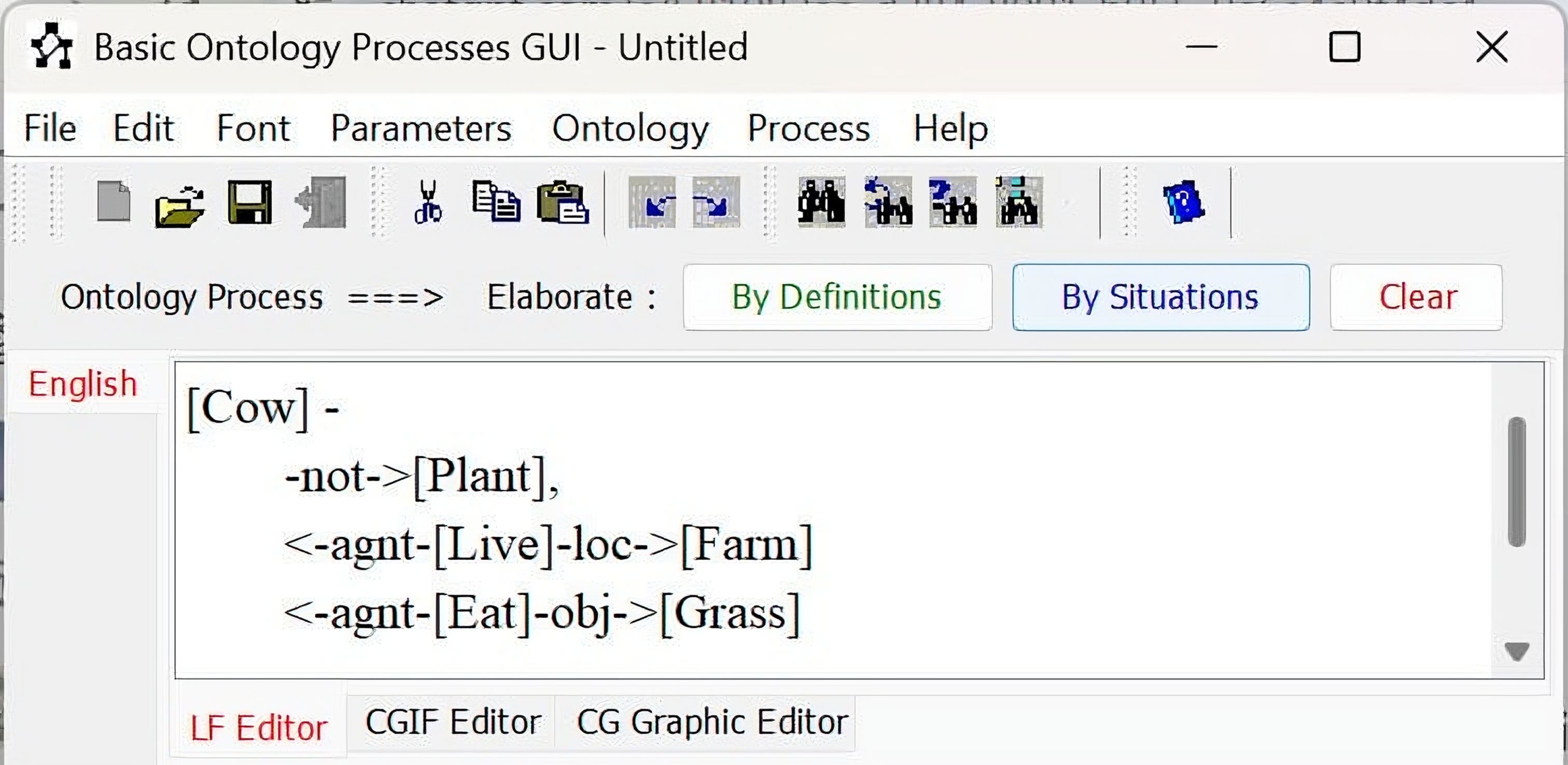 | ||
| Note: If the end user (child) asked for more information about one concept, AMINE elaborates that concept and provides all the information it has about it in the ontology. | |||
