

 , Can Dinç 1,*
, Can Dinç 1,* , Ergün Şengün 1, Selen Doğan 1, Murat Özekinci 1, Nasuh Utku Doğan 1, İnanç Mendilcioğlu 1
, Ergün Şengün 1, Selen Doğan 1, Murat Özekinci 1, Nasuh Utku Doğan 1, İnanç Mendilcioğlu 11 Department of Obstetrics and Gynecology, Akdeniz University Faculty of Medicine, 07070 Antalya, Türkiye
Abstract
Large language models (LLMs), including ChatGPT, Gemini, Microsoft Copilot, and DeepSeek, are increasingly used to answer complex clinical questions. Their accessibility and rapid development suggest potential value in medical education, residency training, and point-of-care decision support. However, direct comparisons with obstetrics and gynecology trainees remain limited. To compare the accuracy of multiple free and subscription-based LLMs with that of obstetrics and gynecology resident physicians across specialty-specific domains.
A validated 40-item single-best-answer multiple-choice set covering endocrinology, gynecology, obstetrics, and oncology was developed by subspecialists and demonstrated good internal consistency (Cronbach’s alpha = 0.82). 25 residents completed the assessment. The same questions were posed to five LLMs: ChatGPT (GPT-4o Mini; free), ChatGPT (GPT-4o; subscription-based), Microsoft Copilot (GPT-4 based; free), DeepSeek (free), and Gemini (free).
Residents achieved a mean score of 20.6 out of 40 (51.5% correct). Overall accuracy was highest for ChatGPT (GPT-4o; subscription-based) at 90.0%, followed by DeepSeek and Gemini, each at 87.5%. ChatGPT (GPT-4o Mini; free) scored 47.5%, similar to residents, while Microsoft Copilot (free) scored 37.5%. In paired item-level comparisons using a two-sided exact McNemar test based on resident-majority item correctness (≥13/25 residents correct), ChatGPT (GPT-4o; subscription-based), DeepSeek, and Gemini significantly outperformed residents (all p < 0.001), whereas ChatGPT (GPT-4o Mini; free) and Microsoft Copilot did not differ significantly (p = 1.000 and p = 0.607, respectively). Domain-specific analyses showed that ChatGPT (GPT-4o; subscription-based), DeepSeek, and Gemini generally outperformed residents in gynecology, obstetrics, and oncology, with smaller and less consistent differences observed in endocrinology. Qualitative review of incorrect outputs noted occasional internally inconsistent or ambiguous responses.
Across a validated, curriculum-mapped 40-item question set, advanced LLMs achieved higher accuracy than residents, and in item-level paired comparisons using the resident-majority indicator, several models performed significantly better. Performance variability across models, including gaps between subscription-based and free versions and lower accuracy observed for some free tools, indicates that LLMs should complement, rather than replace, human expertise.
Keywords
- artificial intelligence (AI)
- large language models
- medical education
- clinical decision support
- obstetrics and gynecology
- resident physicians
Artificial intelligence (AI), particularly large language models (LLMs), has advanced rapidly in recent years, enabling novel applications across diverse areas of medicine [1, 2, 3]. These models can generate contextually relevant, human-like responses to complex clinical queries, and their accessibility, along with their ability to synthesize medical knowledge, highlights potential roles in medical education, residency training, and clinical decision-making [4, 5].
In obstetrics and gynecology, residency training demands mastery of a broad knowledge base spanning endocrinology, gynecology, obstetrics, and oncology. Traditional learning methods such as textbooks, lectures, and supervised clinical experience, remain essential but are often limited by time constraints and variability in clinical exposure [6]. AI-driven tools may supplement training by providing on-demand access to information, thereby supporting both didactic learning and clinical reasoning [7]. Despite this promise, the reliability and accuracy of LLMs in specialized medical fields remain uncertain. Prior studies evaluating LLM performance in general medicine and other specialties have reported mixed findings compared with physicians [8]. However, evidence in obstetrics and gynecology remains limited [9]. Moreover, potential differences between freely accessible and subscription-based AI models have not been systematically examined.