| 4 | Animal has wings. | [Animal]- has->[Wings] | Elicitation |
| Obtained Result: | 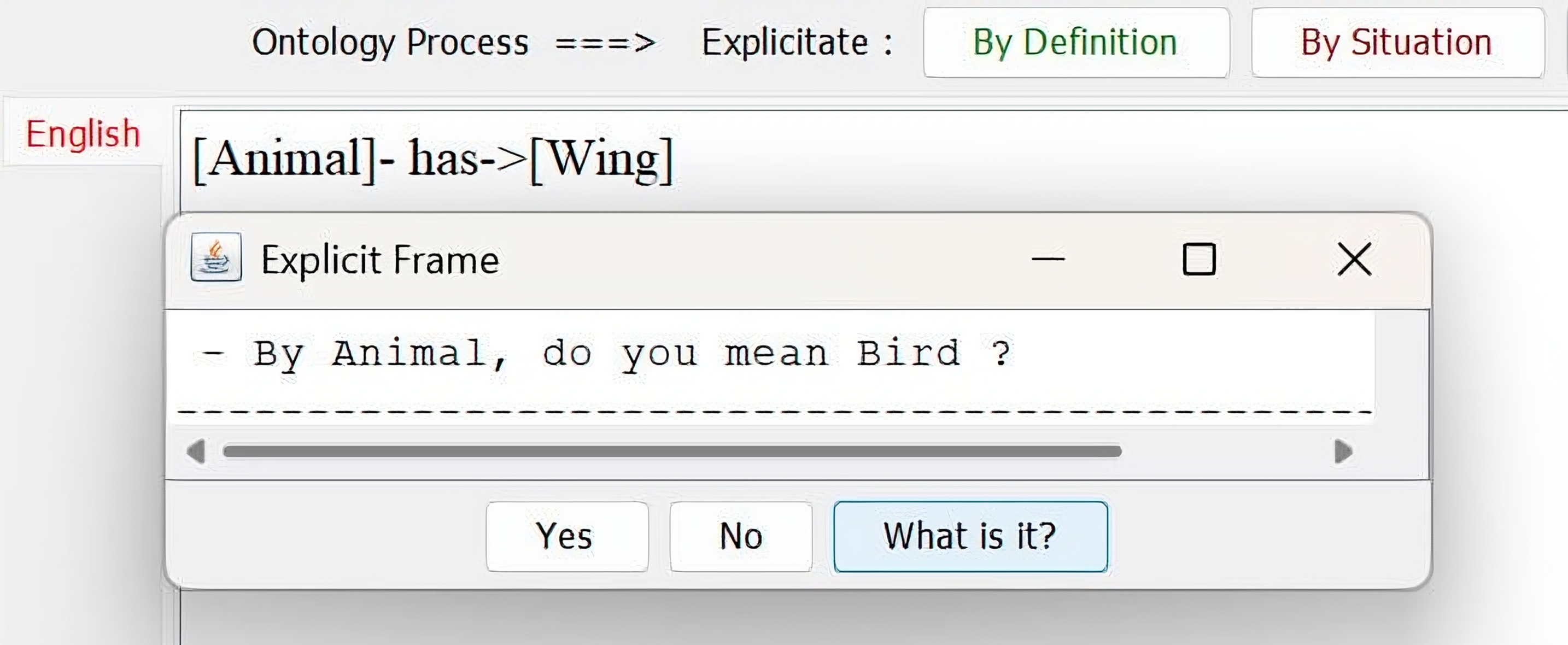 | ||
| Note: After we click Yes, we get the result | |||