This study aimed to address these gaps by systematically evaluating and comparing the accuracy of several widely used LLMs with that of obstetrics and gynecology resident physicians across specialty-specific domains [10]. In doing so, we sought to clarify the strengths and limitations of current general-purpose LLMs in supporting medical education and to assess whether these models could serve as reliable adjuncts in residency training and clinical decision-making [11].
This cross-sectional knowledge assessment compared the performance of multiple LLMs with that of obstetrics and gynecology resident physicians on a specialty-specific multiple-choice examination.
25 obstetrics and gynecology residents from a single tertiary university hospital participated in this study. Responses were anonymized and analyzed in aggregate. Residents from the Akdeniz University Department of Obstetrics and Gynecology, across all postgraduate years, were eligible, and participants represented multiple training levels. Subgroup analyses by resident characteristics (e.g., sex or postgraduate year) were not prespecified in the study protocol and were therefore neither performed nor reported.
Five LLMs were evaluated: ChatGPT (GPT-4o Mini; free) and ChatGPT (GPT-4o; subscription-based) from OpenAI; Gemini (free; Google); DeepSeek (free); and Microsoft Copilot (free; GPT-4-based).
The resident examination had been administered previously as part of a routine educational assessment. Following Institutional Review Board (IRB) approval, the examination items were extracted, de-identified, and then entered into each LLM via its publicly available web-based user interface between 26 September 2025 and 30 September 2025. All systems were accessed via their standard publicly available web interfaces using default (free) configurations, except for ChatGPT, which was evaluated in both free and subscription versions.
For each item, the question stem and all five answer options were copied verbatim into a single prompt, and the model was instructed to select the single best answer. Both the resident assessment and all LLM prompts were administered in Turkish, with question stems and answer options entered exactly as written, without translation. Each item was run once per model using default web-interface settings (temperature not user-configurable). When models returned free-text outputs, the final selected option was coded as A, B, C, D, or E for analysis. Web browsing and external plugins were not used on any platform to standardize testing conditions and evaluate baseline performance.
The initial item pool consisted of 50 single best-answer questions constructed by subspecialty-trained obstetrics and gynecology faculty members to reflect core learning objectives from the national residency curriculum in endocrinology, gynecology, obstetrics, and gynecologic oncology. All items were drawn from our institution’s internal examination bank, which is not publicly available online or in commercial question resources. Therefore, this approach reduced, although it did not eliminate, the likelihood that the exact questions were encountered during LLM training. Each item included one correct answer and four distractors.
Before finalization, faculty members reviewed the stems, answer options, and keyed correct answers to ensure clarity and key accuracy. Items were excluded if they contained keying errors, ambiguous or internally inconsistent wording, multiple defensible answers, an unclear clinical context, or unacceptable psychometric properties on item analysis (for example, extreme floor or ceiling effects or negative discrimination). A biostatistician performed item analysis using residents’ responses to the initial 50-item pool, with a focus on item difficulty and discrimination. Items flagged as problematic (e.g., ambiguity, extreme difficulty, or negative discrimination) were removed during refinement. The final analyses and all LLM evaluations used the finalized 40-item set. 10 items were removed during this process. The final examination comprised 40 items and demonstrated good internal consistency (Cronbach’s alpha = 0.82). All analyses in this study are based on this 40-item set, and the same items were administered to both residents and LLMs.
Accuracy was defined as the proportion of correct responses within each group. For residents, overall accuracy was summarized as the mean number of correctly answered items across the 40 questions and expressed as a percentage. For each LLM, accuracy was defined as the percentage of correctly answered items out of 40.
For item-level paired comparisons between residents and each LLM, resident
performance was summarized at the item level using a majority vote. An item was
coded as correct for the resident group if at least 13 of 25 residents selected
the correct answer. For each model, paired 2
25 obstetrics and gynecology residents completed the 40-item multiple-choice examination spanning gynecology, obstetrics, endocrinology, and oncology. Internal consistency was high (Cronbach’s alpha = 0.82). Five LLMs were evaluated on the same item set. Overall accuracy varied across groups (Table 1). Residents achieved a mean score of 20.6 out of 40 (51.5% correct). Among the AI models, ChatGPT (GPT-4o; subscription-based) achieved the highest overall accuracy (36/40; 90.0%), followed by DeepSeek (35/40; 87.5%) and Gemini (35/40; 87.5%). ChatGPT (GPT-4o Mini; free) performed similarly to residents (19/40; 47.5%), whereas Microsoft Copilot (free) had the lowest overall accuracy (15/40; 37.5%). Corresponding 95% confidence intervals (CIs) are shown in Table 1.
| Model | Number of Questions | Mean correct (of 40) | Accuracy (%) | 95% CI (%) |
| Residents (n = 25) | 40 | 20.6 | 51.5% | [48.50–54.69] |
| ChatGPT (GPT-4o; subscription-based) | 40 | 36.0 | 90.0% | [76.95–96.04] |
| DeepSeek (free) | 40 | 35.0 | 87.5% | [73.89–94.54] |
| Gemini (free) | 40 | 35.0 | 87.5% | [73.89–94.54] |
| ChatGPT (GPT-4o Mini; free) | 40 | 19.0 | 47.5% | [32.94–62.50] |
| Microsoft Copilot (free) | 40 | 15.0 | 37.5% | [24.22–52.97] |
n = 40 items per group; 95% CIs are as percentages. 95% CIs were calculated
using the Wilson score method. For residents, the CI was computed from pooled
responses across all residents (25
Fig. 1 summarizes overall accuracy (percent correct) across residents and model configurations. Overall performance fell into three tiers. ChatGPT (GPT-4o; subscription-based) achieved the highest accuracy numerically (36/40; 90.0%), followed closely by DeepSeek and Gemini (35/40; 87.5% each). Residents and ChatGPT (GPT-4o Mini; free) showed intermediate, similar accuracy, whereas Microsoft Copilot (free) performed worst across the 40-item examination.
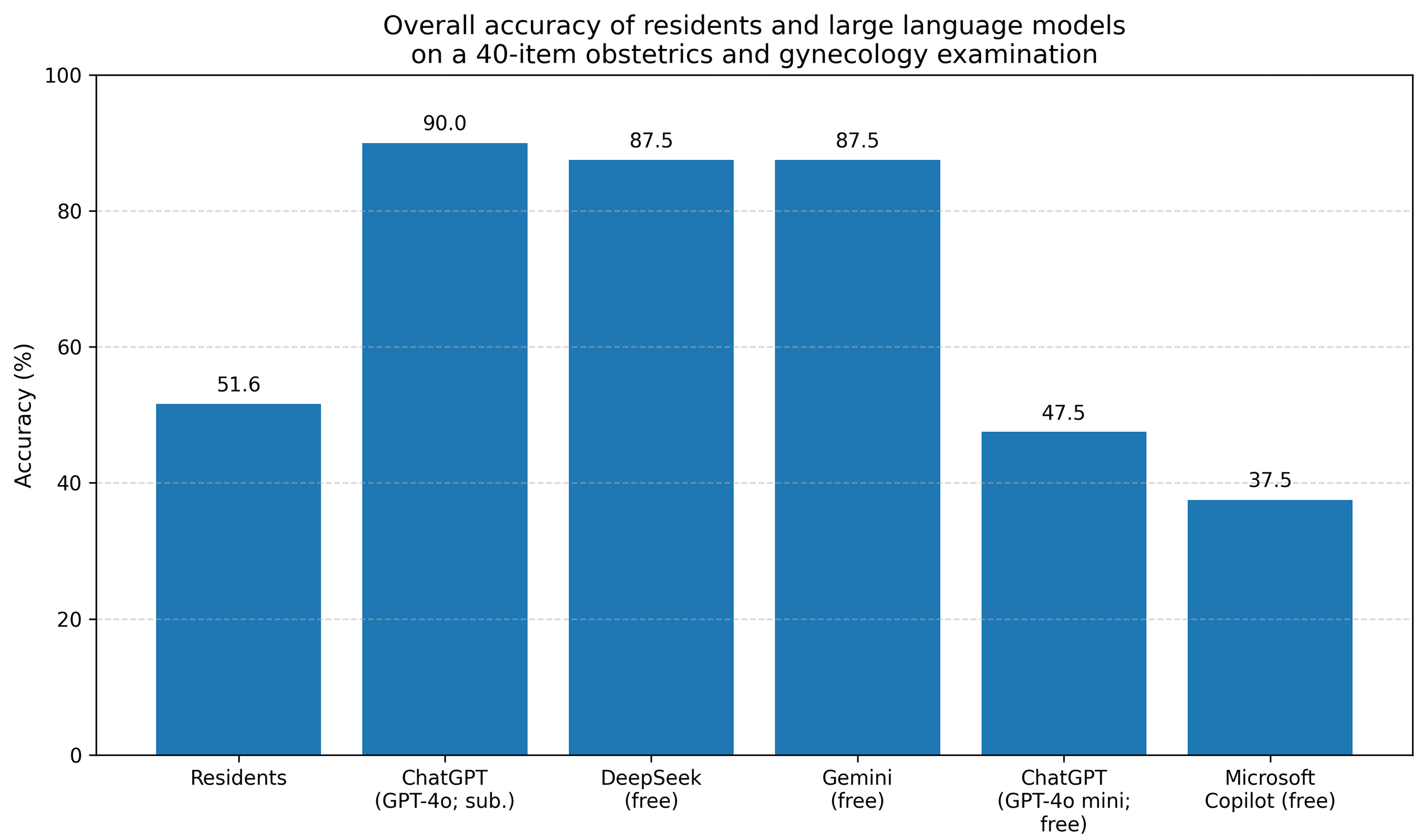 Fig. 1.
Fig. 1.
Overall accuracy across residents and LLM configurations. Bars