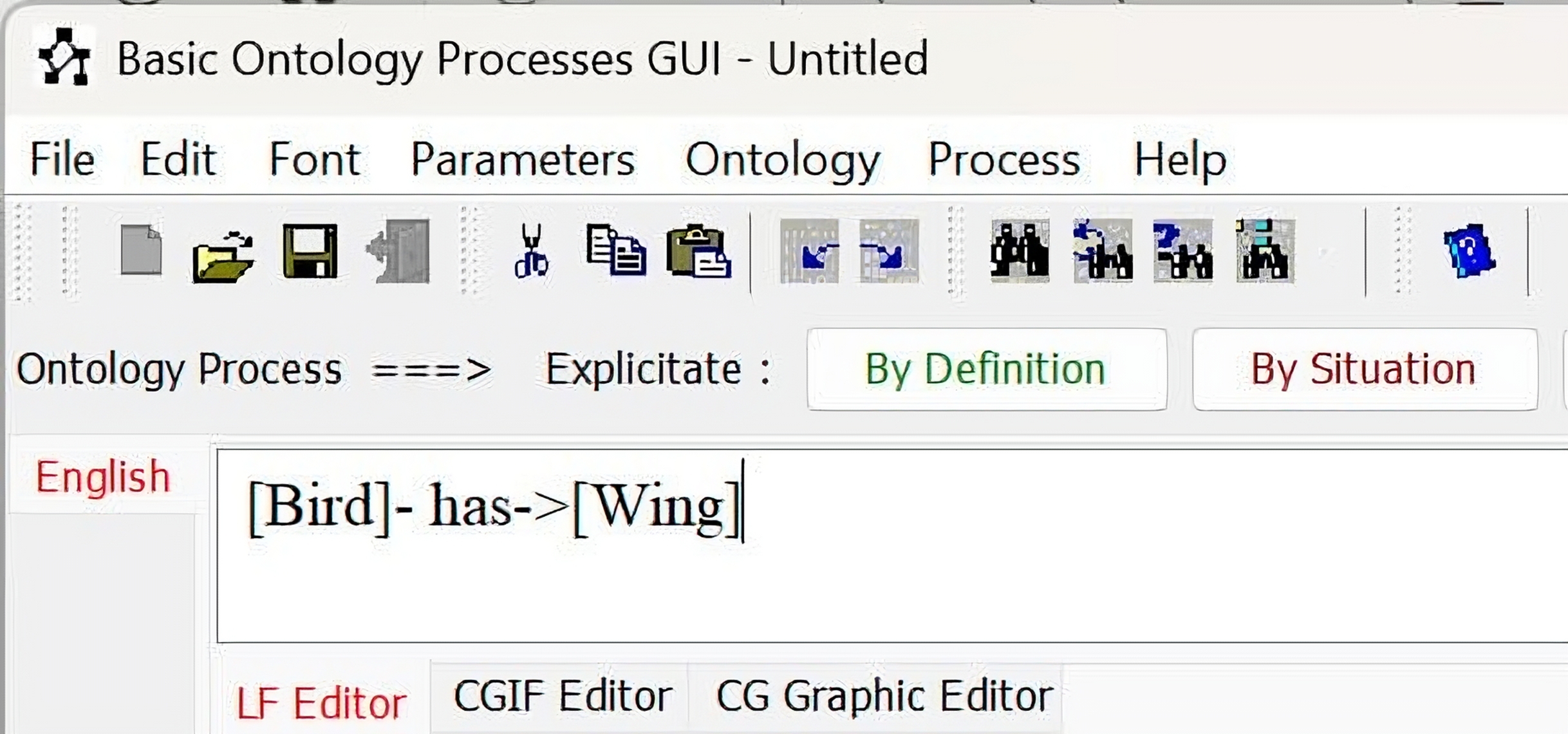 | |||
CG, Conceptual Graph.
Before detailing the results in Table 1, we briefly introduce each process to provide a clear understanding of the mechanisms employed.