show the percentage of correctly answered items out of 40. Residents’ accuracy
reflects pooled performance across 25 residents (25
At the item level, the resident-majority was correct on 18/40 items (45.0%). In
paired item-level comparisons using the exact McNemar test (Table 2), ChatGPT
(GPT-4o; subscription-based) outperformed the resident-majority (36/40 vs. 18/40;
b = 21, c = 3; p
| Model | AI correct n (%) | Resident-majority correct n (%) | b (AI+/Res−) | c (AI−/Res+) | McNemar exact p (2-sided) |
| ChatGPT (GPT-4o; subscription-based) | 36 (90.0) | 18 (45.0) | 21 | 3 | |
| ChatGPT (GPT-4o Mini; free) | 19 (47.5) | 18 (45.0) | 9 | 8 | 1.000 |
| DeepSeek (free) | 35 (87.5) | 18 (45.0) | 19 | 2 | |
| Gemini (free) | 35 (87.5) | 18 (45.0) | 19 | 2 | |
| Microsoft Copilot (free) | 15 (37.5) | 18 (45.0) | 6 | 9 | 0.607 |
Resident-majority correct was defined as
Domain-specific analyses are summarized in Table 3. Given the small number of items in some subdomains (particularly endocrinology, n = 3), these domain-specific results are descriptive and provided for reference only; they should not be interpreted as statistically precise estimates. In endocrinology (3 items), residents attained 32.0% accuracy, whereas ChatGPT (GPT-4o; subscription-based), DeepSeek, and Gemini answered all items correctly (100.0% each). Both ChatGPT (GPT-4o Mini; free) and Microsoft Copilot (free) showed accuracies comparable to residents (33.3%). In gynecology (18 items), residents scored 51.1% on average, whereas ChatGPT (GPT-4o; 83.3%), DeepSeek (100.0%), and Gemini (94.4%) achieved substantially higher accuracy. ChatGPT (GPT-4o Mini) performed similarly to residents (55.6%), while Microsoft Copilot remained lower (38.9%). In obstetrics (9 items), residents achieved 64.0% accuracy, lower than ChatGPT (GPT-4o; 100.0%), DeepSeek (77.8%), and Gemini (88.9%). ChatGPT (GPT-4o Mini; 66.7%) and Microsoft Copilot (55.6%) demonstrated intermediate performance. In oncology (10 items), residents scored 47.2%, whereas ChatGPT (GPT-4o), DeepSeek, and Gemini reached 90.0%, 70.0%, and 70.0% accuracy, respectively. ChatGPT (GPT-4o Mini) and Microsoft Copilot performed worst in this domain (both 20.0%). CIs were wide in domains with few items, particularly endocrinology, reflecting limited precision for these estimates.
| Category | Model | Number of items | Mean | Accuracy (%) | 95% CI |
| Endocrinology | ChatGPT (GPT-4o Mini; free) | 3 | 1.0 | 33.3 | [6.15–79.23] |
| ChatGPT (GPT-4o; subscription-based) | 3 | 3.0 | 100.0 | [43.85–100.00] | |
| DeepSeek (free) | 3 | 3.0 | 100.0 | [43.85–100.00] | |
| Gemini (free) | 3 | 3.0 | 100.0 | [43.85–100.00] | |
| Microsoft Copilot (free) | 3 | 1.0 | 33.3 | [6.15–79.23] | |
| Residents | 3 | 1.0 | 32.0 | [22.54–43.21] | |
| Gynecology | ChatGPT (GPT-4o Mini; free) | 18 | 10.0 | 55.6 | [33.72–75.44] |
| ChatGPT (GPT-4o; subscription-based) | 18 | 15.0 | 83.3 | [60.78–94.16] | |
| DeepSeek (free) | 18 | 18.0 | 100.0 | [82.41–100.00] | |
| Gemini (free) | 18 | 17.0 | 94.4 | [74.24–99.01] | |
| Microsoft Copilot (free) | 18 | 7.0 | 38.9 | [20.30–61.38] | |
| Residents | 18 | 9.2 | 51.1 | [46.50–55.70] | |
| Obstetrics | ChatGPT (GPT-4o Mini; free) | 9 | 6.0 | 66.7 | [35.42–87.94] |
| ChatGPT (GPT-4o; subscription-based) | 9 | 9.0 | 100.0 | [70.08–100.00] | |
| DeepSeek (free) | 9 | 7.0 | 77.8 | [45.26–93.68] | |
| Gemini (free) | 9 | 8.0 | 88.9 | [56.50–98.01] | |
| Microsoft Copilot (free) | 9 | 5.0 | 55.6 | [26.66–81.12] | |
| Residents | 9 | 5.8 | 64.0 | [57.54–69.99] | |
| Oncology | ChatGPT (GPT-4o Mini; free) | 10 | 2.0 | 20.0 | [5.67–50.98] |
| ChatGPT (GPT-4o; subscription-based) | 10 | 9.0 | 90.0 | [59.58–98.21] | |
| DeepSeek (free) | 10 | 7.0 | 70.0 | [39.68–89.22] | |
| Gemini (free) | 10 | 7.0 | 70.0 | [39.68–89.22] | |
| Microsoft Copilot (free) | 10 | 2.0 | 20.0 | [5.67–50.98] | |
| Residents | 10 | 4.7 | 47.2 | [41.10–53.38] |
Endocrinology: n = 3 items; gynecology: n = 18; obstetrics: n = 9; oncology: n = 10; 95% CIs are percentages. Subdomain estimates, especially particularly endocrinology (n = 3 items), are descriptive and provided for reference only due to limited statistical precision.
Qualitative review (data not shown) noted that some incorrect model outputs were internally inconsistent or ambiguous, particularly for items with nuanced clinical framing. Among the reviewed resident errors (sampled), responses more often reflected incomplete or partially correct reasoning rather than consistent selection of a single incorrect option.