• Search Processes (Situations retrieval): Retrieve matching situations within the ontology. Definition: This process locates relevant concepts and structures (e.g., situations, types) in the ontology that match or are semantically close to a given conceptual graph. It doesn’t merely answer yes/no but classifies the description in the ontology’s hierarchy by retrieving:
- Fathers (more general descriptions), - Children (specialized ones), - Equivalents. Use: Situate a new or queried graph within existing ontology knowledge using classification-based integration. • Inference Rules (Deductive, Abductive, Analogy):
- Deductive Inference: Logical deductions based on stored rules and information. Definition: Given rules stored in the ontology (in CSRule form), deduction applies when a new description subsumes the antecedent of the rule. The consequent part of the rule is joined to the description to form a new expanded graph. Use: Apply logical rules to infer new knowledge. See Fig. 4 for more details. - Abductive Inference: Deriving explanations by activating rules whose consequences match new descriptions. Definition: Abduction works in reverse: if a consequence is observed (i.e., a graph matches the consequence of a rule), AMINE infers the antecedent as a plausible explanation. Use: Generate explanatory hypotheses from effects. Example:
🞷 Rule: If a person has cancer, then the person suffers. 🞷 Fact: A person suffers. Result: By abduction, we infer that the person may have cancer. - Analogical Inference: Reasoning by analogy from structurally similar cases. Definition: Analogical reasoning identifies structural similarities between two CGs and transfers information from one (source) to another (target), while preserving canonical constraints. Use: Infer by analogy using conceptual similarity. Example:
🞷 Rule: If a human wants to cut an apple, they use a knife. 🞷 Given: A woman wants to cut an orange. Result: By analogy, the woman needs a knife to cut the orange. • Canon Validation (Semantic constraints checking): Checking semantic constraints and validating conditions. Definition: This operation checks whether a CG conforms to the canons (semantic constraints) of its types and relations. If a graph violates the canonical definitions, it is flagged as semantically invalid. Use: Semantic checking, constraint validation. • Elaboration/Elicitation (Semantic clarifications):
- Elaboration: Incrementally enriching descriptions by incorporating relevant definitions and situations. Definition: Enriches a description by incorporating additional information:
🞷 Deductive elaboration: Adds knowledge from formal definitions of types. 🞷 Plausible elaboration: Adds information based on schemas representing typical behavior. Use: Make an incomplete or vague CG more informative. - Elicitation: Enhancing precision through interactive question-and-answer interaction. Definition: An interactive process that helps refine a vague conceptual graph by asking binary (yes/no) questions, leading to more precise, detailed, and explicit representations. Use: Supports the handling of uncertain or incomplete input, especially relevant for child users in educational settings.
Building on previous work in semantic parsing (Nasri et al, 2011), the pipeline is being enhanced to include full Natural Language Processing (NLP) support:
• User submits a question in natural language.
• Semantic parser converts it to CG.
• AMINE inference and reasoning modules process it.
• The system generates an answer in natural language.
Fig. 10 illustrates how natural language questions are automatically converted into CG format.
 Fig. 10.
Fig. 10.
Example of Natural Language Processing (NLP) using AMINE.
We are currently working on:
• Full NLP pipeline integration (see Fig. 10).
• Interactive graphical user interface (GUI) for child-friendly interaction.
• Application development using Prolog+CG for executable, logic-based operations over conceptual graphs.
Fig. 11 depicts the future architecture of our Q/A application.
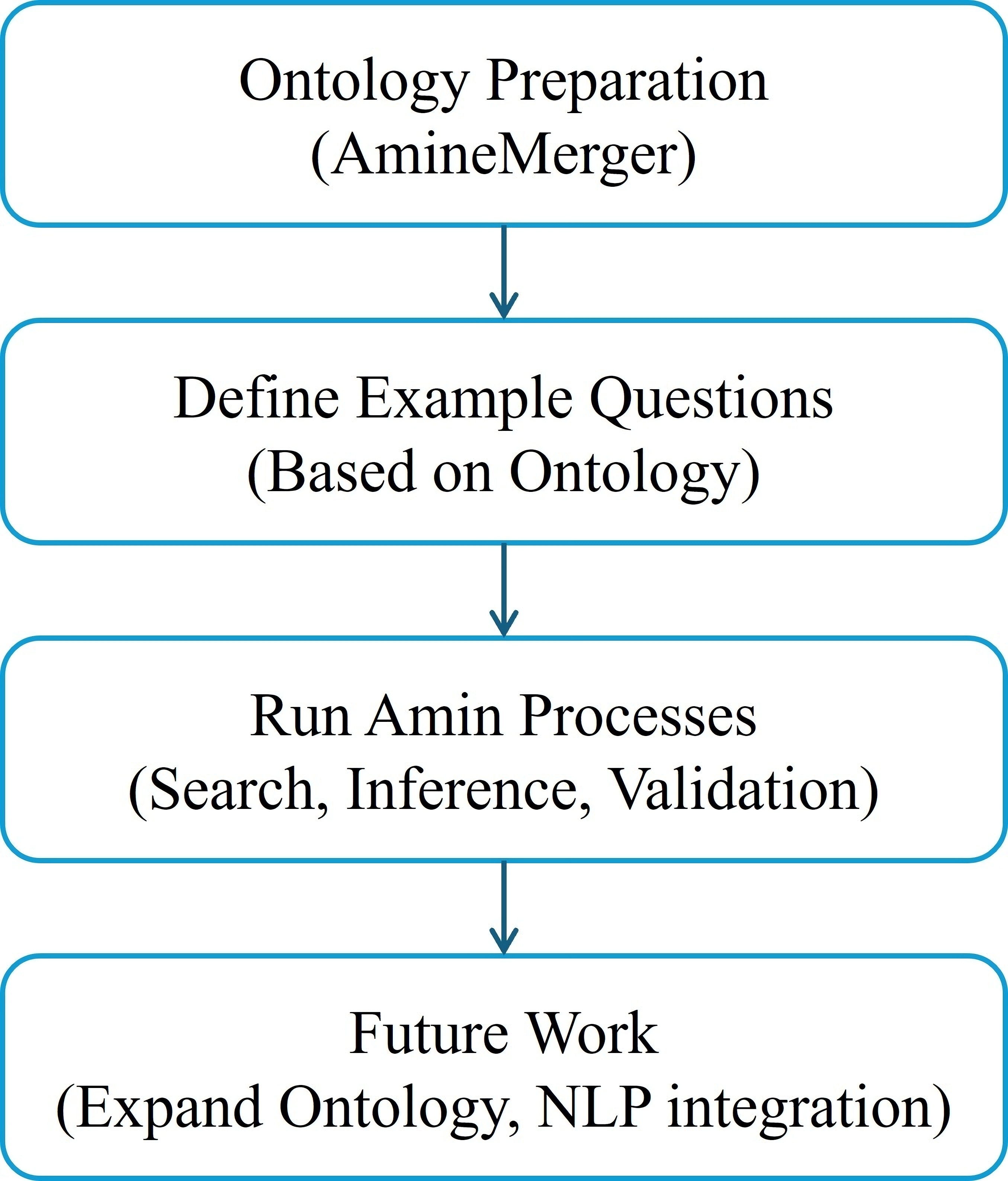 Fig. 11.
Fig. 11.
Q/A future architecture.
This case study underscores Amine’s practical advantages and its expressiveness, particularly in educational (QA) contexts.
This paper discusses the requirement for a knowledge-based ontology, illustrated by the need to develop an ontology for the educational dictionary “My First Incredible Amazing Dictionary”.
The Amine ontology model used in this case, which is based on Conceptual Graph (CG) theory, offers various conceptual structures for expressing and structuring knowledge in a powerful and readable way. The use of the Amine knowledge-based ontology model within the Amine platform also provides an environment for the development of ontology-based and knowledge-based applications.
This study has demonstrated the potential of using the Amine ontology model in ontology development, which could have significant implications for the representation of knowledge in various educational applications. Additionally, it highlights the importance of carefully considering the choice of ontology modeling language in ontology development projects.
Future work will explore the potential for translating OWL ontologies to the Amine ontology model to further expand its applicability in similar contexts.
K-BO, Knowledge-Based Ontology; CG, Conceptual Graph; QA, Question Answering; OWL, Web Ontology Language.
All data and materials used in this study are either publicly available or derived from “My First Incredible Amazing Dictionary”, used under fair use exceptions for non-commercial academic research.
NS: Conceptualization, Formal analysis, Methodology, Investigation, Data curation, Writing—original draft. AK: Software, Validation, Writing—review and editing, Supervision, Project administration, Resources. Both authors read and approved the final manuscript. Both authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
We express our gratitude to DK Limited for allowing us to use “My First Incredible Amazing Dictionary” content in our research paper, adhering to copyright exceptions for non-commercial research and private study. We also thank Mr. Karim Bouzoubaa for his valuable remarks.
This research received no external funding.
The authors declare no conflict of interest.
This manuscript was written and revised using traditional human academic methods. However, AI-based tools (e.g., OpenAI’s ChatGPT) were used only to assist in language polishing and summarization, under human supervision. No generative content was accepted without critical review and editing by the authors.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.