This study directly compared several LLMs with obstetrics and gynecology
residents using a specialty-specific multiple-choice examination, providing
domain-focused insights in this field. The primary finding was that an advanced
subscription-based model, ChatGPT (GPT-4o; subscription-based), along with two
free models, DeepSeek and Gemini, achieved substantially higher overall accuracy
than residents. In paired item-level comparisons using an exact McNemar framework
based on resident-majority item correctness, ChatGPT (GPT-4o;
subscription-based), DeepSeek, and Gemini also demonstrated significantly higher
item-level accuracy than the resident group (all p
Our findings are consistent with reports from other medical specialties in which state-of-the-art LLMs have achieved near-expert or superior performance on formal knowledge assessments [12]. The present study extends the literature by focusing on obstetrics and gynecology, a field that integrates cognitive, procedural, and guideline-driven decision-making and often relies on case-based reasoning. The high accuracy of ChatGPT (GPT-4o; subscription-based), DeepSeek, and Gemini across the 40-item examination, particularly in gynecology and oncology, suggests potential value as educational and decision-support adjuncts in women’s health. At the same time, the similar performance of ChatGPT (GPT-4o Mini; free) to residents, along with the lower overall accuracy observed for Microsoft Copilot, illustrates that performance is not uniform across commonly available LLM interfaces.
Our findings complement prior obstetrics and gynecology-focused LLM studies, including work using reflective writing tasks and vignette-based scenarios. Those studies primarily evaluated performance on narrative responses or simulated clinical cases under specific constraints, whereas we employed a standardized multiple-choice examination mapped to the national residency curriculum. By directly comparing several free and subscription-based models with residents on the same specialty-specific examination, our study provides a multi-model, exam-based perspective that aligns with formal assessment settings while remaining distinct from vignette- and portfolio-based evaluations. Our multiple-choice, curriculum-mapped examination design complements prior vignette-based studies by assessing core knowledge performance under standardized inputs.
From a clinical and educational perspective, these results suggest several possible applications. High-performing models may serve as adjunctive study aids by providing immediate feedback on practice questions, generating explanations, and supporting guideline review. However, the observed variability among models, including differences between subscription-based and free systems, underscores that recommendations for LLM use should be model-specific and supported by ongoing validation [13, 14, 15, 16]. Careful model selection will therefore be essential if training programs consider integrating LLMs into curricula or clinical decision-support workflows. Our findings should be interpreted as supporting adjunct use rather than replacement. LLMs may complement trainees by providing explanations and highlighting guideline-based concepts, but clinically actionable outputs must be verified against authoritative references and interpreted under faculty or clinician supervision. In clinical settings, LLM use should adhere to local governance policies, with verification of high-stakes recommendations documented and accountability clearly retained by the supervising clinician.
When an LLM output references a study, guideline, or specific evidence, learners should treat the response as a preliminary aid and verify key claims in the primary source. If the model’s recommendation conflicts with established references or supervisor instruction, the appropriate course of action is to prioritize authoritative guidance, cross-check the cited source, and consult faculty or senior clinicians. This verification step is particularly important for clinically actionable content, as unverified outputs should not guide patient care. In practice, training programs should implement clear guardrails for LLM use, including reference standards and escalation pathways when outputs are uncertain or conflict with established guidance. Ongoing validation should be coordinated at the institutional level by residency program leadership and clinical governance structures, with guidance informed by specialty societies as models evolve.
The use of an exact McNemar test reflects the paired structure of the data at the item level. Each examination item was answered by both the resident cohort and by each model, enabling item-level comparisons that partially control for item difficulty. Nevertheless, this approach summarizes resident performance using a group-level majority-vote indicator and does not fully account for within-resident and within-item correlation structures. More complex approaches, such as mixed-effects models, could be considered in future studies, particularly in larger, multi-institutional cohorts.
A descriptive review of incorrect model outputs suggested that some responses were internally inconsistent or ambiguous, particularly for items with nuanced clinical framing. Because this review was not a formal safety assessment and did not quantify “clinically unsafe” outputs using predefined criteria and independent raters, conclusions regarding comparative safety across models cannot be drawn from this study. Future studies should classify incorrect outputs using predefined, safety-focused error categories and independent clinician raters. More broadly, concerns have been raised that LLMs may provide incorrect answers with high confidence, reinforcing the need for critical appraisal and oversight [14, 17]. These observations support the broader view that LLM outputs should be interpreted critically and used with appropriate clinician oversight, particularly when applied outside educational contexts [17].
This study has several strengths, including a specialty-specific examination developed by domain experts, high internal consistency, direct comparisons across multiple LLMs and residents, and transparent item-level paired analyses.
This study provides empirical data on the performance of general-purpose LLMs compared with obstetrics and gynecology residents on standardized clinical questions. By characterizing accuracy and the nature of incorrect outputs, it informs educators and health system leaders about the realistic capabilities and limitations of current models. These findings can guide the safe integration of AI tools into postgraduate training and clinical decision-support workflows, while emphasizing the continued need for clinician oversight.
Nevertheless, several limitations should be acknowledged. First, the sample was limited to 25 residents from a single institution, which may restrict generalizability and might not capture heterogeneity across postgraduate years. Accordingly, external validity may be limited, and multi-institutional studies with larger, more diverse resident cohorts are needed to replicate these findings. Second, the assessment focused on multiple-choice questions rather than on open-ended reasoning, communication skills, or real-time patient management. Third, some domains, particularly endocrinology, were represented by few items, resulting in wide CIs and reduced precision in domain-specific estimates. Fourth, each model was evaluated using a single prompt format and a single run per item, and LLMs are updated frequently; performance may therefore differ with alternative prompts, settings, or future model versions. Although web-browsing or search features were not enabled or intentionally used, we cannot fully exclude the possibility of proprietary, platform-level retrieval in some interfaces; this should be considered when interpreting results. Finally, we did not evaluate usability, explanation quality, or patient-level outcomes. Taken together, these limitations indicate that our findings should be interpreted as reflecting performance on a structured knowledge test rather than as evidence of real-world clinical effectiveness.
Advanced LLM configurations, including ChatGPT (GPT-4o; subscription-based), DeepSeek, and Gemini, achieved higher accuracy than residents on this specialty-specific multiple-choice examination and outperformed the resident-majority indicator in paired item-level comparisons. These findings support the potential role of LLMs as supplementary educational tools and adjuncts for structured information support in women’s health. Importantly, performance was not uniform across models. ChatGPT (GPT-4o Mini; free) did not differ significantly from residents, and Microsoft Copilot showed lower overall accuracy but did not differ significantly from residents in paired item-level comparisons. Taken together, these results support the use of LLMs as adjuncts rather than replacements for human expertise and emphasize the importance of careful model selection, ongoing validation, and responsible integration with clinician oversight [17].
The datasets generated and analyzed during this study are available from the corresponding author upon reasonable request. Due to institutional privacy policies, de-identified datasets are not publicly available.
ÖFÖ and CD conceptualized the study and designed the question set. EŞ, SD, and NUD contributed to data collection and analysis. MÖ and İM made substantial contributions to the interpretation of data, academic supervision, and critical revision of the manuscript for important intellectual content. All authors contributed to editorial changes in the manuscript. All authors read and approved the final manuscript. All authors have participated sufficiently in the work and agreed to be accountable for all aspects of the work.
The study was conducted in accordance with the Declaration of Helsinki and approved by the Akdeniz University Faculty of Medicine Clinical Research Ethics Committee (approval number: TBAEK-863). Written informed consent was obtained from all participants prior to inclusion in the study.
The authors thank all resident physicians from Akdeniz University Faculty of Medicine, Department of Obstetrics and Gynecology, for their participation in this study. We also appreciate the contributions of the department’s academic staff in reviewing the question bank.
This research received no external funding.
The authors declare that they have no conflicts of interest in the research. All figures and tables are original and were created by the authors for this manuscript; no permissions were required.
During the preparation of this work the authors used ChatGPT for language editing (spelling/grammar) and clarity improvement. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
References
Publisher’s Note: IMR Press stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.